pytorch入门(三)卷积神经网络
pytorch入门(三)卷积神经网络
- 建立CNN网络进行训练
-
- 定义网络
-
- nn.Conv2d
- Pooling
- Dropout
- nn.Sequential()
- 训练结果
- 历史上的CNN模型
-
- LeNet-5
- AlexNet
- Inception/GoogLeNet
-
- VGG
- ResNet
- 其他结构
- 利用预训练模型
-
- 例子
- batch normalization
- 模型选择
建立CNN网络进行训练
定义网络
nn.Conv2d
nn.Conv2d(in_channels,out_channels, kernel_size, stride, padding)
- in_channels表示输入通道,这里就是(36464)
- out_channels表示输出通道数量
- kernel_size表示卷积核大小
- stride表示每次滑动步长
- padding表示边缘填充长度,如果不赋值那么如果出现边缘没有足够数量元素进行卷积,这一个部分则会被丢弃。
卷积输出大小公式:
W 2 = W 1 − F + 2 P S + 1 W_2=\frac{W_1-F+2P}{S}\quad+1 W2=SW1−F+2P+1
W:宽 F:卷积核大小 S:步长 P:padding
除不尽取整数。
Pooling
pooling结合卷积层有效减少参数并加快收敛速度。
这里我们用的时maxpooling。pytorch同样包含average pooling。
Dropout
其使得网络在训练时随机drop掉一些神经元不参与训练。
nn.Sequential()
通过nn.Sequential()可以定义一个层链。可以将网络分解成更有逻辑的排列。
这里我们将设置一个特征提取层和分类层。
按照输入图片格式为:64*64,batchsize=64为例.
class CNNNet(nn.Module):
def __init__(self, num_classes=2):
super(CNNNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), # 输出:通道数:64 输出大小:15
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2), # 输出:通道数:64,输出大小:7
nn.Conv2d(64, 192, kernel_size=5, padding=2), # 输出: 通道数:192,输出大小:7
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2), # 输出: 通道数:192,输出大小:3
nn.Conv2d(192, 384, kernel_size=3, padding=1), # 输出: 通道数:384,输出大小:3
nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), # 输出: 通道数:256,输出大小:3
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, padding=1), # 输出: 通道数:256,输出大小:3
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2), # 输出: 通道数:256,输出大小:1 // batch_size = 64, channel = 265 outsize:1,1
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) # 输出:256*6*6
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x) # 64,256,6,6
x = torch.flatten(x, 1) # 64,9216
x = self.classifier(x)
return x
以下是完整代码。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from PIL import Image
# 定义神经网络
class net(nn.Module):
def __init__(self):
super(net, self).__init__()
self.fc1 = nn.Linear(12288, 84) # 64*64*3
self.fc2 = nn.Linear(84, 30)
self.fc3 = nn.Linear(30, 84)
self.fc4 = nn.Linear(84, 2)
def forward(self, x):
x = x.view(-1, 12288)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
# convnet
class CNNNet(nn.Module):
def __init__(self, num_classes=2):
super(CNNNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), # 输出:通道数:64 输出大小:15
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2), # 输出:通道数:64,输出大小:7
nn.Conv2d(64, 192, kernel_size=5, padding=2), # 输出: 通道数:192,输出大小:7
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2), # 输出: 通道数:192,输出大小:3
nn.Conv2d(192, 384, kernel_size=3, padding=1), # 输出: 通道数:384,输出大小:3
nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), # 输出: 通道数:256,输出大小:3
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, padding=1), # 输出: 通道数:256,输出大小:3
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2), # 输出: 通道数:256,输出大小:1 // batch_size = 64, channel = 265 outsize:1,1
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) # 输出:256*6*6
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x) # 64,256,6,6
x = torch.flatten(x, 1) # 64,9216
x = self.classifier(x)
return x
cnnnet = CNNNet()
def train(model, optimizer, loss_fn, train_loader, val_loader, epochs=20, device="cpu"):
for epoch in range(epochs):
training_loss = 0.0
valid_loss = 0.0
model.train()
for batch in train_loader:
optimizer.zero_grad()
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
output = model(inputs)
loss = loss_fn(output, targets)
loss.backward()
optimizer.step()
training_loss += loss.data.item() * inputs.size(0)
training_loss /= len(train_loader.dataset)
model.eval()
num_correct = 0
num_examples = 0
for batch in val_loader:
inputs, targets = batch
inputs = inputs.to(device)
output = model(inputs)
targets = targets.to(device)
loss = loss_fn(output, targets)
valid_loss += loss.data.item() * inputs.size(0)
correct = torch.eq(torch.max(F.softmax(output), dim=1)[1], targets).view(-1)
num_correct += torch.sum(correct).item()
num_examples += correct.shape[0]
valid_loss /= len(val_loader.dataset)
print(
'Epoch: {}, Training Loss: {:.2f}, Validation Loss: {:.2f}, accuracy = {:.2f}'.format(epoch, training_loss,
valid_loss,
num_correct / num_examples))
def check_image(path):
try:
im = Image.open(path)
return True
except:
return False
img_transforms = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
train_data_path = "./train/"
train_data = torchvision.datasets.ImageFolder(root=train_data_path, transform=img_transforms, is_valid_file=check_image)
val_data_path = "./val/"
val_data = torchvision.datasets.ImageFolder(root=val_data_path, transform=img_transforms, is_valid_file=check_image)
batch_size = 64
train_data_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True)
val_data_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, shuffle=True)
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
cnnnet.to(device)
optimizer = optim.Adam(cnnnet.parameters(), lr=0.001)
train(cnnnet, optimizer, torch.nn.CrossEntropyLoss(), train_data_loader, val_data_loader, epochs=40, device=device)
训练结果
Epoch: 0, Training Loss: 0.33, Validation Loss: 0.41, accuracy = 0.76
Epoch: 1, Training Loss: 0.40, Validation Loss: 0.38, accuracy = 0.82
Epoch: 2, Training Loss: 0.34, Validation Loss: 0.43, accuracy = 0.78
Epoch: 3, Training Loss: 0.28, Validation Loss: 0.44, accuracy = 0.76
Epoch: 4, Training Loss: 0.33, Validation Loss: 0.45, accuracy = 0.84
Epoch: 5, Training Loss: 0.31, Validation Loss: 0.41, accuracy = 0.84
Epoch: 6, Training Loss: 0.24, Validation Loss: 0.42, accuracy = 0.83
Epoch: 7, Training Loss: 0.24, Validation Loss: 0.39, accuracy = 0.82
Epoch: 8, Training Loss: 0.22, Validation Loss: 0.50, accuracy = 0.84
Epoch: 9, Training Loss: 0.22, Validation Loss: 0.73, accuracy = 0.69
Epoch: 10, Training Loss: 0.26, Validation Loss: 0.48, accuracy = 0.78
Epoch: 11, Training Loss: 0.19, Validation Loss: 0.80, accuracy = 0.79
Epoch: 12, Training Loss: 0.19, Validation Loss: 0.50, accuracy = 0.81
Epoch: 13, Training Loss: 0.15, Validation Loss: 0.72, accuracy = 0.76
Epoch: 14, Training Loss: 0.15, Validation Loss: 0.72, accuracy = 0.80
Epoch: 15, Training Loss: 0.22, Validation Loss: 0.40, accuracy = 0.81
Epoch: 16, Training Loss: 0.20, Validation Loss: 0.72, accuracy = 0.78
Epoch: 17, Training Loss: 0.11, Validation Loss: 0.86, accuracy = 0.83
Epoch: 18, Training Loss: 0.09, Validation Loss: 1.20, accuracy = 0.77
Epoch: 19, Training Loss: 0.09, Validation Loss: 0.87, accuracy = 0.76
Epoch: 20, Training Loss: 0.09, Validation Loss: 0.90, accuracy = 0.84
Epoch: 21, Training Loss: 0.14, Validation Loss: 0.75, accuracy = 0.81
Epoch: 22, Training Loss: 0.09, Validation Loss: 1.06, accuracy = 0.83
Epoch: 23, Training Loss: 0.09, Validation Loss: 0.95, accuracy = 0.83
Epoch: 24, Training Loss: 0.13, Validation Loss: 0.70, accuracy = 0.83
Epoch: 25, Training Loss: 0.08, Validation Loss: 1.14, accuracy = 0.74
Epoch: 26, Training Loss: 0.08, Validation Loss: 0.77, accuracy = 0.81
Epoch: 27, Training Loss: 0.03, Validation Loss: 1.45, accuracy = 0.85
Epoch: 28, Training Loss: 0.09, Validation Loss: 1.16, accuracy = 0.79
Epoch: 29, Training Loss: 0.10, Validation Loss: 0.94, accuracy = 0.85
Epoch: 30, Training Loss: 0.08, Validation Loss: 0.78, accuracy = 0.85
Epoch: 31, Training Loss: 0.08, Validation Loss: 0.78, accuracy = 0.83
Epoch: 32, Training Loss: 0.03, Validation Loss: 2.64, accuracy = 0.72
Epoch: 33, Training Loss: 0.24, Validation Loss: 0.38, accuracy = 0.86
Epoch: 34, Training Loss: 0.17, Validation Loss: 0.89, accuracy = 0.81
Epoch: 35, Training Loss: 0.05, Validation Loss: 1.04, accuracy = 0.83
Epoch: 36, Training Loss: 0.04, Validation Loss: 1.08, accuracy = 0.83
Epoch: 37, Training Loss: 0.02, Validation Loss: 1.49, accuracy = 0.83
Epoch: 38, Training Loss: 0.06, Validation Loss: 0.80, accuracy = 0.82
Epoch: 39, Training Loss: 0.07, Validation Loss: 1.55, accuracy = 0.76
历史上的CNN模型
LeNet-5
最早在1990年提出了LeNet-5.
AlexNet
2012年发布了AlexNet在当年的ImageNet竞赛中top-5错误率为15.3%。排第一。

其最早引入maxpool和dropout,并推广了ReLU激活函数。同样其证明了深度学习是有效的。其也成为了深度学习历史上的里程碑。
Inception/GoogLeNet
这是2014年ImageNet竞赛的冠军。其解决了AlexNet的一些缺陷。
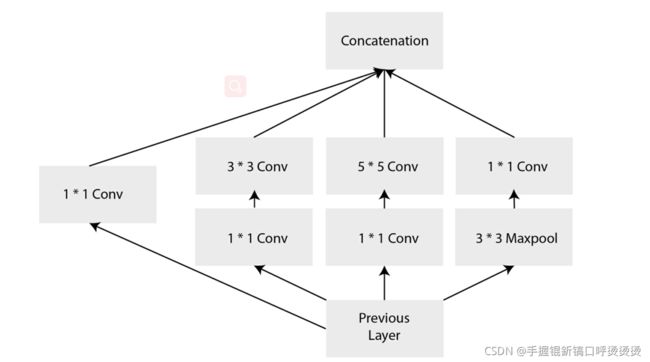
其结构如图。该网络使用不同的卷积核提取不同的特征然后并行输出。其总参数比较AlexNet较小并且top-5错误率达到了6.67%。
VGG
14年ImageNet第二名是牛津大学提出的the Visual Geometry Group (VGG) 网络。其通过一个多层卷积实现了简单结构深层化并取得很好的效果。top-5错误率达到了8.8%。
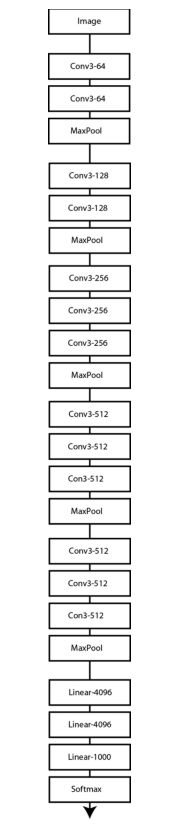
其缺点为其最终的全连接层使得网络参数巨大。与GoogleNet得700万参数相比这个有1.38亿个。
因为其简单的结构也被很多人喜爱。其结构也在风格转换中被使用(比如将一张照片转变为梵高的图像)
ResNet
2015年微软得ResNet以4.49%得top-5错误率和ResNet变体得3.57%错误率获得第一。(基本超越人类)
其创新点在于执行CNN普通模块时,也将输入添加到输出模块中。如下图所示。
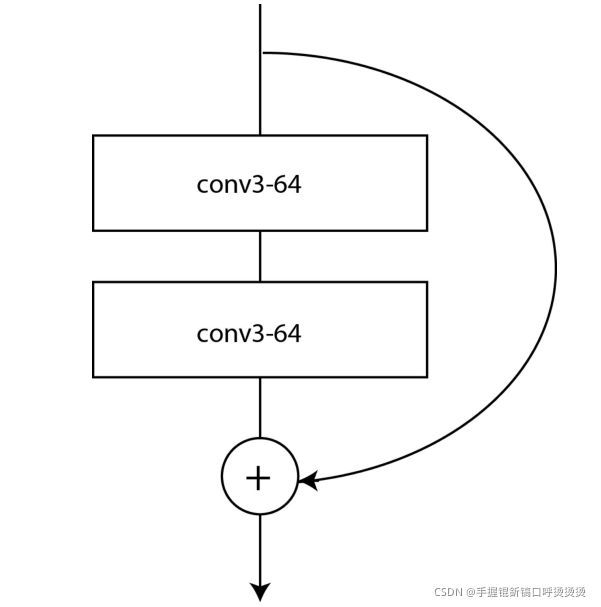
这种模式有效解决了梯度消失的问题。
其他结构
15年之后,其他大量体系提高了ImageNet准确度。比如DenseNet(借鉴了ResNet结构可以构建1000层网络),SqueezeNet和MobileNet这两种网络提供了合理的精确度,但与VGG、ResNet或Inception等体系结构相比,它的精确度很低。
谷歌利用AutoMl系统自行设计了NASNet获得了sota的成绩。
利用预训练模型
比如本次任务调用AlexNet。
import torchvision.models as models
alexnet = models.alexnet(num_classes=2)
同样该api也提供了VGG、ResNet、Inception、DenseNet和SqueezeNet变体的定义。如果调用
models.alexnet(pretrained=True)
可以获得一组已训练好的参数。
例子
import torchvision.models as models
alexnet = models.alexnet(num_classes=1000, pretrained=True)
先下载预训练模型。
![]()
输出模型结构。
print(alexnet)
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
下载resnet并输出:
resnet = models.resnet18(pretrained=True)
print(resnet)
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
batch normalization
缩写BN,BN层拥有两个参数并参与网络训练其使命是将通过该层batch_size的样本归一化(平均值为0,方差为1).BN层对于小型网络的影响比较小。但对于大型网络比如超过20层的网络每一层之间相乘都会产生较大影响,最终导致梯度消失或者爆炸。
BN层的使用也使得像ResNet-152的梯度不会爆炸或者消失。
在之前的例子中图像输入时,我们发现会进行一个normalization,但如果不进行这样的处理其实也能训练。不过训练时间较长并且最终的BN层通过训练对输入样本进行自动normalization。
模型选择
书中建议尝试NASNet和PNAS(但书中又不完全推荐- -)因为他们非常消耗内存。这和第四章中提到的迁移学习与一些人工设计的结构如ResNet相比会显得效率没有那么高。
同样可以利用torch.hub.list('pytorch/vision:v0.4.2')查看所有能够下载的模型。
比如:
['alexnet', 'deeplabv3_resnet101', 'densenet121', 'densenet161', 'densenet169', 'densenet201', 'fcn_resnet101', 'googlenet', 'inception_v3', 'mobilenet_v2', 'resnet101', 'resnet152', 'resnet18', 'resnet34', 'resnet50', 'resnext101_32x8d', 'resnext50_32x4d', 'shufflenet_v2_x0_5', 'shufflenet_v2_x1_0', 'squeezenet1_0', 'squeezenet1_1', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'wide_resnet101_2', 'wide_resnet50_2']
model = torch.hub.load('pytorch/vision:v0.4.2', 'resnet50', pretrained=True)