《动手学深度学习》课后习题1
《动手学》:线性回归
**1.**假如你正在实现一个全连接层,全连接层的输入形状是7×8,输出形状是7 ×1,其中7是批量大小,则权重参数w和偏置参数b的形状分别是____和____
答案:8×1,1×1
2. 课程中的损失函数定义为:
def squared_loss(y_hat, y):
return (y_hat - y.view(y_hat.size())) ** 2 / 2
将返回结果替换为下面的哪一个会导致会导致模型无法训练:(阅读材料:https://pytorch.org/docs/stable/notes/broadcasting.html)
答案: (y_hat - y.view(-1)) ** 2 / 2
解析:y_hat的形状是[n, 1],而y的形状是[n],两者相减得到的结果的形状是[n, n],相当于用y_hat的每一个元素分别减去y的所有元素,所以无法得到正确的损失值。对于第一个选项,y_hat.view(-1)的形状是[n],与y一致,可以相减;对于第二个选项,y.view(-1)的形状仍是[n],所以没有解决问题;对于第三个选项和第四个选项,y.view(y_hat.shape)和y.view(-1, 1)的形状都是[n, 1],与y_hat一致,可以相减。以下是一段示例代码:
x = torch.arange(3)
y = torch.arange(3).view(3, 1)
print(x)
print(y)
print(x + y)
3. 在线性回归模型中,对于某个大小为3的批量,标签的预测值和真实值如下表所示:
| y^ | y |
|---|---|
| 2.33 | 3.14 |
| 1.07 | 0.98 |
| 1.23 | 1.32 |
该批量的损失函数的平均值为:(参考“线性回归模型从零开始的实现”中的“定义损失函数”一节,结果保留三位小数)
答案:0.112

《动手学》:Softmax与分类模型
4. softmax([100, 101, 102])的结果等于以下的哪一项
答案:softmax([-2 -1, 0])
5. 对于本节课的模型,在刚开始训练时,训练数据集上的准确率低于测试数据集上的准确率,原因是
答案:训练集上的准确率是在一个epoch的过程中计算得到的,测试集上的准确率是在一个epoch结束后计算得到的,后者的模型参数更优。
《动手学》:多层感知机
6. 关于激活函数,以下说法中错误的是
答案:B.tanh可以由sigmoid平移伸缩得到,所以两者没有区别。
A 在多层感知机中引入激活函数的原因是,将多个无激活函数的线性层叠加起来,其表达能力与单个线性层相同。C 相较于sigmoid和tanh,Relu的主要优势是计算效率高且不会出现梯度消失问题;D 如果我们需要网络输出范围是[0, 1][0,1],可以考虑使用sigmoid函数
7. 对于只含有一个隐藏层的多层感知机,输入是256 ×256的图片,隐藏单元个数是1000,输出类别个数是10,则模型的所有权重矩阵
![]()
答案:65546000
《动手学》:文本预处理
8. 下列哪一项不是构建Vocab类所必须的步骤:
答案:句子长度统计。
解析:句子长度统计与构建字典无关。
A 词频统计,清洗低频词;C 构建索引到token的映射;D 构建token到索引的映射
9. 无论use_special_token参数是否为真,都会使用的特殊token是____,作用是用来____。
答案:,表示未登录词
《动手学》:语言模型
10. 下列关于n元语法模型的描述中错误的是:
答案:马尔科夫假设是指各个词的出现是相互独立的,要预测下一个词首先需要计算这个词之前全部文本序列出现的概率。
解析:D 如果使用nn元语法模型存在数据稀疏问题,最终计算出来的大部分参数都是0。

11. 
12. 下列关于随机采样的描述中错误的是:
答案:每个小批量包含的样本数是batch_size,每个样本的长度为num_steps。
解析:随机采样中前后批量中的数据是不连续的。A 训练数据中的每个字符最多可以出现在一个样本中; C 在一个样本中,前后字符是连续的 ; D 前一个小批量数据和后一个小批量数据是连续的.
13. 给定训练数据[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10],批量大小为batch_size=2,时间步数为2,使用本节课的实现方法进行相邻采样,第二个批量为:
答案:[2, 3]和[7, 8]
解析:因为训练数据中总共有11个样本,而批量大小为2,所以数据集会被拆分成2段,每段包含5个样本:[0, 1, 2, 3, 4]和[5, 6, 7, 8, 9],而时间步数为2,所以第二个批量为[2, 3]和[7, 8]。
《动手学》:循环神经网络基础
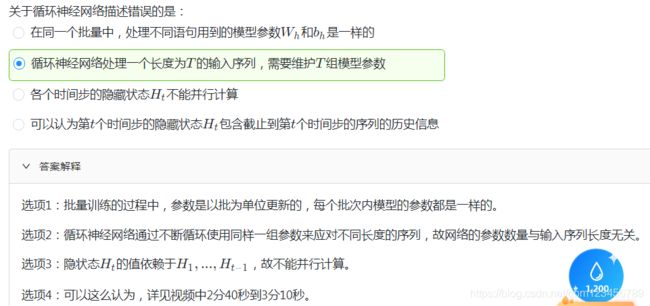
14. 
15. 关于梯度裁剪描述错误的是:
答案:梯度裁剪也是应对梯度消失的一种方法。
解析:梯度裁剪只能对应梯度爆炸。A 梯度裁剪之后的梯度小于或者等于原梯度 ;B 梯度裁剪是应对梯度爆炸的一种方法;C 裁剪之后的梯度L2范数小于阈值θ
16. 关于困惑度的描述错误的是:
答案:有效模型的困惑度应该大于类别个数。
解析:一个随机分类模型(基线模型)的困惑度等于分类问题的类别个数,有效模型的困惑度应小于类别个数。A 困惑度用来评价语言模型的好坏; B 困惑度越低语言模型越好。
17. 关于采样方法和隐藏状态初始化的描述错误的是:
答案:采用随机采样需要在每个小批量更新前初始化隐藏状态是因为每个样本包含完整的时间序列信息。
解析:随机采样中每个样本只包含局部的时间序列信息,因为样本不完整所以每个批量需要重新初始化隐藏状态。A 采用的采样方法不同会导致隐藏状态初始化方式发生变化; B 采用相邻采样仅在每个训练周期开始的时候初始化隐藏状态是因为相邻的两个批量在原始数据上是连续的。
- 第一次打卡:以下为学习记录:

- 最后特别感谢Datawale、伯禹学习平台。