Wikidata知识图谱介绍与数据处理
1. Wikidata简介
Wikidata(维基数据)是一个自由开放的知识库,可以同时被人和机器阅读、编辑[1]。根据官网介绍,Wikidata作为一种结构化数据的集中存储,为其他维基媒体(Wikimedia)项目[2]提供支撑,包括Wikipedia(维基百科)、Wikivoyage(维基导游)、Wiktionary(维基字典)、Wikisource(维基文库)等。
就像维基百科一样,Wikidata 支持自由协作编辑,支持多语言。与维基百科不同的是,Wikidata作为知识库,其内容都是结构化的信息,它期望将维基百科、维基文库、维基导游等项目中结构化知识进行抽取、存储、关联。
Wikidata提供了全量数据和增量数据下载[3],其中latest-all.* 就是全量数据文件,包括JSON、nt和ttl三种格式。本文以JSON数据格式为例进行分析,对于nt和ttl可分别参考https://en.wikipedia.org/wiki/N-Triples和https://en.wikipedia.org/wiki/Turtle_(syntax)。增量文件在对应的日期文件夹中,文件名形如“wikidata-20210915-lexemes.json”。每个数据文件都提供了bz2和gz两种压缩格式,其中bz2格式的压缩更紧凑、文件更小。
目前国内网络无法直接访问Wikidata官网,这个大家都有办法。本人于2020年11月左右下载了一次gz压缩格式的全量数据文件,大小约90GB,包含条目约9200万。目前,最新的全量文件gz格式约为100GB,包含大约9500万条目,文件大小在不到一年时间增长了10G,可见数据增长非常快。
2. Wikidata数据模型
说明:本章内容主要参考 https://www.mediawiki.org/wiki/Wikibase/DataModel。
Wikidata知识图谱模型,采用了经典的面向对象进行数据模型设计。就像Python中所有对象都继承自object,Wikidata知识图谱中所有知识元素的顶层是Value对象。所有Value对象被划分为DataValue和Entity两类,Entity又分为Datatype、Item和Property,结构如下图所示:
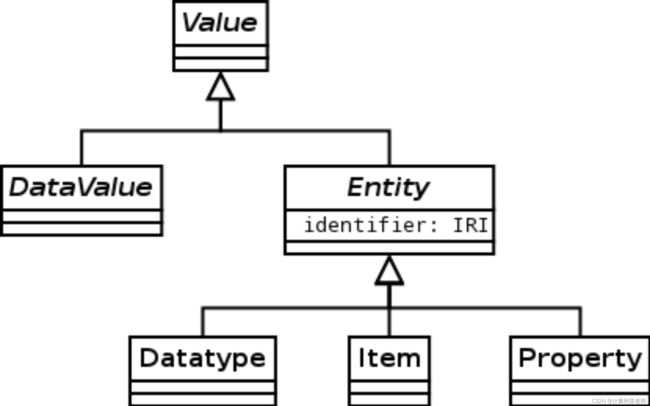
其中Item可以对应到我们通常说的实体,包括各类概念和实例,例如人、机构、国家、事件等等。Property是实体属性,和一般的知识图谱不同,Wikidata的Property包括了属性和关系,例如可以是出生日期、国籍、性别这种属性,也可以是朋友、工作单位这种关系,因为它们其实没有本质的区别。
Item和Property构成了Wikidata知识模型最核心的概念。Datatype和DataValue则是知识图谱细化到数据层面的概念,例如串值、数量值、时间值、单语文本值、多语文本值,具体类型如下图所示。
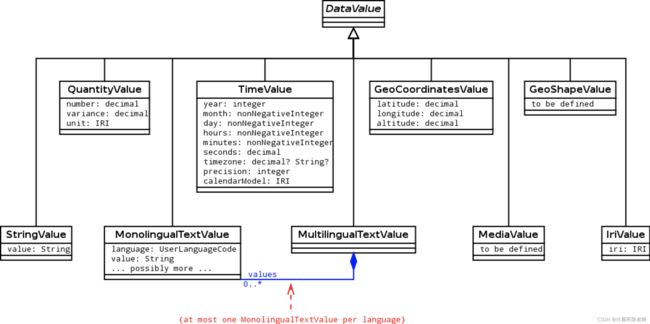
关于数据类型和数据值,一般来说不在知识图谱的对象范畴内,但是当描述对象的属性时,最后总是会到数据值,这本质上是因为只有数据值才能够计算机自动处理。从知识图谱的概念视图上看,把数据类型作为一种概念、数据值作为相应数据类型概念的实例,是跟整体概念层-实例层结构是一致的。但在实际应用中却有不同的技术实践,例如在Python中所有对象都继承自object,包括字符串(str)、整数(int)、小数(float)等数据类型,通过Python内置的“isinstance”函数很容易验证。在Java语言中,对基本类型(称为Primitive Types)和对象类型(Object Types)进行了明确的区分,基本类型对应了字面值,例如“true”、“1”、“1.2F”,“100.23D”,它们只有一套语言内定义的操作(例如整数可以进行加、减、乘、除),没有方法,也不是某个对象类型的实例,与Object类型体系没有直接联系。那么为什么会有这种区别?效率原因!几乎所有以效率著称的语言都是具备编译型、强类型、区分简单类型等特点,C、C++、Java、Go都是这样的。
因为灵活性和开发效率,Python选择了脚本化、弱类型、统一类型体系。知识图谱系统更加面向业务,对复杂业务的支撑能力、架构的可扩展性、业务灵活性等特性更为重要,通常要求设计统一的知识体系。
3. Wikidata数据格式
本章内容主要参考https://doc.wikimedia.org/Wikibase/master/php/md_docs_topics_json.html。
从Wikidata官网下载的JSON格式的数据,JSON对象顶层结构包括id、type、labels、descriptions、aliases、claims等字段,如下图[4]所示:
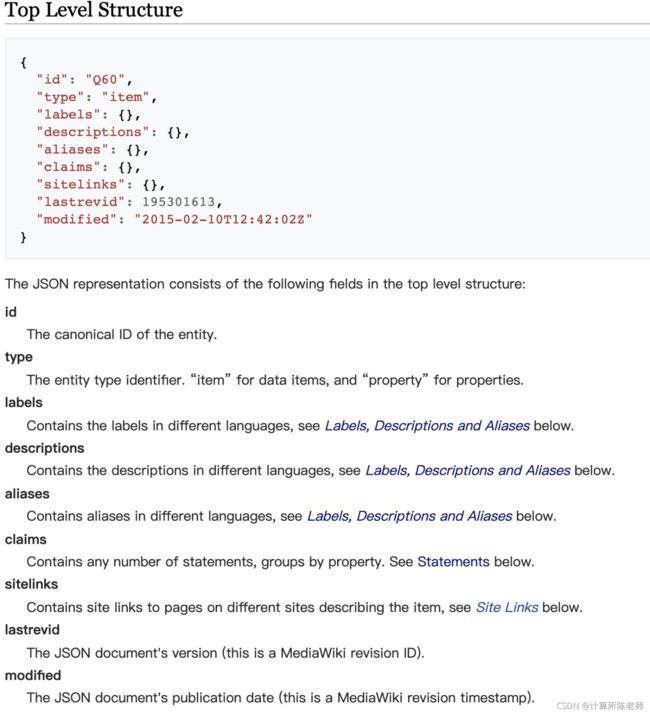
引用网页中有完整的结构描述,对于结构内容,举例如下图所示:

在示例中,“Q42”是这个Item的ID,它的label为“Douglas Adams”,通过description可以看出这是一个英文作家和滑稽演员,具有“Douglas Noel Adams”这个别名,以及较为复杂的是,具有一些Statement,就是这个Item具有的Property。Statement在JSON其实是claims字段的下层结构。完整的逻辑结构[5]如下:
这里有几个关键信息:
- Item和Property结构基本一致,除了Item具有Site links(站点链接),而Property则具有一个Datatype字段,表明该属性的数据类型。
- Item的ID以Q开头,Property的ID以P开头。由于给每个实体赋予了唯一ID,因此经常用于实体链接、知识融合。在业务系统中,可以扩展这个规则,用于其他的标识,例如使用NL开头的标识表示未链接成功的实体,以S开头的标识标识自定义属性等。
- 多语言的label、description和aliases共同组成Item或Property的指纹。何为指纹?具备一定区分属性的信息,尽管可能存在重复。这里很关键的一点就是,Wikidata是通过在相同语言中的label和description进行唯一标识的。label是显示出来的名称,例如人的姓名,由于经常出现重复,因此label本身不能作为实体的唯一标识,通过组合上description就能够区分,例如“Trump”-“美国第45届总统”、“Trump”-“家族名”。
- 属性信息称为Claim,具体包括属性、属性值和限定符。为什么叫Claim?Wikidata认为自己记录的知识只是表明存在这条知识的声明,对于知识本身是否真实可靠,是无法判断的。Wikidata这样做,就是要显式告诉它的读者,我们所看到的所有知识都有可能是不可靠的,需要谨慎对待。例如在《技术周刊》中指出知识图谱技术依赖NLP技术,那么通过Wikidata的方式可以明确知道《技术周刊》确实存在这样一个声明,但是对于声明内容是否正确是不确定的。
- 常见的知识图谱的属性只包括属性名和属性值,增加限定符的作用是什么?是对属性进行进一步约束。在很多场景下需要复杂属性或嵌套属性,例如“教育经历”这个属性,一般应该包括“学校”、“毕业时间”、“获得学位”等内容,简单的属性是不能够刻画的,同时因为一个人可能有多段教育经历,简单的属性表示也容易产生歧义或错误。这种情况有几种方案可以处理,比如通过新建一种“虚拟实体”表示教育经历,把这个虚拟实体与主体人物实体进行关联,从而记录人的教育经历属性。另外也可以对教育经历这种属性进行特殊化处理。通过限定符就是一种比较好的方式,限定符本身也是一种属性,通过嵌套可以应对非常复杂的情况。
4. 数据预处理
为了方便后续使用分析,设计一种存储格式,对数据进行存储。考虑到分析速度,选择ClickHouse数据库,并参考了[6]中的函数。
重新画了一张数据模型图如下:
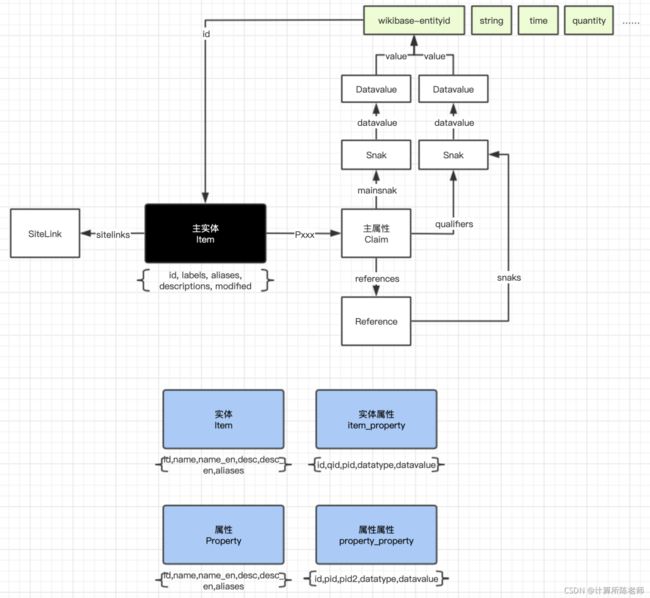
如图中上部分所示,Wikidata图谱模型可以认为是以主实体Item为核心,通过claims(Pxxxx)关联属性Claim,每个属性Claim包含Snak类型的mainsnak结构,每个Snak包含Datavalue即该属性的数据类型,数据类型的值包括wikibase-entityid、string、time、quantity等。属性Claim通过qulifiers关联子属性,属性说明也是Snak类型,Snak也同样包含Datavalue。
图中下半部分表示的是简化的图谱模型,分成4种实体,Item对应Wikidata中的Item实体,Property对应Wikidata中的Property,item_property对应主属性,及直接描述Item的属性,property_property对应子属性。
对应地设计4张关系表,如下所示:
| create table if not exists item (id String, modified String, name String, name_en String, desc String, desc_en String, aliases Array(String)) engine=MergeTree order by toUInt64OrZero(substring(id, 2)); create table if not exists property (id String, modified String, name String, name_en String, desc String, desc_en String, aliases Array(String)) engine=MergeTree order by toUInt64OrZero(substring(id, 2)); create table if not exists item_property (id String, qid String, pid String, datatype String, datavalue String) engine=MergeTree order by toUInt64OrZero(substring(qid, 2)); create table if not exists property_property (id String, pid String, datatype String, datavalue String) engine=MergeTree order by id; |
各表示例数据如下:
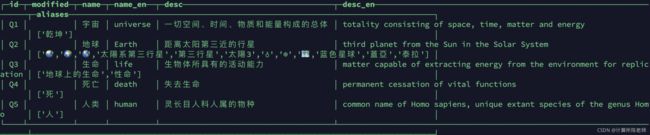


 对数据进行统计,结果如下:
对数据进行统计,结果如下:
| 类别 |
数量 |
备注 |
| Item |
90360000 |
|
| Property |
8074 |
|
| Item_Property |
1153940000 |
|
| Property_Property |
284330000 |
|
| datatype |
8 |
根据Item_Property统计 |
| Item with P31 |
87018286 |
根据Item_Property统计 |
| Item with P279 |
2473388 |
根据Item_Property统计 |
| Item by P31 |
74421 |
|
| Item by P31 & not by P279 |
43570 |
5.Wikidata数据分析
基于已处理的数据可以进行进一步分析。我们提出如下几个问题:
- Wikidata的Item表示实体,对于知识图谱中常见的类型(或概念,以下统一用类型)与实例,如何区分?
- 已知某个实例,它属于什么类型?
- 已知某个类型,它有哪些实例?
- 有哪些“人物”类型的实例?
- 根据Wikidata数据,是否能够以及如何构建类型体系?如同我们手工构建的那样
- 是否能够以及如何找到类型可能具有的属性?
下面逐个进行分析研究。
5.1 实例与类型区分
Wikidata本身并不特殊区分实例与类型,但在已知属性中有两个特殊属性:(1)P31:英文标签“instance of”,中文标签“性质”,描述“本项目所属的性质,本以项目为实例的类别(特别是拥有名称标签的独立个体)”。如果一个Item A具有一个P31属性,指向Item B,则A是B的实例,因此B可以认为是一种类型。找出数据中所有这样的B,作为类型集合1。(2)P279:英文标签“subclass of”,中文标签“上级分类”,描述“此项的上级分类”。如果Item A具有一个P279属性,指向Item B,则A和B都可以认为是类型,并且B是A的上位类型。找出所有这样的A和B作为类型集合2。
将上述两个集合合并,则产生了主要的类型(注意:可能并一定全)。不在这个集合中的Item,我们先作为实例。
通过初步处理,找到了超过74000个类型,示例数据如下:
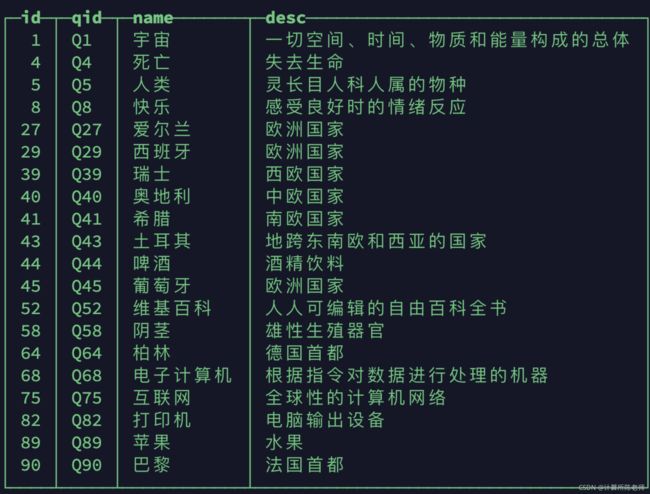
其中“人类”、“死亡”、“宇宙”、“啤酒”实体等符合一般对于类型的认识,但也有不少不符合常识。通过以下查询看下原因:
| select * from item where id in (select qid from item_property where pid='P31' and datatype='item' and datavalue='Q27'); |
结果如下:
 这是一部美国小说!这显示是不对的。这个事实也说明Wikidata的数据存在一定谬误,需要进一步筛选。在后文中将进一步讨论这个问题。
这是一部美国小说!这显示是不对的。这个事实也说明Wikidata的数据存在一定谬误,需要进一步筛选。在后文中将进一步讨论这个问题。
5.2 实例的类型
如前文所述,利用P31属性可以找出一个实例所属的类型。
由于P31属性使用频繁,我们创建一张新的表,单独存储P31属性信息:
| create table if not exists item_property_instanceof (id String, qid String, qid2 String) engine=MergeTree order by id; insert into item_property_instanceof select id, qid, datavalue from item_property where pid='P31' and datatype='item'; select count(*) from item_property_instanceof; |
这张表大约有超过9500万条记录。由于前文处理得到的实例数不超过9000万,因此可知有一部分实例具有多个P31属性声明。
基于这张表,可以快速找到实例所属类型:
| select * from item_property_instanceof where qid='Q1000002'; |
需要指定qid参数。
5.3 类型的实例
与5.2类似,可以查找某个类型的实例:
| select * from item_property_instanceof where qid2='Q5'; |
这个语句查找多有Q5(人类)的实例,获取的是实例的Qid,通过item表获取其他信息。
5.4 人物类型实例
在Wikidata中Q5表示“人类”这个类型,因此通过qid2=’Q5’条件,即可找出所有人类的实例。库中有超过844万“人类”实例。
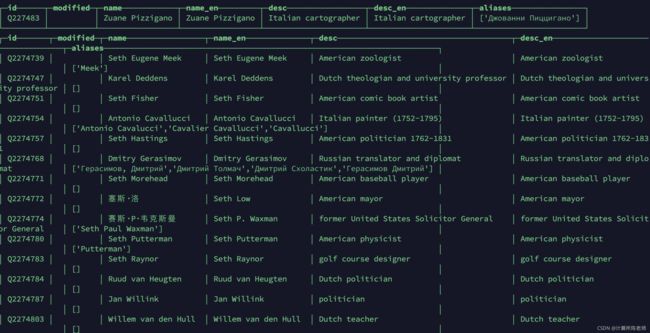
可以看出,Q5的实例确实都是人物。
5.5 构建类型体系
如前文所述,P279表示类型的上下位关系,从而构建类型体系。如果一个类型,不具有P279属性,则称这个类型为顶层类型。通过对前面筛选出的类型进行筛选,获得顶层类型43750个。(过于庞大)
5.6 获取类型Schema
一个类型的Schema就是这个类型包含的属性。例如“人物”通常具有“国籍”、“性别”、“出生日期”等属性。我们的目标是为前面找到的所有类型自动梳理形成它可能的属性。
提出以下定义:
定义1:如果a是类型A的实例(即存在属性声明
定义2:对于A的候选属性Px,找出所有支持实例的集合a-set,定义支持度support(A, Px) = |a-set|,即集合的数量
假设1:如果support(A, Px)达到一定阈值,则称Px是A的可信属性。
假设2:如果support(A, P31)达到一定阈值,则称A是可信类型。
根据假设1,可以设定一个阈值并找出类型的所有可信属性;通过假设2,可以找出更加可信的类型,从而解决5.1中出现的问题。
5.7 Schema规约
根据类型体系,对属性进行消减,具体方法如下:
- 如果A是B的下位(subclass of)类型,且A和B同时具有可信属性Px,那么可以安全地从A中移除;
- 如果A和B具有相同的上位类型C,且A和B同时具有可信属性Px,可以把Px加入到C的可信属性列表中,同时从A和B中移除。由于并不是所有下位类型都有属性Px,因此可以设置一个阈值p_s,仅当C的下位类型中至少有p_s个类型具有可信属性Px时,才把Px作为C的属性;如果没有达到阈值,则可以考虑新增一个新的类型C’,它作为C的下位类型,同时是A和B的上位类型,把A和B的共同属性作为C’的属性。
6. 参考资料
[1]Wikidata. https://www.wikidata.org/wiki/Wikidata:Main_Page
[2]Wikimedia. https://www.wikimedia.org/
[3]https://dumps.wikimedia.org/wikidatawiki/entities/
[4]https://doc.wikimedia.org/Wikibase/master/php/md_docs_topics_json.html
[5]https://www.mediawiki.org/wiki/Wikibase/DataModel/Primer
[6]ClickHouse函数整理(详细)_思过留痕-CSDN博客_clickhouse函数