对话系统中的中文自然语言理解 (NLU) 任务介绍
每天给你送来NLP技术干货!
来自:看个通俗理解吧

Chinese Natural Language Understanding, NLU, in Dialogue Systems 1&2 Task Introduction&Chinese vs English in NLP
当第一次看到自然语言理解的时候,我是感到困惑的。因为自然语言处理的目的就是要去理解人类产生的文本信息,从这个角度讨论,那应该所有的自然语言处理任务,都应该自然语言理解的范围之内。
When I first read about natural language understanding, I was very confused. What is the difference between natural language processing and understanding? The reason for my confusion is that the purpose of natural language processing is to understand human language, discussed from this perspective, all the natural language processing tasks should be within the scope of natural language understanding. To some extent, the concept of "natural language processing" is equivalent to "natural language understanding".
而当经过进一步调查之后,发现大家基本上是把特定的任务称呼为自然语言理解。这一系列中,会贴合大家已经形成的习惯用语,所以这里提到的自然语言理解便是在对话系统场景中的任务。
When the further investigation was carried out, it became clear that people were generally referring to specific tasks as natural language understanding. In this series, the natural language understanding includes the tasks for dialogue systems.
这仍然会是一系列的文章:
自然语言理解任务介绍(←这一篇)
自然语言处理中英文的区别(←这一篇)
学术界中的方法
工业界中的方法
中文对话系统相关的挑战赛
相关的有用的资源、资料
This series of articles will cover:
Task Introduction (← this one)
Chinese vs English in NLP (← this one)
Academic Methods
Industry Methods
Chinese Dialogue System Challenge Track
Resources
谁适合阅读这篇文章?无论是刚进入自然语言处理专业的小白,还是已经深耕这个领域多年的高手,或者你需要一份比较完整的科普讲解思路然后为他人讲解,都希望你能在这一系列文章中获得有用的信息。这一系列文章很适合用于快速了解不同方法的大概思路,或者用于复习一下前人的做法大概有哪些。
Who is suitable to read this article? Whether you are a beginner in the natural language processing field, you are an expert who has been deeply involved in the field for many years, or you are a teacher who needs ideas to explain these tasks to others, I hope you will get useful information in this series of articles. This series can be used for a quick overview of the general ideas of different approaches and previous studies.
1. 任务介绍(Task Introduction)
在这里会先简略的介绍一下它是一个什么样的任务。具体是什么任务在后续的文章中会有详细的介绍。用最简单的话说,我们希望模型能够理解我们说的话,并且做出相应的反应。
We start with a brief description of what task we are talking about. The exact tasks will be described in more detail in the following articles. In the simplest terms, we hope AI models are able to understand what we say and react accordingly.
在下面这个例子中,我们对智能音箱发出了2条指令:播放今天的新闻 以及 提高播放的音量。
In the example below, we said to the smart speaker: play today's news and raise the volume.
这个智能音箱很好的完成了这两个任务:它播放了新闻 并且 提高了音量。
The smart speaker does both tasks well: it plays the news and turns up the volume.
从上面这两个例子中,简单的解释了自然语言理解这个任务。我们是希望模型能够理解下面这些关键的信息:
我们的意图是播放新闻
北京(哪里的新闻)
当天(什么时候的新闻)
我们的意图是调整音量:增大
From these two examples above, the task of natural language understanding is briefly explained. We are expecting the model to understand the following key pieces of information.
Our intention is to play the news
Beijing (where news happened)
The day (when)
Our intention is to adjust the volume: increase
在现实中,这样的例子其实已经渐渐融入了我们的生活:
语音助手Siri, 科塔娜
自助下单、订票、预约
智能家居(灯光、电视、窗帘等语音控制)
In reality, such examples are gradually integrated into our lives:
the voice assistant, Siri and Cortana
Self-service ordering, booking and reservation
Smart homes (voice control of lights, TV, curtains, etc.)
2.自然语言处理中英文的区别(Chinese vs English in NLP)
字符和分词 (Characters and Words)
在中英文中,都有字符这个概念。然而,在理解这两种语言的时候,却有一些不同。在中英文中,不同的字符都会组成不同的词语。但是在英文中,词语之间有明确的界限。而在中文中,是没有这样的界限的。

The concept of character is existing in both English and Chinese. However, there are some differences. In both English and Chinese, different characters make up different words. However, in English, there are clear boundaries between words. In Chinese, there is no such boundary.
所以,在某些场景和方法中,中文分词会成为了预处理中的一个环节。在英文中,则不需要这样的操作。(注意:左图并不代表英文也需要分词,而是一个例子,向不懂中文的读者展示中文分词的大概含义。)

Therefore, in some scenarios and methods, you may find that Chinese word segmentation was one step of the pre-processing procedure. In English, this step is not required. (Note: the diagram on the left does not mean that English also requires word segmentation. It is just a friendly and easy-understand example to show the non-Chinese speaking readers the core idea of word segmentation.)
但是,中文的分词并没有想象中那么容易。因为不同的分词结果会导致整句话的含义发生翻天覆地的变化,从而对这句话造成错误的理解。
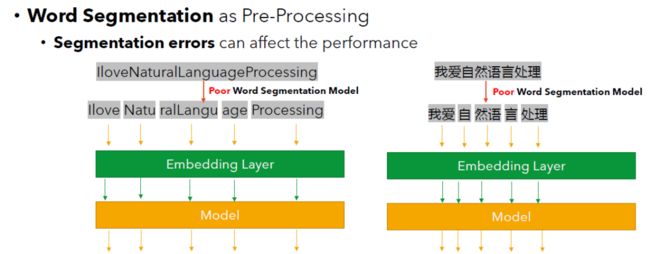
However, Chinese word segmentation is not as easy as one might think. The reason is that different segmentation results can have very different meanings for the whole sentence. AI model may completely misunderstand the sentence.
比如下面这个例子:“看我头像牛不?”
For example:
在这个例子里面,展示了2种分词结果:
1)看我 头像 牛不 ?这句话题的意思是想问问大家自己的头像图片是不是很酷。
2)看我头 像 牛 不?而这句话的意思是说想问问大家自己的头是不是和牛很像。
Here shows two possible word segmentation results of the same sentence:
1)看我 头像 牛不 ?Look at my avatar, is it awesome?
2)看我头 像 牛 不?Look at my head, does it look like a cow?
中文自然语言处理的一般步骤 (General Steps for Chinese Natural Language Processing)
由于中文的特征,所以处理中文的方法一般可以大概分成下面这3类:
Methods for Chinese NLP can generally be divided into the following three categories:
中文文本→预处理步骤(比如中文分词)→词向量→输入到模型中
Chinese text → pre-processing step (e.g. Chinese word segmentation) → word vector/embedding → input to the model

中文文本→字符向量→输入到模型中
Chinese text → character vector/embedding → input to the model

中文文本→预处理步骤(比如中文分词)→预处理结果(比如词向量)+字符向量结合→输入到模型中
Chinese text → pre-processing step (e.g. Chinese word segmentation) → pre-processing results (e.g., word embedding) + character embedding → input to the model
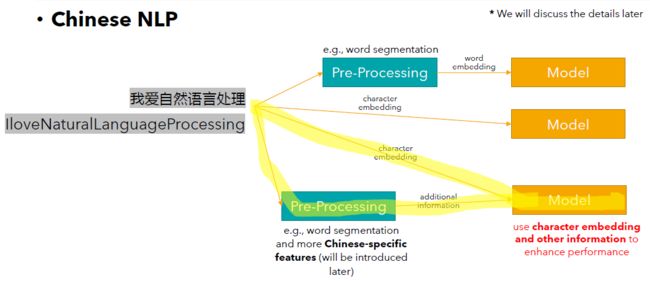
需要注意的是,这几种方法并没有好坏之分,只有适合不适合之分。并不是说结合越来越多的特征,就一定会越来越满足你的需求。同一个方法,在不同的场合可能会有不同的效果。需要根据实际情况,来判断方法的好坏。
It is important to note that there are no good or bad methods of doing Chinese natural language processing, only suitable or unsuitable. It is not the case that combining more and more features will necessarily make an AI model more and more suitable for your needs. The same method may have different performances in different situations.
预处理中除了中文分词,还有什么别的可能的处理呢?
What other possible features could be used to improve model performance?
大家都知道,中文的汉字是很有底蕴的,可以利用的特征还有很多。这只是罗列出了大家比较常用的特征。这里尽量不会对中文汉字文化有太详细的解释。如果你对这部分不是很感兴趣,是可以轻松跳过的。在跳过之前,可以记住这句话,汉字有许多特征可以利用起来,从而帮助模型更好的理解整句话的含义。这些特征可以包括:提取汉字的组成部分、发音、形状等方法。
As we all know, Chinese characters are very culturally rich and there are many more features that can be utilized. We aim to discuss the features that are commonly used. In this section, we try not to go into too much detail about the culture of Chinese characters. If you are not very interested in this section, feel free to skip it. Before skipping, you could keep in mind that there are many features of Chinese characters that can be used to improve an AI model to understand the meaning of the whole sentence better. These features are Chinese radicals, pinyin (romanisation of Chinese), pronunciation, glyphs and so on.
部首偏旁 (Chinese Radical)
为了考虑到不怎么了解汉字的读者,这里对部首偏旁做一个简单的解释。一个汉字可以由不同的部分组成(也可以把每一个汉字想象成是一幅迷你画,这幅画由不同的部分组成的)。部首偏旁就是这个字中的一部分。一般来讲,我们找到一个字的部首偏旁之后,就可以大概猜出这个字的含义和什么相关。这也是为什么有些研究结果证明,融入部首偏旁特征之后,会提高模型自然语言理解的能力。
In order to take into account the readers who do not know much about Chinese, here is a brief explanation of radicals. A Chinese character can be made up of different parts (you can also think of each character as a miniature painting, which is made up of different parts). A radical is a part of this character. Generally speaking, once we find the radicals of a character, we can probably guess what the meaning of the character is related to. This is why some studies have shown that the incorporation of radical features improves the ability of models to understand the Chinese natural language.
以下面这2个图为例:
在左图中,处在中间的是一个部首偏旁,它和眼睛相关。围绕着它的是一圈汉字,这些汉字都含有这个部首偏旁,并且他们的含义和眼睛都有着紧密的联系。
在右图中,“木”字的含义和树有关系。跟在“木”后面的“林”、“森”,可以看的出来,“木”越来越多,于是便有了树丛、树林的含义。
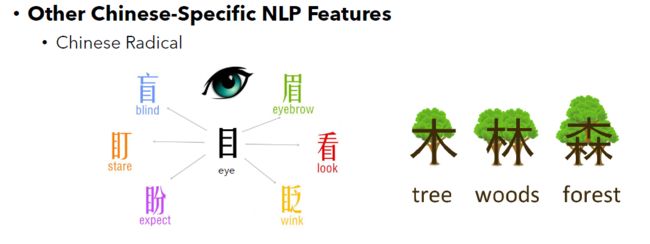 注:配图来源于网络
注:配图来源于网络
Take the following two figures as examples.
In the picture on the left, there is a radical in the middle. This radical is associated with eyes. Surrounding it is a circle of characters which all contain this radical and whose meanings are closely related to eyes.
In the picture on the right, the character "木" has a meaning related to a piece of wood. The character "木" is followed by the two characters "林" (woods) and "森" (forest). It can be seen that there are more and more "木"s in "林" and "森", thus that the two characters have the meanings of a forest.
汉字的拼音(Pinyin, Romanisation of Chinese)
大家都知道,在英文中有音标来标注一个单词如何发音。在中文中,和之非常相似的是拼音。拼音又是由两部分组成:字母和声调(比如是上升还是下降)。这篇文章不会对声调有太多的解释。只需要了解到,同样的字母可以被赋予不同的声调。而不同的声调会表达非常不同的意思。

As you know, in English, there are phonetic symbols to indicate how a word is pronounced. In Chinese, Pinyin, the romanisation of Chinese, is very similar to phonetic symbols. One character's pinyin is made up of two parts: the letters and the tone (i.e., flat, rising, falling-rising, falling or neutral tone). This article will not explain much about tones. It is sufficient to understand the rest of this section if you keep this in mind: the same letter can be given various tones in different situations. That indicates very different meanings.
而让更多的学习汉字的人抓狂的是,同样的一个汉字在不同的上下文下,却也可以拥有不同的声调或者发音。这就会表达非常不一样的意思。

We just discussed that a letter can have different tones for the characters in various words. What drives Chinese learners crazy is that one character's tone and pronunciation are also not fixed. How to pronounce a character also depends on the context in order to use the same character to express different meanings.
汉字的形状 (Glyph)
一些汉字的含义也可以从它的形状中猜出蛛丝马迹。例如下图中的这些例子:
最左边:3种实际存在的事物(太阳、山、大象)
中间:文字演变的过程
最后:今天正在使用的汉字

The meaning of some Chinese characters can also be guessed from their glyph. Below we present three examples:
Leftmost: Sun, Mountain, Elephant
Middle: Character Evolution
Rightmost: the Chinese characters used today
小结 (Summary)
从上面我们可以看出,一个汉字背后的底蕴并不是仅仅一个汉字那么简单。如果能挖掘出来这些隐含的特征,那么可能会对中文自然语言的理解有一定的帮助。其实在英文中,也有类似的做法(比如提取词根、前后缀等预处理方式)。
As we can see from the above, the underlying meaning behind a Chinese character is not as simple as just a Chinese character looks. If these implied features can be unearthed or detected by an AI model, then it may improve the model's ability to understand Chinese. In fact, in English, similar approaches have been adopted (e.g. by extracting word roots and affixes).
下面这个表格中,简单的罗列了不同的中文自然语言处理任务工作都使用了哪些特征。这里并不是一个详尽的列表,只是为了大概展示一下可以在哪些任务中使用这些特征。可能对你现在的工作会有所启发。
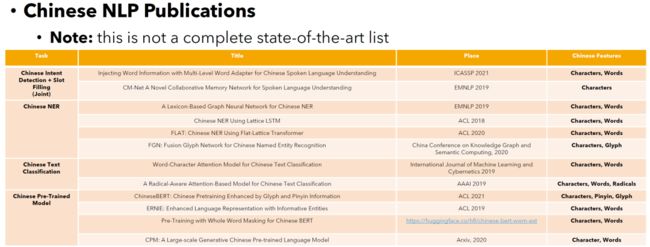
The table below briefly summarises what features were used for different Chinese natural language processing tasks. Please note that this is not an exhaustive list. However, this table can generally provide information--what Chinese-specific features can be used in which tasks. We hope it can bring you some inspiration for your current work.
下一篇 (Next)
在后面的文章中,我们就要开始大概过一下,在学术界中是怎样完成中文自然语言理解的任务啦!
In the following articles, we will start to look at several previous academic methods for Chinese natural language understanding!
“这篇文章的内容是可以自由使用的,但是只能用于非商业目的。在能引用本文的场合希望能够尽量引用。需要注意的是,如果打算以任何形式(包括但不限于翻译或截图)使用任何图片或文字(从其他作者的文章中提取的原始内容除外)用于任何商业目的(包括但不限于在你的PPT幻灯片中使用文章中的图片或文字用于任何行业的在线或离线培训课程资料)之前,请通过微信公众账号或其他方式联系我获得授权。
”
“Please be free to use the material or any parts of the material for non-business purposes. Try to cite this article if you can. Please contact me via the public WeChat account or other ways before you use any pictures or texts (except the original content taken from publications or other authors' articles) in any forms (including but not limited to translating them or making screenshots) for any business/commercial purpose (including but not limited to using the pictures or my texts in your slides for any online or offline courses held by industries).
”
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
为什么回归问题不能用Dropout?
Bert/Transformer 被忽视的细节
中文小样本NER模型方法总结和实战
一文详解Transformers的性能优化的8种方法
DiffCSE: 将Equivariant Contrastive Learning应用于句子特征学习
苏州大学NLP团队文本生成&预训练方向招收研究生/博士生(含直博生)
NIPS'22 | 重新审视区域视觉特征在基于知识的视觉问答中的作用
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~