前言
在Mybatis源码-SqlSession获取文章中已经知道,Mybatis中获取SqlSession时会创建执行器Executor并存放在SqlSession中,通过SqlSession可以获取映射接口的动态代理对象,动态代理对象的生成可以参考Mybatis源码-加载映射文件与动态代理,可以用下图进行概括。
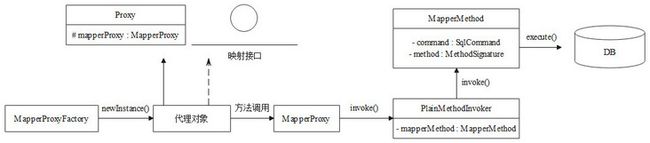
所以,映射接口的动态代理对象实际执行方法时,执行的请求最终会由MapperMethod的execute()方法完成。本篇文章将以MapperMethod的execute()方法作为起点,对Mybatis中的一次实际执行请求进行说明,并结合源码对执行器Executor的原理进行阐释。本篇文章不会对Mybatis中的缓存进行说明,关于Mybatis中的一级缓存和二级缓存相关内容,会在后续的文章中单独进行分析,为了屏蔽Mybatis中的二级缓存的干扰,需要在Mybatis的配置文件中添加如下配置以禁用二级缓存。
正文
本节将以一个实际的查询例子,以单步跟踪并结合源码的方法,对Mybatis的一次实际执行请求进行说明。给定映射接口如下所示。
public interface BookMapper {
Book selectBookById(int id);
}给定映射文件如下所示。
Mybatis的执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
// 获取SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取映射接口的动态代理对象
BookMapper bookMapper = sqlSession.getMapper(BookMapper.class);
// 执行一次查询操作
System.out.println(bookMapper.selectBookById(1));
}
}基于上述的映射接口,映射文件和执行代码,最终执行查询操作时,会调用到MapperMethod的execute()方法并进入查询的逻辑分支,这部分源码如下所示。
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
......
case SELECT:
// 根据实际执行的方法的返回值的情况进入不同的逻辑分支
if (method.returnsVoid() && method.hasResultHandler()) {
// 无返回值情况
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
// 返回值为集合的情况
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
// 返回值为map的情况
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
// 返回值为迭代器的情况
result = executeForCursor(sqlSession, args);
} else {
// 上述情况之外的情况
// 将方法的入参转换为Sql语句的参数
Object param = method.convertArgsToSqlCommandParam(args);
// 调用DefaultSqlSession的selectOne()方法执行查询操作
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
......
}
......
return result;
}已知映射接口中的每个方法都会对应一个MapperMethod,MapperMethod中的SqlCommand会指示该方法对应的MappedStatement信息和类型信息(SELECT,UPDATE等),MapperMethod中的MethodSignature会存储该方法的参数信息和返回值信息,所以在上述的MapperMethod的execute()方法中,首先根据SqlCommand的指示的类型进入不同的逻辑分支,本示例中会进入SELECT的逻辑分支,然后又会根据MethodSignature中指示的方法返回值情况进入不同的查询分支,本示例中的方法返回值既不是集合,map或迭代器,也不是空,所以会进入查询一条数据的查询分支。本示例中单步跟踪到这里时,数据如下所示。
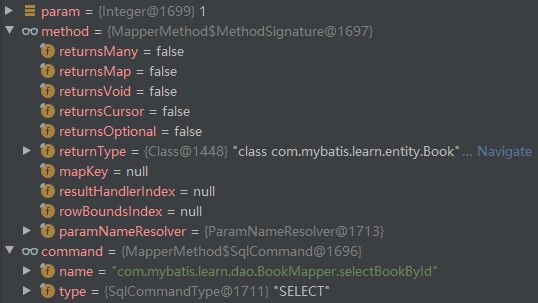
在MapperMethod中的execute()方法中会调用到DefaultSqlSession的selectOne()方法执行查询操作,该方法实现如下所示。
@Override
public T selectOne(String statement) {
return this.selectOne(statement, null);
}
@Override
public T selectOne(String statement, Object parameter) {
// 查询操作会由selectList()完成
List list = this.selectList(statement, parameter);
if (list.size() == 1) {
// 查询结果只有一个时,返回查询结果
return list.get(0);
} else if (list.size() > 1) {
// 查询结果大于一个时,报错
throw new TooManyResultsException(
"Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
} DefaultSqlSession的selectOne()方法中会将查询请求交由DefaultSqlSession的selectList()方法完成,如果selectList()方法返回的结果集合中只有一个返回值,就将这个返回值返回,如果多于一个返回值,就报错。DefaultSqlSession的selectList()方法如下所示。
@Override
public List selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
// 从Configuration中的mappedStatements缓存中获取MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
// 调用Executor的query()方法执行查询操作
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
} 在DefaultSqlSession的selectList()方法中,会先根据statement参数值在Configuration中的mappedStatements缓存中获取MappedStatement,statement参数值其实就是MapperMethod中的SqlCommand的name字段,是MappedStatement在mappedStatements缓存中的唯一标识。获取到MappedStatement后,就会调用Executor的query()方法执行查询操作,因为禁用了二级缓存,所以这里的Executor实际上为SimpleExecutor。本示例中单步跟踪到这里时,数据如下所示。
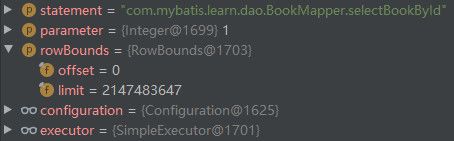
SimpleExecutor的类图如下所示。
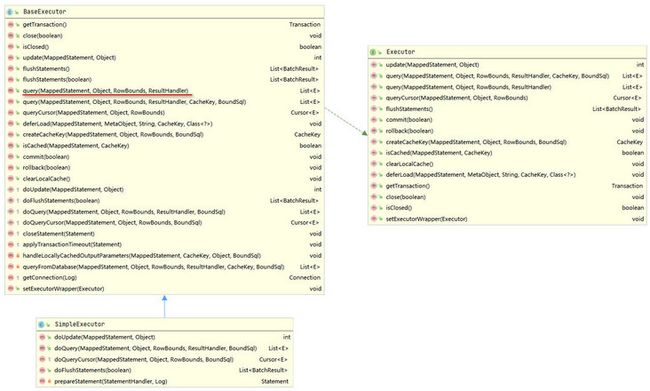
SimpleExecutor和BaseExecutor之间使用了模板设计模式,调用SimpleExecutor的query()方法时会调用到BaseExecutor的query()方法,如下所示。
@Override
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler) throws SQLException {
// 获取Sql语句
BoundSql boundSql = ms.getBoundSql(parameter);
// 生成CacheKey
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
// 调用重载的query()方法
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
} 继续看BaseExecutor中的重载的query()方法,如下所示。
@Override
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler,
CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List list;
try {
queryStack++;
// 先从一级缓存中根据CacheKey命中查询结果
list = resultHandler == null ? (List) localCache.getObject(key) : null;
if (list != null) {
// 成功命中,则返回缓存中的查询结果
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 未命中,则直接查数据库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (BaseExecutor.DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
} 上述的query()方法大部分逻辑是在为Mybatis中的一级缓存服务,这里暂时不分析,除开缓存的逻辑,上述query()方法做的事情可以概括为:先从缓存中获取查询结果,获取到则返回缓存中的查询结果,否则直接查询数据库。下面分析直接查询数据库的逻辑,queryFromDatabase()方法的实现如下所示。
private List queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 调用doQuery()进行查询操作
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 将查询结果添加到一级缓存中
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
// 返回查询结果
return list;
} 上述queryFromDatabase()方法中,会调用BaseExecutor定义的抽象方法doQuery()进行查询,本示例中,doQuery()方法由SimpleExecutor进行了实现,如下所示。
@Override
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 创建RoutingStatementHandler
StatementHandler handler = configuration.newStatementHandler(
wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 实例化Statement
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行查询
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
} 上述的doQuery()方法中,做了三件事情,第一件事情是创建RoutingStatementHandler,实际上RoutingStatementHandler正如其名字所示,仅仅只是做一个路由转发的作用,在创建RoutingStatementHandler时,会根据映射文件中CURD标签上的statementType属性决定创建什么类型的StatementHandler并赋值给RoutingStatementHandler中的delegate字段,后续对RoutingStatementHandler的所有操作均会被其转发给delegate,此外在初始化SimpleStatementHandler,PreparedStatementHandler和CallableStatementHandler时还会一并初始化ParameterHandler和ResultSetHandler。映射文件中CURD标签上的statementType属性与StatementHandler的对应关系如下。
| statementType属性 | 对应的StatementHandler |
作用 |
|---|---|---|
| STATEMENT | SimpleStatementHandler |
直接操作SQL,不进行预编译 |
| PREPARED | PreparedStatementHandler |
预编译SQL |
| CALLABLE | CallableStatementHandler |
执行存储过程 |
RoutingStatementHandler与SimpleStatementHandler,PreparedStatementHandler和CallableStatementHandler的关系可以用下图示意。
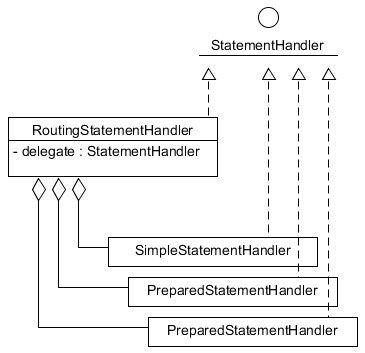
在创建RoutingStatementHandler之后,还会为RoutingStatementHandler植入插件逻辑。Configuration的newStatementHandler()方法实现如下。
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement,
Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 创建RoutingStatementHandler
StatementHandler statementHandler = new RoutingStatementHandler(
executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
// 为RoutingStatementHandler植入插件逻辑
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}继续分析doQuery()方法中的第二件事情,即实例化Statement,prepareStatement()方法实现如下所示。
private Statement prepareStatement(StatementHandler handler, Log statementLog)
throws SQLException {
Statement stmt;
// 获取到Connection对象并为Connection对象生成动态代理对象
Connection connection = getConnection(statementLog);
// 通过Connection对象的动态代理对象实例化Statement
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}prepareStatement()方法中首先会从Transaction中将数据库连接对象Connection对象获取出来并为其生成动态代理对象以实现日志打印功能的增强,然后会通过Connection的动态代理对象实例化Statement,最后会处理Statement中的占位符,比如将PreparedStatement中的?替换为实际的参数值。
继续分析doQuery()方法中的第三件事情,即执行查询。本篇文章的示例中,映射文件的CURD标签没有对statementType属性进行设置,因此查询的操作最终会被RoutingStatementHandler路由转发给PreparedStatementHandler的query()方法,如下所示。
@Override
public List query(Statement statement, ResultHandler resultHandler)
throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 调用到JDBC的逻辑了
ps.execute();
// 调用ResultSetHandler处理查询结果
return resultSetHandler.handleResultSets(ps);
} 如上所示,在PreparedStatementHandler的query()方法中就会调用到JDBC的逻辑向数据库进行查询,最后还会使用已经初始化好并植入了插件逻辑的ResultSetHandler处理查询结果并返回。
至此,对Mybatis的一次实际执行请求的说明到此为止,本篇文章中的示例以查询为例,增删改大体类似,故不再赘述。
总结
Mybatis中的执行器Executor会在创建SqlSession时一并被创建出来并被存放于SqlSession中,如果禁用了二级缓存,则Executor实际为SimpleExecutor,否则为CachingExecutor。Mybatis中的一次实际执行,会由所执行方法对应的MapperMethod的execute()方法完成,在execute()方法中,会根据执行操作的类型(增改删查)调用SqlSession中的相应的方法,例如insert(),update(),delete()和select()等,MapperMethod在这其中的作用就是MapperMethod关联着本次执行方法所对应的SQL语句以及入参和出参等信息。在SqlSession的insert(),update(),delete()和select()等方法中,SqlSession会将与数据库的操作交由执行器Executor来完成,无论是在SimpleExecutor还是CachingExecutor中,如果抛开缓存相关的逻辑,这些Executor均会先根据映射文件中CURD标签的statementType字段创建相应的StatementHandler,创建StatementHandler的过程中还会一并将处理参数和处理结果的ParameterHandler和ResultSetHandler创建出来,创建好StatementHandler之后,会基于StatementHandler实例化Statement,最后在StatementHandler中基于实例化好的Statement完成和数据库的交互,基于创建好的ResultSetHandler处理交互结果并将结果返回。