tensorRT(一)| tensorRT如何进行推理加速?
本文来自公众号“AI大道理”。
深度学习模型在训练阶段,为了保证前后向传播,每次梯度的更新是很微小的,这时候需要相对较高的进度,一般来说需要float型,如FP32。
模型在推断(Inference)的时候只有前向计算,无需回传,因此可以使用低精度技术,如FP16、INT8、甚至是Bit(0和1),其推理结果没有特别大的精度损失。使用低精度数据使得模型需要空间减少,计算速度加快。
优化推理引擎TensorRT只能用来做Inference(推理),不能用来进行train。
使用TensorRT,无需在部署硬件上安装并运行深度学习框架。
![]()
TensorRT
Tensor表示数据流动以张量的形式。所谓张量可以理解为更加复杂的高维数组,一般一维数组叫做Vector(即向量),二维数组叫做Matrix,再高纬度的就叫Tensor,Matrix其实是二维的Tensor。在TensoRT中,所有的数据都被组成最高四维的数组,如果对应到CNN中其实就是{N, C, H, W},N表示batch size,即多少张图片或者多少个推断(Inference)的实例;C表示channel数目;H和W表示图像或feature maps的高度和宽度。RT表示的是Runtime。
TensorRT 的核心是一个 C++ 库,可促进对 NVIDIA 图形处理单元 (GPU) 的高性能推理。它旨在与 TensorFlow、PyTorch、MXNet 等训练框架以互补方式工作。
TensorRT 通过组合层和优化内核选择来优化网络,以改善延迟、吞吐量、电源效率和内存消耗。通过程序指定,它会优化网络以较低的精度运行,从而进一步提高性能并减少内存需求。
TensorRT 上主要存在以下几个对象:
-
builder:构建器。搜索cuda内核目录以获得最快的可用实现,必须使用和运行时的GPU相同的GPU来构建优化引擎。在构建引擎时,TensorRT会复制权重。创建 config、network、engine 等其它对象的核心类。
-
network:tensorrt 的模型类,其它框架的模型在解析之后将被用于填充(populate) network。
-
config:builder 的配置。
-
OnnxParser:onnx 文件解析类,将 ONNX 文件解析并用于填充 tensorrt network 结构。
-
engine:引擎。不能跨平台和TensorRT版本移植。若要存储,需要将引擎转化为一种格式,即序列化,若要推理,需要反序列化引擎。引擎用于保存网络定义和模型参数。在特定 config 与硬件上编译出来的计算引擎,且只能应用于特定的 config 与硬件上,支持持久化到本地以便进行发布或者节约下次使用的编译时间。engine 集成了模型结构、模型参数与最优计算 kernel 配置。同时 engine 与硬件和 TensorRT 版本强绑定,所以要求 engine 的编译与执行的硬件与 TensorRT 版本要保持一致。
-
context:上下文。创建一些空间来存储中间值。一个engine可以创建多个context,分别执行多个推理任务。进行 inference 的实际对象,由 engine 创建,与 engine 是一对多的关系。
-
runtime:用于反序列化引擎。
![]()
TensorRT的使用场景
TensorRT的使用场景很多,服务端、嵌入式端、电脑端都是使用场景。
-
服务端对应的显卡型号为A100、T4、V100等。
-
嵌入式端对应的显卡为AGX Xavier、TX2、Nano等。
-
家用电脑端对应的显卡为3080、2080TI、1080TI等。
显卡需满足TensorRT的先决条件,即显卡计算能力在5.0及以上。
![]()
TensorRT的优化
TensorRT为了能够提升模型在英伟达GPU上运行的速度,做了很多对提速有增益的优化。
(1)算子融合(层与张量融合)(剪枝)
简单来说就是通过融合一些计算op或者去掉一些多余op来减少数据流通次数以及显存的频繁使用来提速。
算子融合把一些网络层进行了合并。在GPU上跑的函数叫Kernel,TensorRT是存在Kernel的调用的。在绝大部分框架中,比如一个卷积层、一个偏置层和一个激活层,这三层是需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起的,TensorRT会对一些可以合并网络进行合并。目前的网络一方面越来越深,另一方面越来越宽,可能并行做若干个相同大小的卷积,这些卷积计算其实也是可以合并到一起来做的。
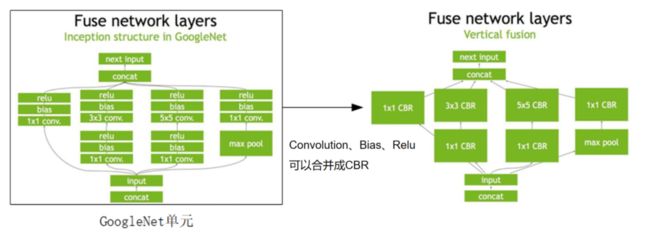
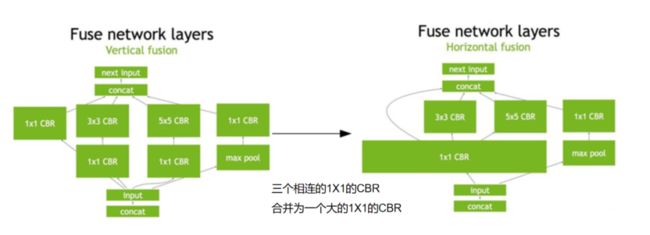
在concat这一层,比如说这边计算出来一个1×3×24×24,另一边计算出来1×5×24×24,concat到一起,变成一个1×8×24×24的矩阵,这个叫concat。这层这其实是完全没有必要的,因为TensorRT完全可以实现直接接到需要的地方,不用专门做concat的操作,所以这一层也可以取消掉。

(2)量化(权重与激活函数校准)
量化即IN8量化或者FP16以及TF32等不同于常规FP32精度的使用,这些精度可以显著提升模型执行速度,且只下降了一点点精度。
在模型业务部署过程中,采用量化方案来进行模型部署优化有以下三个方面优势:存储优势、计算优势、通信优势。
(3)内核自动调整
根据不同的显卡构架、SM数量、内核频率等(例如1080TI和2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式。
Kernel可以根据不同的batch size 大小和问题的复杂程度,去选择最合适的算法,TensorRT预先写了很多GPU实现,有一个自动选择的过程。
(4)动态张量显存
我们都知道,显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,从而可以减少模型运行的时间。
(5)多流执行
使用CUDA中的stream技术,最大化实现并行操作。

![]()
TensorRT的流程
TensorRT整个过程可以分三个步骤,即模型的解析(Parser),Engine优化和执行(Execution)。
首先输入是一个预先训练好的FP32的模型和网络,将模型通过parser等方式输入到TensorRT中,TensorRT可以生成一个Serialization,也就是说将输入串流到内存或文件中,形成一个优化好的engine,得到优化好的engine可以序列化到内存(buffer)或文件(file),读的时候需要反序列化,将其变成engine以供使用。然后在执行的时候创建context,主要是分配预先的资源,engine加context就可以做推断(Inference)。

![]()
TensorRT的技术路线
TensorRT是由C++、CUDA、python三种语言编写成的一个库,其中核心代码为C++和CUDA,Python端作为前端与用户交互。当然,TensorRT也是支持C++前端的,如果追求高性能,C++前端调用TensorRT是必不可少的。
当前 TensorRT 支持 ONNX、Caffe 和 UFF 三种类型 Parser。

本文推荐第二条技术路线,基于ONNX路线。该路线提供C++、python接口,深度定制ONNXParser,低耦合封装,实现YOLOX、YOLO V5等常用模型。
目前TensorRT对ONNX的支持最好,TensorRT-8最新版ONNX转换器又支持了更多的op操作。而深度学习框架中,TensorRT对Pytorch的支持更为友好。
该路线算子由官方维护,模型可直接到处,方便模型部署与AI算法落地。
整体流程:
-
使用pytorch训练模型,生成.pth文件
-
将.pth文件转化成onnx模型
-
在tensorRT中加载onnx模型,并转化成trt的object
-
在trt中使用object进行推理
![]()
总结
TensorRT是一个高性能的深度学习推断(Inference)的优化器和运行的引擎。
TensorRT支持Plugin,对于不支持的层,用户可以通过Plugin来支持自定义创建。
TensorRT使用低精度的技术获得相对于FP32二到三倍的加速,用户只需要通过相应的代码来实现。

——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

—————————————————————
投稿吧 | 留言吧