libtorch学习笔记(17)- ResNet50 FPN以及如何应用于Faster-RCNN
什么是FPN
FPN,即Feature Pyramid Networks,是一种多尺寸,金字塔结构深度学习网络,使用了FPN的Faster-RCNN,其测试结果超过大部分single-model,包括COCO 2016年挑战的获胜模型。其优势是对小尺寸对象的检测。

FPN 代码解读
torchvision中包含了ResNet50 FPN完整的源代码(这里参考的是torchvision 0.7.0里面的代码),这里就解读一下对应的实现,为了解释流畅,尽量采用ResNet-50中的layer name,以及对应的参数:

这里画了一个全局图,将各个卷积层都标识出来,以便于更好的理解FPN:
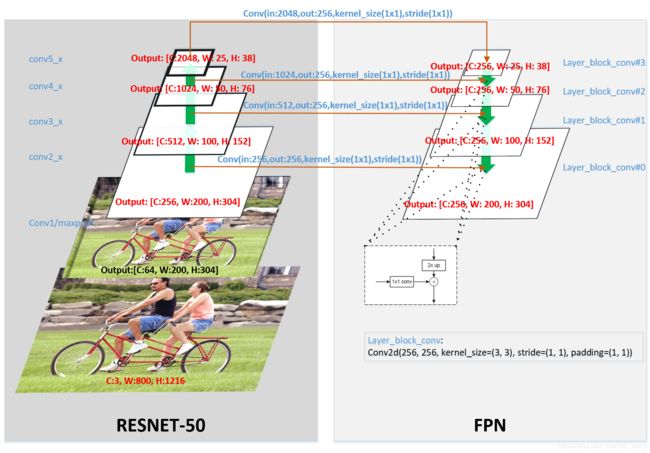
这里左边对应的是layer name,比如conv5_x,这是和ResNet表中layer name可以对应起来。左边的部分称为Bottom-up pathway,右边称为Top-down pathway,ResNet从conv2_x~conv5_x,每层的输出都会输出一份到右边的pathway,这里称之为lateral connections,总的来说可以用下面公式表示表示FPN:
F P N = T o p - d o w n p a t h w a y + l a t e r l c o n n e c t i o n s FPN = {Top\text{-}down\kern{0.4em}pathway} + {laterl\kern{0.4em}connections} FPN=Top-downpathway+laterlconnections
这是对应FPN结构:
(fpn): FeaturePyramidNetwork(
(inner_blocks): ModuleList(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(3): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
(layer_blocks): ModuleList(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(extra_blocks): LastLevelMaxPool()
)FPN处理数据的代码看看如下代码,就能知道对应的流程:
class FeaturePyramidNetwork(nn.Module):
......
def forward(self, x):
# type: (Dict[str, Tensor]) -> Dict[str, Tensor]
"""
Computes the FPN for a set of feature maps.
Arguments:
x (OrderedDict[Tensor]): feature maps for each feature level.
Returns:
results (OrderedDict[Tensor]): feature maps after FPN layers.
They are ordered from highest resolution first.
"""
# unpack OrderedDict into two lists for easier handling
names = list(x.keys())
x = list(x.values())
last_inner = self.get_result_from_inner_blocks(x[-1], -1)
results = []
results.append(self.get_result_from_layer_blocks(last_inner, -1))
for idx in range(len(x) - 2, -1, -1):
inner_lateral = self.get_result_from_inner_blocks(x[idx], idx)
feat_shape = inner_lateral.shape[-2:]
inner_top_down = F.interpolate(last_inner, size=feat_shape, mode="nearest")
last_inner = inner_lateral + inner_top_down
results.insert(0, self.get_result_from_layer_blocks(last_inner, idx))
if self.extra_blocks is not None:
results, names = self.extra_blocks(results, x, names)
# make it back an OrderedDict
out = OrderedDict([(k, v) for k, v in zip(names, results)])
return out这里要指出来的是,如何在pytorch中实现2x up:
F.interpolate(last_inner, size=feat_shape, mode="nearest")这里feat_shape就是2x up之后的shape.
另外一个需要指出的是results,就是存放了每层layer_block_conv的输出,然后送入RPN网络进行背景前景二分类和Bounding-Box回归,在top层支持检测出大的object,越往下越小的对象将被检测出来。
FPN中的Faster-RCNN Anchor
Faster-RCNN有3种scale,3种比例,每个点总共有9种Anchors:
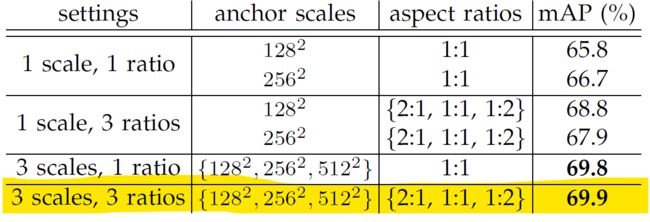
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.] #128x128
[-120. -120. 135. 135.] #256x256
[-248. -248. 263. 263.] #512x512
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]FPN种组织的方式略微不同, 每层只有三个Anchor,总共会在5层上进行RPN处理,所以每个点在所有特征图上总共有15个Anchor,比如针对一张800x1216的图片:
| Layer | anchor_scales | aspect_ratios | Anchor Counts | Size of feature-map of Anchors | Number of Anchors |
|---|---|---|---|---|---|
| layer_block_conv#0 | 3 2 2 32^2 322 | {2:1, 1:1, 1:2} | 3 | 200x304 | 182400 |
| layer_block_conv#1 | 6 4 2 64^2 642 | {2:1, 1:1, 1:2} | 3 | 100x152 | 45600 |
| layer_block_conv#2 | 12 8 2 128^2 1282 | {2:1, 1:1, 1:2} | 3 | 50x76 | 11400 |
| layer_block_conv#3 | 25 6 2 256^2 2562 | {2:1, 1:1, 1:2} | 3 | 25x38 | 2850 |
| LastLevelMaxPool | 51 2 2 512^2 5122 | {2:1, 1:1, 1:2} | 3 | 13x19 | 741 |
| Total | 242991 |
