YOLO(实时目标检测)V1-V2-V3简介和细节改进
深度学习经典检测方法
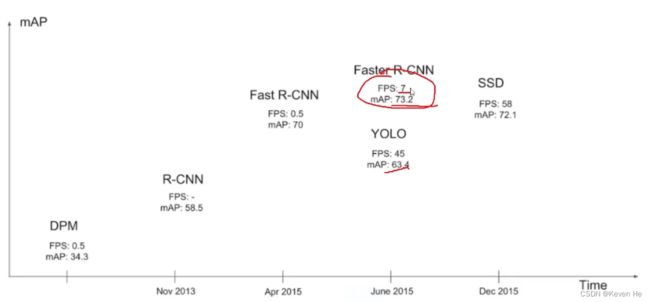
one-stage(一阶段)YOLO系列
核心优势:速度快,适合实时检测任务。
缺点是通常情况下效果不是太好。

two-stage(两阶段):Faster-rcnn Mask-Rcnn系列
速度比较慢,但是效果不错。
指标分析
map指标:综合衡量检测效果,不能只参考精度和recall。


P(Positive)和N(Negative) 表示模型的判断结果
T(True)和F(False) 表示模型的判断结果是否正确FP:假正例 FN:假负例 TP:真正例 TN:真负例
准确率(Accuracy):这三个指标里最直观的就是准确率: 模型判断正确的数据(TP+TN)占总数据的比例

召回率(Recall): 针对数据集中的所有正例(TP+FN)而言,模型正确判断出的正例(TP)占数据集中所有正例的比例.FN表示被模型误认为是负例但实际是正例的数据.召回率也叫查全率,以物体检测为例,我们往往把图片中的物体作为正例,此时召回率高代表着模型可以找出图片中更多的物体!
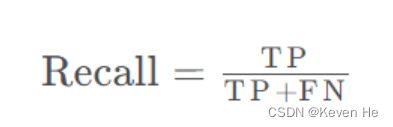
精确率(Precision):针对模型判断出的所有正例(TP+FP)而言,其中真正例(TP)占的比例.精确率也叫查准率,还是以物体检测为例,精确率高表示模型检测出的物体中大部分确实是物体,只有少量不是物体的对象被当成物体
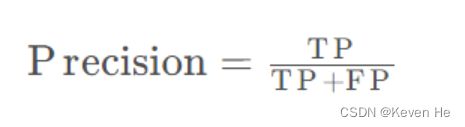
区分好召回率和精确率的关键在于:针对的数据不同,召回率针对的是数据集中的所有正例,精确率针对的是模型判断出的所有正例


YOLO-V1
经典的one-stage方法
You Only Look Once
把检测问题转化为回归问题,一个CNN搞定
可以对视频进行实时检测,应用领域广。
核心思想

网络架构
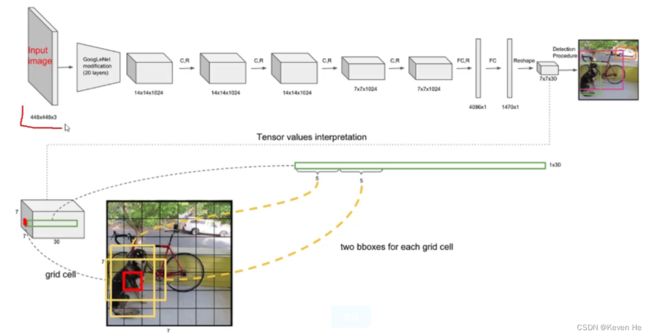
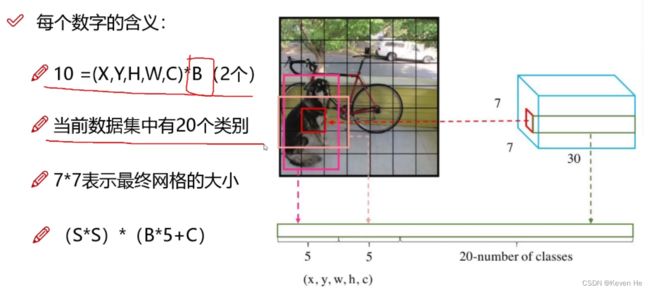
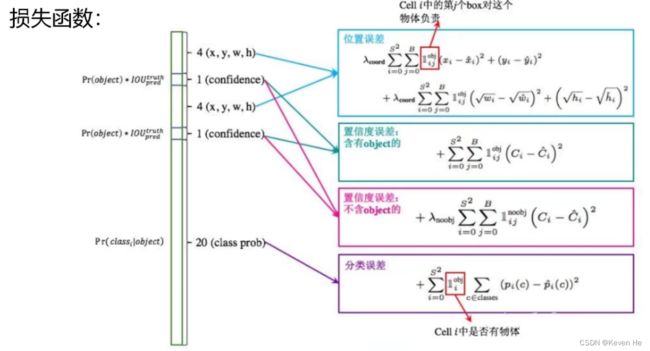
损失函数
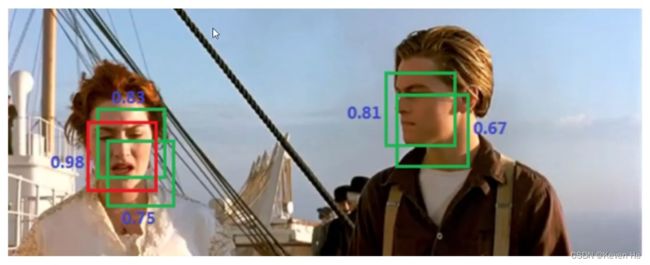
NMS(非极大值抑制)
YOLO-V1存在的问题
每个Cell只预测一个类别,如果重叠无法解决。
小物体检测效果一般,长宽比可选的但单一。
YOLO-V2
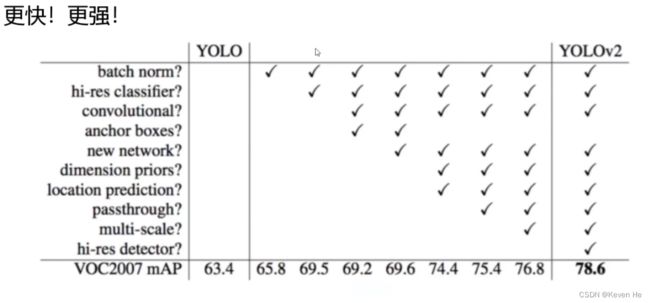
舍弃Dropout,卷积后全部加入Batch Normalization
网络的每一层的输入多做了归一化,收敛相对更容易
经过Batch Normalization 处理后的网络会提升2%的mAP
从现在角度看,Batch Normalization已经成为网络必备处理
V1训练时候用的224 * 224,测试时使用448 * 448
可能导致模型水土不服,V2训练时额外又进行了10次448 * 448的微调
使用高分辨率分类器后,YOLOV2的mAP提升了4%
V2网络结构
DarkNet,实际输入为416 * 416
没有FC层,5次降采样,(13 * 13)
1 * 1卷积节省了很多参数

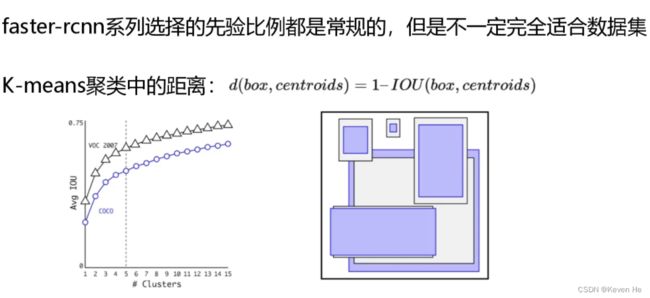
聚类提取先检框
偏移量计算方法


坐标映射与还原

感受野的作用
概述来说就是特征图上的点能看到原始图像多大区域
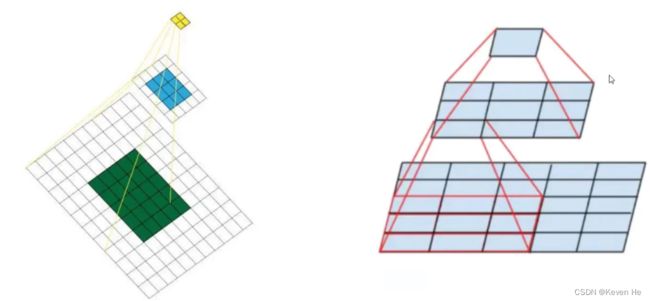


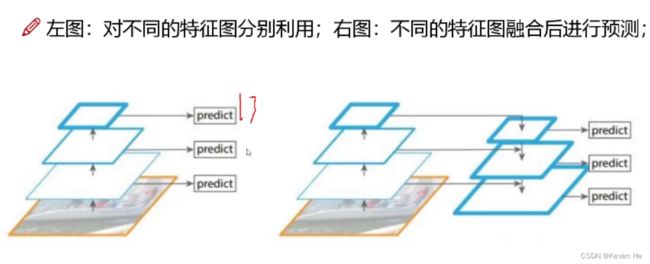
特征融合改进
最后一层时感受野太大了,小目标可能丢失了,需融合之前的特征。


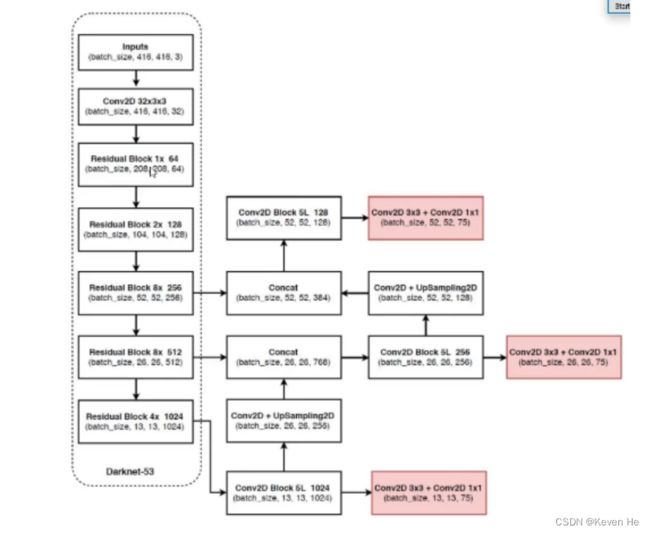
YOLO-V3
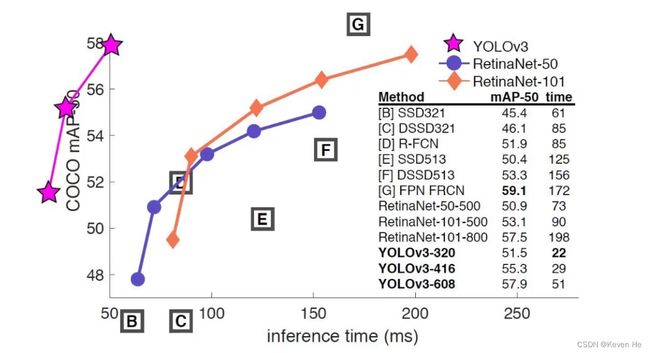
V3最大的改进就是网络结构,使其更适合小目标检测
特征做的更细致,融入多持续特征图信息来预测不同规格物体
先验框更丰富,3种scale,每种三个规格,一共9种
softmax改进,预测多标签任务
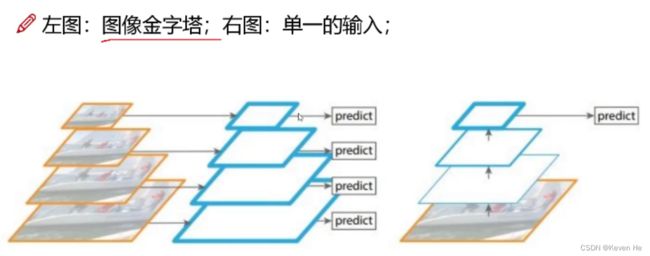
多scale方法改进与特征融合
为了能检测到不同大小的物体,设计了3个scale

经典变换方法对比分析
残差连接方法
残差连接 - 为了更好的特征,基本上所有的网络架构都用上了残差连接的方法

核心网络架构
没有池化和全连接层,全部卷积
下采样通过stride为2实现
3种scale,更多先验框
基本上当下经典做法全融入了

先验框设计改进
YOLO-V2中选了5个,V3有9个

softmax层改进
物体检测任务中可能一个物体有多个标签
logistic激活函数来完成,这样就能预测每一个类别是/不是
