【论文阅读】Spelling Error Correction with Soft-Masked BERT
本文章大部分摘自:
【论文阅读】Spelling Error Correction with Soft-Masked BERT_iioSnail的博客-CSDN博客
文章目录
论文内容
摘要(Abstract)
1. 介绍(Introduction)
2. 方法(Our Approach)
2.1 问题和思路(Problem and Motivation)
2.2 模型(Model)
2.3 Detection Network
2.3 Soft Masking
2.4 Correction Network
2.5 损失函数(Learning)
3. 实验结果(Experimental Result)3.1 数据集(Datasets)
3.2 Baselines(略)3.3 实验设置(Experiment Setting)
3.4 实验结果(Main Result)
论文内容
发表时间:2020年05月
论文地址:https://arxiv.org/abs/2005.07421
代码地址(非作者实现): https://github.com/quantum00549/SoftMaskedBert
摘要(Abstract)
使用Soft-Masked Bert技术完成中文拼写纠错Chinese spelling error correction任务(CSC),并且该方法适用于其他语言。
目前最先进的技术是通过Bert模型,对句子中每个位置的候选列表中选择一个位置进行校正。但是精度并非最佳,因为Bert模型采用遮盖语言建模(mask language modeling)的预训练方式,不能判断句子中每个位置是否有错误。
综上,提出一种新型神经网络架构(包括检错和纠错网络,纠错网络基于Bert),检错与纠错网络通过软遮盖技术(soft-masking technique)相连接。
另外,Soft-Masked Bert技术也通用于其他语言的纠错问题,从实验结果看来,该方法明显优于仅基于Bert模型的Basiline。
1. 介绍(Introduction)
拼写错误纠错通常针对词级或字符级别,本文针对字符级(at character-level)。拼写纠错具有一定挑战性,需要具备一定的世界性知识(如金子塔改为金字塔),还有一定的前后文推断能力(特定语境下,求胜欲改为求生欲)。
针对拼写错误纠错方法逐步进化,由传统机器学习过渡到深度学习。目前最先进的是用Bert模型(也是个字符级模型),原理如下:
在大量未标注数据集中进行预训练,然后使用有标注的数据集微调。最终给定模型一个句子,模型对句子的每个位置都生成一个候选字符列表,并从每个候选字符列表中预测出最可能的字符。该方法之所以强大,是因为Bert模型通过预训练和微调具备了一定的语言理解能力。
但是这个方法的准确度可以进一步提高,观察到模型的检错能力不够高,如果能够检测到错误,就可以更好的纠错。
“模型的检错能力不够高”观点来自:也许是因为Bert模型在预训练时采用的是掩码语言建模机制,Bert更倾向于预测掩码标记的分布,或者预测被遮盖住的字符是什么,而不是去预测错误在哪,如何改正。
基于此,若是能在Bert模型预测前添加一个检错网络,检测出错误所在,或许可以提高纠错能力。这也是本文的观点:
提出Soft-Masked Bert,包含检错网络和一个基于Bert的纠错网络,后者其实相当于一个单独的Bert预测模型。检错网络是Bi-GRU(双向GRU)神经网络,能够预测句子中每个位置的字符错误的概率,利用这个概率,对这个位置的字符进行软遮盖嵌入(soft-masking embedding)。
软遮盖的概念:软遮盖是传统硬遮盖(hard masking)的延伸,因为在错误概率为1时,软遮盖就退化为了硬遮盖。(可以这么理解,硬遮盖就是全部盖住,等同于Bert模型的遮盖,而软遮盖是根据错误概率在字符上设计不透明度,错误概率越大,遮盖得越严实)。
模型工作方式可以理解为:检错模型计算出错误概率,对字符进行软遮盖。软遮盖嵌入字符的句子被输入到纠错Bert模型中,纠错的过程相当于预测被遮盖住的字符是什么。
通过端到端的联合学习,检错网络强制让模型学会正确的上下文关系,更好的进行纠错。
补充,什么是端到端:
深度学习的 “ 端到端模型(end-to-end learning)”
相对于深度学习,传统的机器学习将步骤分为了多个独立的模块,每个模块的好坏直接影响到下一模块,从而影响训练结果。这是非端到端。
而深度学习模型在训练过程中,从输入端(输入数据)到输出端会得到一个预测结果,与真实结果相比较会得到一个误差,这个误差会在模型中的每一层传递(反向传播),每一层的表示都会根据这个误差来做调整,直到模型收敛或达到预期的效果才结束,中间所有的操作都包含在神经网络内部,不再分成多个模块处理。由原始数据输入,到结果输出,从输入端到输出端,中间的神经网络自成一体(也可以当做黑盒子看待),这是端到端的。
两者相比,端到端的学习省去了在每一个独立学习任务执行之前所做的数据标注,为样本做标注的代价是昂贵的、易出错的。
总之,这篇论文的主要工作在于:提出Soft-Masked Bert模型并加以大量实验验证。
2. 方法(Our Approach)
2.1 问题和思路(Problem and Motivation)
CSC任务的问题描述:给定字符序列X=(X1,X2,X3···),将其转化为相同长度的字符序列Y=(Y1,Y2···),其中X中的错误字符已被改正。这个任务也可以看作顺序标记问题,模型相当于一个X到Y的映射函数。
思路:上文提到,这里不再赘述。
2.2 模型(Model)
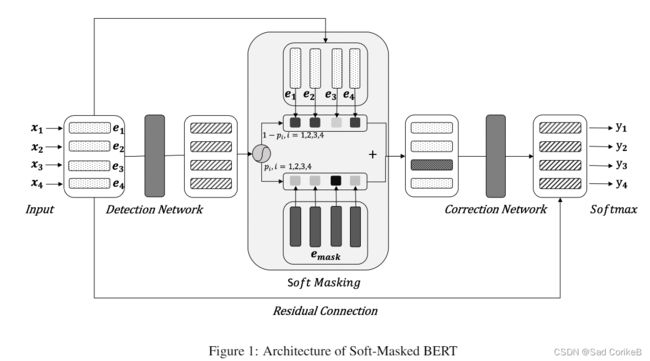
该模型分为三部分:
Detection Network:负责预测句子中每个字错误的概率
Correct Network:负责将错字纠正成正确的字。
Soft Masking:Detection Network和Correction Network之间的桥梁,负责根据Detection Network的输出对原始句子embedding进行mask。
2.3 Detection Network
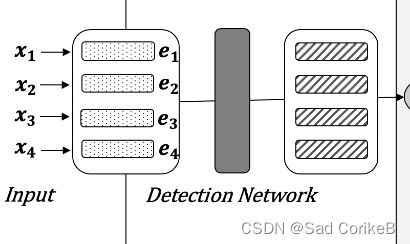
输入: 嵌入序列 E = (e1, e2, · · · , en),其中 ei 表示字符 xi 的嵌入,它是词嵌入、位置嵌入和段落嵌入信息的总和。(embedding方式和BERT一样)
网络架构:Bi-GRU -> 全连接层(Linear) -> Sigmoid
输出:标签序列G = (g1, g2, · · · , gn),其中gi表示第i个字符错误的概率,1表示字符错误,0表示正确。每个character为错字的概率,越接近1表示越有可能是错的。
2.3 Soft Masking
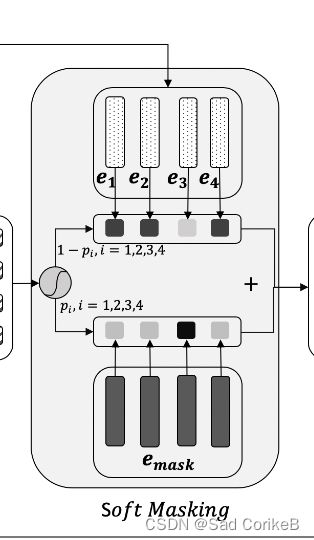
Soft Masking模块就是对Input进行mask,方式就是加权,公式为:
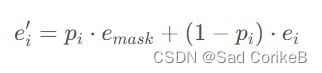
2.4 Correction Network
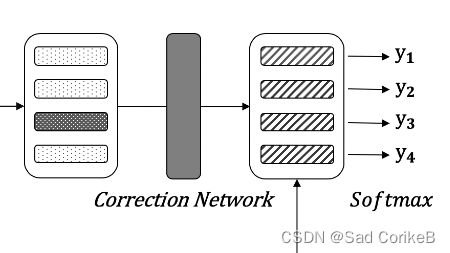
输入:soft-masking后的input。
网络架构:BERT+全连接层(Linear)+Softmax
输出:将词修正后的结果。
2.5 损失函数(Learning)
Detection Network和Correction Network损失函数使用的都是CrossEntropy。
3. 实验结果(Experimental Result)
3.1 数据集(Datasets)
训练集:自己造的,使用confusion table的方式。具体为将一个句子中15%的字替换成与其相同发音的其他常见字。在所有样本中,有80%的句子按上述方式处理,剩下20%则是直接随机替换成任意文字。
3.2 Baselines(略)
3.3 实验设置(Experiment Setting)
优化器(optimizer):Adam
学习策略(Learning Scheduler): 无
学习率(Learning Rate):2e-5
The size of hidden unit in Bi-GRU is 256
batch size: 320
作者还使用了500w个训练样本和SIGHAN中训练样本对BERT进行了fine-tune.
3.4 实验结果(Main Result)
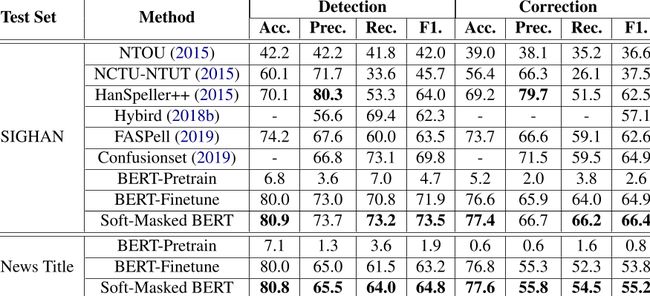
Acc:Accuracy,准确率
Pre:Precision,精准率
Rec:Recall,召回率
F1:F1 Score