【论文阅读】PHMOSpell: Phonological and Morphological Knowledge Guided Chinese Spelling Check
目录
论文内容
摘要(Abstract)
1 介绍(Introduction)
2 相关工作(Related Work)
3 方法
3.1 问题表述(Question Fomulation)
3.2 模型(Model)
3.3 拼音提取模块(Pinyin Feature Extractor)
3.4 字形提取模块(Glyph Feature Extractor)
3.5 语义特征提取模块(Semantic Feature Extractor)
3.6 自适应门(Adaptive Gating)
3.7 训练(Training)
3.8 推理(Inference)
4 实验(Experiments)
4.1 数据集(Datasets)
4.2 Baseline Method
4.3 评估指标(Evaluation Metrics)
4.4 实验设置(Experimental Setup)
4.5 主要结果(Main Results)
编辑4.6 消融研究(Ablation Study)
4.7 超参数的影响(Effect of Hyper Parameters)
4.8 特征可视化(Features Visualization)
5 总结(Conclusion)
论文内容
发表时间:2021年
DOI:10.18653/v1/2021.acl-long.464
Journal:ACL
摘要(Abstract)
目的:中文拼写检查(CSC)
背景:数据显示,大部分中文拼写错误都是是将正确汉字错写为听起来差不多的字(听觉错误,音韵相似)或看起来差不多的字(视觉错误,词形相似),但是很少有方法利用词形和音韵去进行纠错。
观点:提出端到端的PHMOSpell模型,利用多模态信息提升了 CSC 的性能--将汉字的拼音(音韵信息)和字形表示(词形信息)集成到预训练模型中。
验证观点:经过综合实验和消融测试(总共三轮实验),该模型优于目前最先进的模型。
1 介绍(Introduction)
中文和英文不同,它是一种表意文字,包含大量字符,没有字间分隔符。在对中文纠错时,必须结合上下文信息和语境判断,而且当出现拼写错误时,即使是拼写错误的汉字也是词汇表中的有效字符,让纠错更加困难。另外,在改错时如何从庞大的候选队列中选出正确汉字也是难题之一。

前文所说,大部分拼写错误来自拼音相似和字形相似。如图所示,汉字都可以用拼音和部首进行表示。如果将汉字的字形、拼音作为信息帮助模型判断,会是很好的方法。
相似研究现状(曾有人试图将拼音、部首这两个信息融合到CSC过程中):①在大部分方法中,拼音或部首被用作外部资源或启发式过滤器,无法以端到端的方式使用模型进行训练②在2020年提出的SpellGCN,通过图卷积网络 (GCN) 将语音和词法相似性纳入预训练的语言模型中,其中的相似度图依赖于特定的混淆集。 由于混淆集无法覆盖所有的字符,特征融合的方法也比较简略,SpellGCN只能融合有限的信息。
改进:通过自适应门Module将汉字的拼音和部首特征融入预训练模型,该模型可以进行端到端的训练。实验证明该方法的潜在表示不仅可以捕获语义信息,还可以捕获语音和形态信息,并且优于所有的baseline方法。
2 相关工作(Related Work)
CSC三种方法:基于规则,基于统计,基于深度学习。
(具体略)
3 方法
3.1 问题表述(Question Fomulation)
CSC任务的问题描述:给定字符序列X=(X1,X2,X3···),将其转化为相同长度的字符序列Y=(Y1,Y2···),其中X中的错误字符已被改正。任务中用到的模型就相当于一个X到Y的映射函数。
3.2 模型(Model)
模型 = 3个特征提取Module + 1个自适应门Module(用于融合/集成这些特征)
3个特征 = 拼音特征 + 字形特征 + 上下文相关语义特征
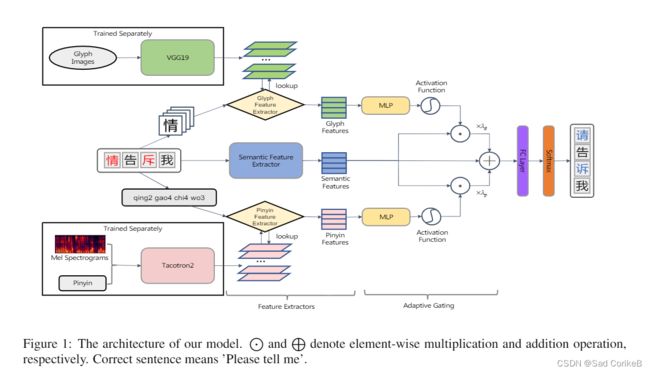
如图所示,将一个句子输入到模型中,模型首先为每个字符提取拼音特征、字形特征和上下文相关语义特征,然后通过自适应门Module集成这三个特征。
注:图中的MLP为多层感知机
最后,每个字符的集成结果被送入一个全连接层并在整个词汇表中计算概率,其中概率最高的字符被选为替换字符。
3.3 拼音提取模块(Pinyin Feature Extractor)
Tacotron2(一种TTS神经网络模型),是谷歌在2017年推出的端到端神经网络,能供实现输入文字,输出逼真的对应语音。
使用TTS模型进行音韵表示的原因:因为TTS模型输出的语音十分逼真,让语言预处理模型更能捕捉到词语之间音韵的相似性。
从TTS模型中选择Tacotron2进行音韵表示的原因,一是因为Tacotron2表现优秀,二是因为Tacotron2的位置敏感注意力机制是通过将字符序列和声音序列对齐后再进行分析的,也就是将字符序列和声音序列看作一个整体,这样就能更好的将拼音(字符序列)和音韵(声音序列)结合起来。

具体实现:
①字符序列->拼音序列
②拼音序列->梅尔频谱图(mel spectrogram)
③在Tacotron2训练期间,将拼音序列和梅尔频谱图共同作为输入(实现对拼音表示的建模)
④将Tacotron2编码器(endoder)中的拼音嵌入层(pinyin embedding layer)作为提取到的拼音特征,生成CSC文本的语音表示Fp(一个向量,其中每个元素代表每个字符的语音表示)。
在Tacotron2的编码器中,拼音序列和梅尔频谱图结合得更加紧密,成为拼音嵌入层。
拼音嵌入层将作为CSC任务中的拼音特征(图中的Pinyin Features)。
3.4 字形提取模块(Glyph Feature Extractor)
模块的主干:在ImageNet经过大规模预训练的VGG19模型
附上VGG19的介绍:深度学习之VGG19模型简介 - 简书
材料:8106个中文字符图片
对VGG19在这些字符图片材料上进行调试,目的是:没看懂:)。
原文:
we further finetune it with the objective of recovering the identifiers from glyph images to solve the problem of domain adaptation.
翻译:我们将VGG19模型进一步调试,恢复字符图片中的标识符,以解决领域适配问题。
我的理解:
通过恢复字符图片中的标识符,让VGG19在提取字符特征上表现得和本文的CSC任务更加适配。
在模型调试结束后,删除模型最后的分类层,使用最大池化层的输出作为字形特征(Glyph Feature)。

总而言之,提取字符特征的步骤为:
对给定句子X,首先找到对应字符的图像(Glyph Images),再通过VGG19生成字符特征Fg(一个向量,其中每个元素代表每个字符的字形表示)。
3.5 语义特征提取模块(Semantic Feature Extractor)

主干:Bert,是依靠大量预训练习得的知识来进行判断的模型,利用它来提取上下文的语义特征
给定句子X,Bert提取器在最后一层输出的隐藏状态(?hidden states),就是语义特征Fs(一个向量,其中每个元素代表每个字符的上下文语义特征)。
3.6 自适应门(Adaptive Gating)
自适应门是本文提出的独特的特征融合方法,与以前的简单相加或连接不同(忽视了特征之间的联系),自适应门更像一个能够仔细控制特征融合的大门,下面将介绍它的控制机制。

Fp:拼音特征; Fg:字形特征;Fs:语义特征

σ:激活函数,实现中使用的是ReLu
· :代表逐元素乘法
Wp,Wg,bp,bg:模型要训练的参数

通过自适应门来控制字形特征与拼音特征分别同语义特征如何融合,融合多少,并将两个融合结果分别乘以不同的系数λ后相加,得到Fe。

最后通过线性连接的方式向 Fe 和 Fs 添加残差连接,得到Fes,并将Fes传输到下一层分类器模块。
3.7 训练(Training)
在训练中,首先将融合结果Fes喂到全连接层(full-connected layer)做最后的分类。全连接层定义如下:

Wfc,bfc是全连接层中需训练的参数,Yp是根据错误句子X预测出来的新句子。
训练的根本目的:比对预测句子Yp和X对应的正确句子Yg,看二者是否匹配。
大致上讲,学习过程是由字符是否匹配的最小化负对数似然结果驱动的(这句没懂)。

3.8 推理(Inference)
推理时,针对每个字符,选择模型给出的可能性最高的更正结果作为候选。
至于如何检测给定句子X是否有错:检查模型更正后的句子,和原句X相比是否不同,得出是否有错。
4 实验(Experiments)
4.1 数据集(Datasets)
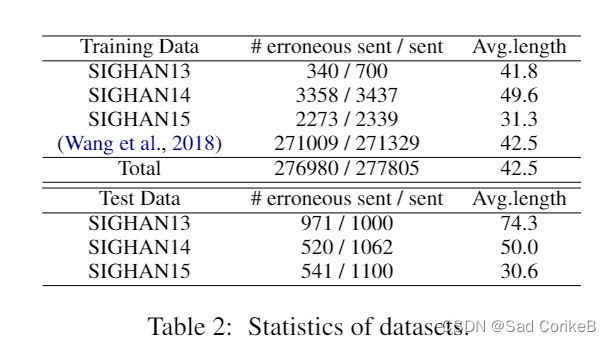
实验选择了三个开源的基准数据集用于测试。
训练数据集:来自SIGHAN13,SIGHAN14,SIGHAN15的训练数据 + 271K的OCR,ACR自动识别的训练样本
测试数据集:来自SIGHAN13,SIGHAN14,SIGHAN15的测试数据
另外,SIGHAN数据集中的字符都使用OpenCC5转为了简体格式。
4.2 Baseline Method
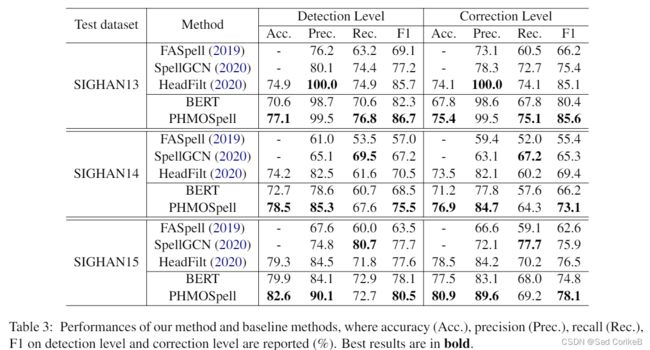
将本文提出的模型与四个Basiline方法进行比对,以下是这四个Baseline的介绍:
| FASPell | 用Bert作为去噪编码器生成错误字符的预测,结合置信度相似度解码器过滤掉音韵、字形不相关的结果。 |
| SpellGCN | 通过图卷积网络学习字符间的音韵、字形关系,并将图特征与Bert生成的语义特征结合来预测正确的字符。 |
| HeadFilt | 使用分层的字符嵌入层训练出的自适应过滤器,来估计字符和Bert产生的候选字符之间的相似性。 |
| Bert | 用训练集对Bert进行微调,选择可能性最大的候选字符作为纠错结果。 |
4.3 评估指标(Evaluation Metrics)
在CSC任务中经常用句子级的指标进行评估,本文也如此。
句子级指标相比词级指标更加严格,因为句子中所有的错误都需要被校正才算合格。
指标包括:accuracy, precision, recall and F1 score
如何计算指标:在检错和纠错中分别进行每个指标的计算
4.4 实验设置(Experimental Setup)
模型基于huggingface的pytorch transformers实现。
在语义特征提取模块中用bert-base-chinese初始化权重,在字形特征提取模块中用torchvision library的pretrained VGG19初始化权重。自适应门的初始权重随机初始化。
optimizer:AdamW optimizer
epoch:5
learning rate:1e−4.
Batch size:64 for training and 32 for evaluation
4.5 主要结果(Main Results)
 4.6 消融研究(Ablation Study)
4.6 消融研究(Ablation Study)
消融测试:研究该方法中每个组件的有效性
在进行消融实验时,所有参数都取相同。
消融实验主要步骤:
1.将自适应门替换为简单的合并策略-->检错纠错性能都变差了
2.将拼音特征提取模块和字形特征提取模块分别从模型中去除,发现当移除拼音特征模块时性能下降更多,意味着音韵信息对CSC更重要。
3.在移除两个特征提取模块和自适应门后性能下降了更多。说明这三个组件对模型优秀的表现都有至关重要的作用。
下表是消融实验结果:

4.7 超参数的影响(Effect of Hyper Parameters)
略
4.8 特征可视化(Features Visualization)
略
5 总结(Conclusion)
略