ML2021 | (腾讯)PatrickStar:通过基于块的内存管理实现预训练模型的并行训练
前言
目前比较常见的并行训练是数据并行,这是基于模型能够在一个GPU上存储的前提,而当这个前提无法满足时,则需要将模型放在多个GPU上。现有的一些模型并行方案仍存在许多问题,本文提出了一种名为PatrickStar的异构训练系统。PatrickStar通过以细粒度方式管理模型数据来更有效地使用异构内存,从而克服了这些缺点。
本文附上了PatrickStar的使用示例。PatrickStar与模型定义无关,在PyTorch脚本上添加几行代码可以带来端到端的加速。
本文来自公众号CV技术指南的论文分享系列
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。


论文:PatrickStar: Parallel Training of Pre-trained Models via Chunk-based Memory Management
代码:https://github.com/Tencent/PatrickStar
使用示例
先介绍一个大家比较关心的问题--复不复杂,好不好实现。
PatrickStar与模型定义无关,在PyTorch脚本上添加几行代码可以带来端到端的加速。

Background
现在人工智能的共识是采用PTMs(Pre-Trained Models)作为任务的骨干,而不是在与任务相关的数据集上从头开始训练模型。PTMs的高性能伴随着众多的参数,这对计算和存储资源提出了巨大的要求。
由于大型的模型数据在单个GPU的内存无法存储,所以最常用的数据并行技术不适用于PTM(比较常见的例子是2012年的AlexNet)。通过利用并行训练在多个GPU内存之间分配模型数据,例如ZeRO、模型并行和流水线并行,最新进展使得PTM规模的增长成为可能。SOTA解决方案是将它们组合成3D并行,它可以在数千个GPU上将PTM扩展到数万亿个参数。
创新思路
作者观察到在PTM训练期间必须管理的两类训练数据:模型数据由参数、梯度和优化器状态组成,它们的足迹与模型结构定义相关;非模型数据由operator生成的中间张量组成。非模型数据根据训练任务的配置(如批次大小)动态变化。模型数据和非模型数据相互竞争GPU内存。
现有的解决方案在不考虑非模型数据的情况下,在CPU和GPU内存之间静态划分模型数据,并且它们的内存布局对于不同的训练配置是恒定的。这种静态的分区策略导致了几个问题。
首先,当GPU内存或CPU内存不足以满足其相应的模型数据要求时,即使当时其他设备上仍有内存可用,系统也会崩溃。其次,当数据在张量粒度的不同内存空间之间传输时,通信效率低下,当可以将模型数据提前放置到目标计算设备上时,CPU-GPU通信量是不必要的。
针对上述问题,本文提出了一种名为PatrickStar的异构训练系统。PatrickStar通过以细粒度方式管理模型数据来更有效地使用异构内存,从而克服了这些缺点。
作者将模型数据张量组织成块,即大小相同的连续内存块。在训练期间,根据组块的张量状态来动态编排组块在异构存储空间中的分布。通过重用不共存的块,PatrickStar还比SOTA解决方案进一步降低了模型数据的内存占用。
作者使用预热迭代(warm-up iteration)在运行时收集模型数据的可用GPU内存的统计信息。设计了一种高效的块回收策略和基于统计数据的设备感知操作符放置策略,以减少CPU-GPU的数据移动量。使用零冗余优化器,基于块的内存管理可以通过块的GPU内通信(intra-GPU communication)有效地与数据并行共生。
Contributions
1.从头开始构建了一个基于块的内存管理DNN训练系统,名为PatrickStar。与现有的异构训练方法相比,该方法通过缩小非模型内存空间、提高内存效率和降低CPU-GPU通信量,支持更大的模型规模和更高的计算效率。
2.基于块的管理与零冗余优化器数据并行自然是共生的。基于块的集体通信模式降低了GPU内带宽需求和提高了带宽利用率。
3.作者在拥有8x V100 GPU、240 GB和120 GB DRAM内存CPU的云计算节点上对系统进行了评估。在240 GB内存的情况下,PatrickStar训练了一个120亿参数的类似GPT的模型,这是DeepSpeed最大模型规模的1.5倍。在120 GB内存的情况下,PatrickStar的模型比例是DeepSpeed的4倍。
4.PatrickStar的计算效率比DeepSpeed更高,在8x GPU上实现了超线性伸缩。
Design Overview
论文设计了一个并行PTM训练系统PatrickStar,它的工作原理如下图所示。
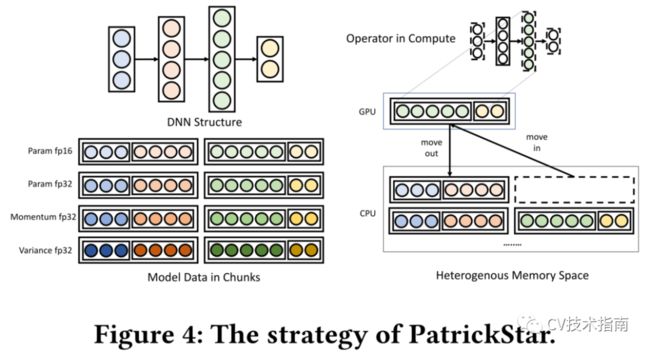
PatrickStar通过将模型数据分块管理并存储在异构空间中,提高了现有异构训练的模型规模和效率。图中的圆圈表示参数的元素,它们在内存中以块的形式排列。当操作符的计算被触发时(右图的彩色部分),PatrickStar将参数所在的块安排到所需的计算设备上。
论文提出了在异构内存空间中高效编排块的优化方案。此外,它还可以与零冗余优化器相结合,扩展到多个GPU。必要时,在训练过程中将组块移动到所需设备。
System design on a single GPU
PatrickStar作为PyTorch和异构内存之间的中间件,如上图所示。
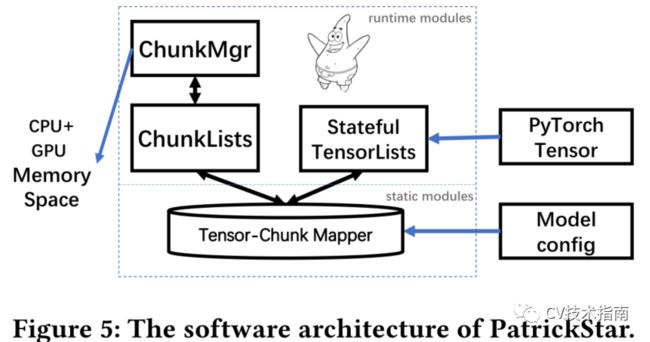
系统由在预处理阶段工作的静态模块和在训练阶段工作的运行时模块组成。PatrickStar的静态模块在训练前进行处理。
基于神经网络结构,构造了张量与组块之间的映射模式。
在训练过程中,运行时模块通过将张量重定向到所管理的基于块的存储空间来接管PyTorch的内存访问,并使用块管理器来智能地管理异构存储空间中的块。
Preprocessing Stage
在训练开始之前,在预处理阶段为模型数据的每个张量分配一块块空间,并生成块-张量映射模式。一个有效的映射模式需要具备以下三个特征:1.增加张量访问的局部性。2.降低峰值内存消耗。3.对并行友好。
论文提出了一个高效的映射模式。
简单来说,根据模型数据中张量的类型,将组块分为四种类型,即参数FP16列表、参数FP32列表、动量列表和方差列表,共14M字节(M为参数数)。组块具有相同的大小,因此不同的组块可以重用相同的内存,并且有利于并行训练中的集体通信。特别的是,PatrickStar没有分配分级FP16列表。梯度FP16张量可以重用参数FP16列表的块空间,消除了梯度FP16张量对参数FP16张量的依赖。
与最小模型数据内存占用为16M字节的ZeRO-Offload相比,PatrickStar减少了内存占用。此外,它还分配了额外的GPU内存,用于保存要移动到CPU的渐变,而PatrickStar则消除了这一开销。因此,与其他PTM训练方案相比,PatrickStar的模型数据存储空间最小。
Training Stage
在训练过程中,PatrickStar需要正确高效地编排异构存储空间中的数据块。论文介绍了导块正确移动的机制,并介绍了一种优化策略以提高其效率。此机制比较复杂,论文有非常具体的介绍,这里不予解读。
Scaling to Multiple GPUS
PatrickStar使用多进程在多个GPU之间执行数据并行化。假设进程数为nproc。每个进程负责单个GPU,而所有进程共享CPU。进程的异构内存空间由GPU的全部内存和1/nproc的CPU内存空间组成。该进程以与零冗余优化器相同的方式管理位于其本地异构存储空间中的总块的1/nproc。本地空间中的块称为本地块,而不在本地空间中的块称为远程块。

如图所示,通信组由块列表的nproc连续块组成,其中每个块属于不同的进程。根据前面的块张量映射模式,我们可以设计一种以最小的进程间通信量实现数据并行的通信方案。进程只需要在FWD和BWD阶段传送参数FP16和梯度FP16。需要最大量数据(包括动量、方差、参数FP32和梯度FP16)的ADAM阶段在本地执行。
论文中有非常详细的过程介绍与算法,这里不予解读。
与相关工作相比,PatrickStar获得了更低的GPU内带宽需求和更高的带宽利用率。根据成本模型,PatrickStar的带宽要求为2(p−1)/p×2m(all-gathers)+(p−1)/p×2m(reduce-scatter)=6(p−1)/p×M,其中p为并行度,M为参数个数。在ZeRO-Offload和ZeRO-DP中,每层的参数由单个进程拥有并广播给其余进程。与all-gathers相比,广播将数据传输集中在单个GPU上,并未充分利用聚合带宽。
基于广播的带宽要求为4(p−1)/p×2M(广播)+(p−1)/p×2M=10(p−1)/p×M,比PatrickStar提高了2/3。虽然Zero-Infinity也采用了all-gathers的方式,但PatrickStar的带宽利用率仍然较高。
已经证明,将序列张量布置为大块(bucket)来传输的分组化策略可以导致更高的带宽利用率,因为它将在每次通信中传输更多的数据。PatrickStar中基于块的方法自然是分块的,而ZeRO-Infinity的传输单元是张量。PatrickStar进一步避免了数据复制开销,以提高性能。
Optimization
将模型数据托管在GPU内存中相比,异构训练方法引入了额外的CPU-GPU数据移动开销。对基于块的内存管理进行了优化,使其更加高效和强大。
首先,它可以以细粒度的方式布局运算符,使内存密集型运算符不在他们的首选设备上,但它可以减少数据移动量,提高系统的整体效率。为此,PatrickStar提出了一种Device-aware Opetator Placement优化。
其次,当数据不能永久驻留在运营商的计算设备上时,如果不使用,数据块就会被逐出。除了在更大的模型规模上进行改进外,PatrickStar还通过块逐出策略将块逐出量降至最低。
为了实现上述优化,我们必须在训练过程中很好地了解每台设备上有多少GPU内存空间可以分配给块,这在本节中称为可分块内存(Chunkable Memory)。因此,PatrickStar提供了在运行时收集可分块内存统计信息的方法。
这些方案细节均在论文有详细介绍。
Conclusion
PatrickStar通过缩小非模型内存空间、提高内存效率和降低CPU-GPU通信量,支持更大的模型规模和更高的计算效率。
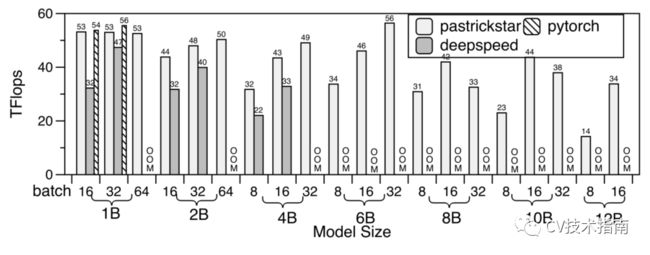
PyTorch、DeepSpeed和PatrickStar在同一GPU上的训练吞吐量。OOM表示超内存。
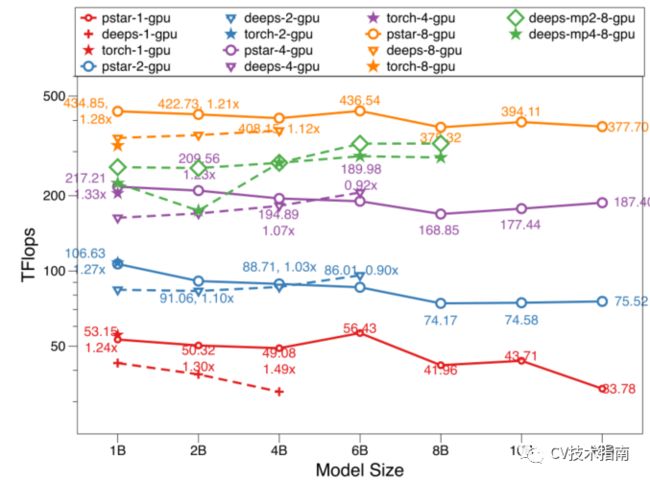
在多个GPU上使用DP训练PyTorch、DeepSpeed和PatrickStar的吞吐量。
论文提出了一种创新的异构训练系统,称为PatrickStar。它将模型数据组织成块,从而在异构存储空间中更灵活地编排它们。该系统与零冗余优化器数据并行是共生的。PatrickStar成功降低了PTM培训的硬件要求,并更高效地扩展到多个GPU。
在云计算平台的8xGPU 240 GB CPU节点上,它在最大模型规模上比SOTA提高了2倍,速度也比SOTA快。
未来的一些工作可以在PatrickStar上进行研究。
首先,通过对非模型数据检查点和卸载策略的联合优化,可以得到更好的块清除方法。其次,基于组块的异构方法可以与其他并行训练方法相结合进行多节点伸缩。
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料。

其它文章
ICCV2021 | PnP-DETR:用Transformer进行高效的视觉分析
ICCV2021 | 医学影像等小数据集的非自然图像领域能否用transformer?
ICCV2021 | Vision Transformer中相对位置编码的反思与改进
ICCV2021 | TransFER:使用Transformer学习关系感知的面部表情表征
2021-视频监控中的多目标跟踪综述
一文概括机器视觉常用算法以及常用开发库
统一视角理解目标检测算法:最新进展分析与总结
图像修复必读的 10 篇论文 | HOG和SIFT图像特征提取简述
给模型加入先验知识的常见方法总结 | 谈CV领域审稿
全面理解目标检测中的anchor | 实例分割综述总结综合整理版
HOG和SIFT图像特征提取简述 | OpenCV高性能计算基础介绍
目标检测中回归损失函数总结 | Anchor-free目标检测论文汇总
小目标检测的一些问题,思路和方案 | 小目标检测常用方法总结
2021年小目标检测最新研究综述
深度学习模型大小与模型推理速度的探讨
视频目标检测与图像目标检测的区别
CV算法工程师的一年工作经验与感悟
单阶段实例分割综述 | 语义分割综述 | 多标签分类概述
视频理解综述:动作识别、时序动作定位、视频Embedding
资源分享 | SAHI:超大图片中对小目标检测的切片辅助超推理库
Siamese network总结 | 计算机视觉入门路线
论文创新的常见思路总结 | 卷积神经网络压缩方法总结
神经网络超参数的调参方法总结 | 数据增强方法总结
归一化方法总结 | 又名"BN和它的后浪们"
Batch Size对神经网络训练的影响