10个2019年的机器学习和NLP的研究亮点
作者:Sebastian Ruder
编译:ronghuaiyang
导读
10个2019年的机器学习和NLP的研究亮点。

这篇文章收集了 10 个 ML 和 NLP 研究方向,我发现它们在 2019 年令人兴奋和有影响力。
每一个亮点,我总结了今年的主要进展,简要说明为什么我认为它是重要的,并提供了一个简短的展望未来。
完整的亮点列表如下:
普遍的无监督预训练。
彩票假说
神经正切核
无监督多语种学习
更多鲁棒的 benchmarks
科学上的机器学习和 NLP
修复 NLG 中的解码错误
预训练模型增强
高效和长期的 Transformers
更可靠的分析方法
1、普遍的无监督预训练
发生了什么事?今年 NLP 普遍存在无监督的预训练,主要由 BERT 和其他变体驱动。一系列的 BERT 变体已经应用于多模态设置,主要涉及图像和视频以及文本(如下图所示)。无监督的训练也侵入了以前监督占主导地位的领域。在生物学中,Transformer 语言模型已经被用在预训练蛋白质序列上。在计算机视觉中,自监督方法包括 CPC,MoCo,和 PIRL 研究了强大的生成模型,例如 BigBiGAN 来提高抽样效率和 ImageNet 和图像生成。在演讲中,使用多层 CNN 或双向 CPC 的方法得到了 state-of-the-art 的模型。
为什么它很重要?无监督的预训练使用很少的标注样本进行训练。这在许多不同的领域打开了新的应用,这些领域的数据需求以前是禁止的。
接下来是什么?无监督的训练将持续下去。虽然到目前为止在个别领域已经取得了最大的进展,但看到更多地集中于更紧密地综合多种模式将是有趣的。
2、彩票假说
发生了什么?Frankle 和 Carbin 发现了中奖彩票假说,在密集的、随机初始化的、前馈网络中的子网络,它们的初始化非常好,以至于单独训练它们可以达到与训练整个网络类似的精度,如下图所示。虽然最初的剪枝过程只适用于小的视觉任务,但是后来的工作将剪枝应用于早期的训练而不是初始化,这使得寻找更深层次模型的小的子网络成为可能。Yu 等人(2019)发现了 LSTMs 和 Transformers 在 NLP 和 RL 模型中的中奖初始化。虽然中奖彩票仍然在计算上很贵,但它们似乎可以在数据集和优化器之间迁移。
为什么它很重要?最先进的神经网络越来越大,训练和预测的成本也越来越高。能够始终如一地识别小的子网络,从而获得可比较的性能,这使得使用更少的资源进行训练和推理成为可能。这可以加速模型迭代,并在设备上和边缘计算中开辟新的应用。
接下来是什么?识别中奖彩票目前仍然计算上太贵,无法在资源匮乏的环境中提供真正的好处。更健壮的一次性剪枝方法在剪枝过程中对噪声的敏感性更低,应该可以缓解这一问题。研究中奖彩票的特别之处还有助于我们更好地理解神经网络的初始化和学习动态。

3、神经正切核
发生了什么?与直觉相反,非常宽(更具体地说,无限宽)的神经网络在理论上比窄神经网络更容易研究。结果表明,在无限宽极限下,神经网络可以近似为具有某种核的线性模型,即神经正切核(NTK)。参考这篇文章:https://rajatvd.github.io/NTK/可以得到对NTK的直观解释,包括它的训练动态的说明(见下图)。在实践中,这些模型表现不如有限深度模型,这限制了将研究结果应用于标准方法。近期工作已经大大减少了与标准方法的性能差距。
为什么它很重要?NTK 可能是我们所掌握的分析神经网络理论行为的最强大工具。虽然它有其局限性,即实用的神经网络仍然比 NTK 网络表现得更好,而且迄今为止的见解还没有转化为经验上的收获,但它可能有助于我们打开深度学习的黑盒子。
接下来是什么?与标准方法的差距似乎主要是由于这些方法的有限宽度的好处,这是未来的工作可能寻求的特点。这也将有助于将无限宽度限制的见解转化为实际的设置。最终,NTK 可能帮助我们阐明神经网络的训练动力学和泛化行为。
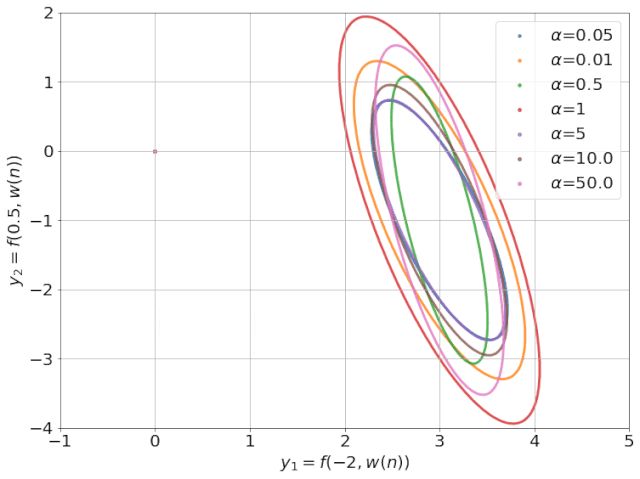
4、无监督多语种学习
发生了什么?多年来,跨语言表征主要集中在词汇层面。在无监督 pretraining 进步的基础上,今年看到了深度跨语言模型的开发等多语种 Bert, XLM 和 XLM-R。尽管这些模型没有使用任何显式的跨语言信号,但它们在跨语言之间的通用性惊人地好 —— 即使没有共享词汇或联合训练。这种深度模型也带来了无监督 MT 的改进,看到改进的原则性更强的组合统计和神经的方法。另一个令人兴奋的发展是,从现成的预训练的英语表示中,引导深层多语言模型,如下图所示。
为什么它很重要?即时可用的跨语言表示使模型的训练与较少的例子以外的语言的英语。此外,如果有英文标签数据,这些方法基本上可以实现零距离传输。它们可能最终帮助我们更好地理解不同语言之间的关系。
接下来是什么?在没有任何跨语言监督的情况下,这些方法为何能如此有效仍不清楚。更好地理解这些方法是如何工作的,可能会使我们设计出更强大的方法,也可能揭示出关于不同语言结构的见解。此外,我们不仅应该关注零样本迁移,还应该考虑从目标语言中少数有标签的例子中学习。
5、更加鲁棒的 benchmarks
发生了什么事?最近的 NLP 数据集,如 HellaSWAG 对于最先进的模型也是很难的。样本由人工筛选,以明确保留那些最先进的模型失败的样本(参见下面的示例)。这种把人包括在循环中的对抗管理过程可以重复多次,例如在最近的对抗 NLI 基准测试中,使创建数据集对当前方法更具挑战性。
为什么它很重要?许多研究人员发现,目前的 NLP 模型没有学习它们应该学习的内容,而是采用了浅层的启发方法,利用数据中的浅层线索。随着数据集变得更加健壮,我们希望模型最终能够了解数据中真正的底层关系。
接下来是什么?随着模型的改进,大多数数据集需要不断改进,否则很快就会过时。将需要专用的基础设施和工具来促进这一进程。此外,应该运行适当的基线,包括使用不同数据变体的简单方法和模型(例如不完整的输入),以便数据集的初始版本尽可能健壮。

6、科学中的机器学习和 NLP
发生了什么?在应用于基础科学问题方面已经取得了一些重大进展。我的研究重点是深度神经网络在蛋白质折叠和多电子薛定谔方程中的应用。在 NLP 方面,看到标准方法与领域专家相结合所产生的影响是令人兴奋的。一项研究使用词嵌入来分析材料科学文献中的潜在知识,可以用来预测哪些材料将具有某些特性(见下图)。在生物学中,许多数据如基因和蛋白质在本质上是连续的。因此,它自然适合于 LSTMs 和 transformer 等 NLP 方法,这些方法已被应用于蛋白质分类。
为什么它很重要?科学可以说是 ML 最有影响力的应用领域之一。解决方案可以对许多其他领域产生很大的影响,并可以帮助解决实际问题。
接下来是什么?从物理问题中的能量建模到微分方程求解。到 2020 年,看看这些措施中最具影响力的将是什么,将是一件有趣的事情。
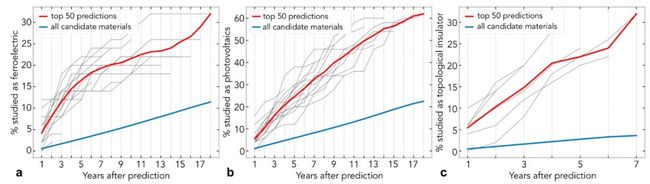
7、修复 NLG 中的解码错误
发生了什么事?尽管自然语言生成(NLG)模型的功能越来越强大,但它仍然经常产生重复或胡言乱语,如下图所示。这主要是最大似然训练的结果。我很高兴看到旨在改善这一点的改进,并且与建模的进展是正交的。这些改进以新的抽样方法的形式出现,比如核抽样和新的损失函数。另一个令人惊讶的发现是,更好的搜索并不能产生更好的结果:当前的模型在一定程度上依赖于不完美的搜索和波束搜索错误。相反,在机器翻译的情况下,精确搜索通常会返回空翻译。这表明,搜索和建模方面的进步必须经常携手并进。
为什么它很重要?自然语言生成是自然语言处理中最基本的任务之一。在 NLP 和 ML 的研究中,大多数论文都集中在对模型的改进上,而其他部分的 pipeline 往往被忽略。对 NLG 来说,重要的是要提醒我们自己,我们的模型仍然有缺陷,可能通过修正搜索或训练过程来改进输出。
接下来是什么?尽管有更强大的模型和成功的应用转移学习到 NLG,模型预测仍然包含许多人工干预。识别和了解这些人工干预的成因是一个重要的研究方向。

8、预训练模型增强
发生了什么事?我很兴奋地看到方法,装备了预训练的模型的新能力。有些方法利用知识库来增强预训练的模型,以改进实体命名的建模。其他的还有通过给它访问一些预定义的可执行程序,让模型能够执行简单的算术推理。因为大多数模型和对于他们学习的大部分知识数据有一个微弱的偏差,扩展 pretrained 模型的另一种方法是通过增加训练数据本身,如捕捉常识。
为什么它很重要?模型正变得越来越强大,但有许多事情是模型不能单独从文本中学习的。特别是在处理更复杂的任务时,可用的数据可能太有限,无法使用事实或常识进行明确的推理,因此可能需要更强的归纳偏见。
接下来是什么?随着模型被应用于更有挑战性的问题,越来越有必要对模型进行组合性的修改。在未来,我们可能会将强大的预训练模型与可学习的组合程序相结合。

9、高效和长期的 Transformers
发生了什么 ?这一年看到的 Transformer 改进。Transformer-XL 和压缩的 Transformer 可以更好的获取长期的依赖关系。有一些方法让 Transformer 更加的高效,比如使用 sparse 和 attention 的方法,或者 adaptively sparse attention,adaptive attention spans,product-key attention,locality-sensitive hashing。在基于 Transformer 的预训练阵线上,有更加高效的变体 ALBERT,使用了参数共享和 ELECTRA,使用了更加高效的预训练任务。也有没有使用 Transformer 的更加高效的预训练模型,比如 unigram document 模型 VAMPIRE 和 QRNN-based MultiFiT。另外一个趋势是将大的 BERT 蒸馏成更小的模型。
为什么它很重要?Transformer 自产生以来就影响广泛。一直是大多数的 state-of-the-art 模型的一部分,在 NLP 和广泛的领域中都有着成功的应用。对 Transformer 的任何改进都会有强大的连带效应。
接下来是什么?这些改进需要一些时间来渗透到从业人员中,但它提供了优先级和更容易使用的预训练模型,更有效的替代方案将很快被采用。除此之外,我们将看到继续关注模型架构的效率,透明度是一个关键趋势。
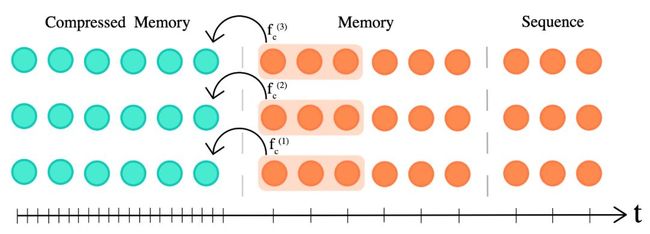
10、更可靠的分析方法
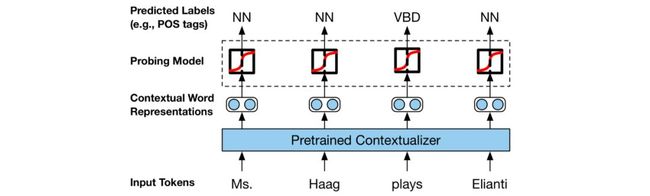
发生了什么事?今年的一个主要趋势是分析模型的论文数量不断增加。事实上,我今年最喜欢的几篇论文就是这样的分析论文。早期的一个亮点是 Belinkov 和 Glass(2019)]对分析方法的优秀调研。今年也是(在我的记忆中)第一次有许多论文致力于分析单个模型,这样的论文被称为 BERTology。可靠性也是正在进行的关于注意力是否能提供有意义的解释的讨论中的一个主题。对分析方法的持续兴趣最好的例证可能是关于 NLP 中模型的可解释性和分析的新 ACL 2020 track。
为什么它很重要?最先进的方法被用作黑盒。为了开发更好的模型并在现实世界中使用它们,我们需要理解为什么模型会做出某些决策。然而,我们目前解释模型预测的方法仍然有限。
接下来是什么?我们需要做更多的工作来解释那些超出想象的预测,因为想象通常是不可靠的。这一方向的一个重要趋势是,越来越多的数据集提供了人写的解释。

—END—
英文原文:https://ruder.io/research-highlights-2019/