Intel发布神经网络压缩库Distiller:快速利用前沿算法压缩PyTorch模型
Intel发布神经网络压缩库Distiller:快速利用前沿算法压缩PyTorch模型
近日,Intel 开源了一个用于神经网络压缩的开源 Python 软件包 Distiller,它可以减少深度神经网络的内存占用、加快推断速度及节省能耗。Distiller 为 PyTorch 环境提供原型和分析压缩算法,例如产生稀疏性张量的方法和低精度运算等。
项目地址:https://github.com/NervanaSystems/distiller/
文档地址:https://nervanasystems.github.io/distiller/index.html
深度学习正快速发展,它从输入法到汽车已经应用到各种场景和设备当中。但它们所采用的深度神经网络在运算时间、计算力、内存和能耗上都有非常大的需求。很多开发者考虑到硬件和软件的限制及实际应用的环境,而在算法准确度、速度和功耗之间取得平衡。近日,Intel 人工智能实验室开源了 Neural Network Distiller,它是一个为神经网络压缩算法研究而设计的 Python 包。Intel 认为深度网络的压缩可以成为促进更多的研究成果投入应用,并实现更优秀的功能。
深度网络压缩
面向用户的深度学习应用需要高度重视用户体验,因为交互式的应用通常对程序的响应时间非常敏感。谷歌的内部研究发现即使很小的服务响应延迟,它对用户的影响也非常显著。而随着越来越多的应用由深度模型提供核心功能,不论我们将模型部署在云端还是移动端,低延迟的推断变得越来越重要。
减少计算资源和加快推断速度的一种方法是从一开始就设计一种紧凑型的神经网络架构。例如 SqueezeNet 和 MobileNet 都旨在压缩参数数量与计算量的情况下尽可能保留较高的准确度,而 Intel 人工智能实验室也在设计这种紧凑型的模型,即提出了一种用于深层 DNN 的无监督结构学习方法,以获得紧凑的网络结构与高准确率。
而另一种降低计算力需求的方法直接从通用且性能优秀的深度网络架构开始,然后通过一些算法过程将其转换为更加短小精悍的网络,这种方法即神经网络压缩。
神经网络压缩是降低计算力、存储空间、能耗、内存和推断时间等需求的过程(至少其一),它同时还需要保持其推断准确性不下降或在可接受的范围内。通常这些资源是相互关联的,减少一种资源的需求同时会降低其它资源的需求。此外,即使我们使用前面几种紧凑的小模型,我们同样可以使用压缩算法进一步减少计算资源的需求。
其实很多研究都表明深度神经网络存在着非常高的参数冗余,虽然这些参数冗余在收敛到更优解时是非常必要的,但在推断过程中可以大量减少参数与计算量。总体而言,绝大多数压缩方法在于将巨大的预训练模型转化为一个精简的小模型,且常用的方法有低秩近似、神经元级别的剪枝、卷积核级别的剪枝、参数量化及知识蒸馏等。
例如在量化这一常见的压缩算法中,我们只需储存 k 个聚类中心 c_j,而原权重矩阵只需要记录各自聚类中心的索引就行。在韩松 ICLR 2016 的最佳论文中,他用如下一张图非常形象地展示了量化的概念与过程。
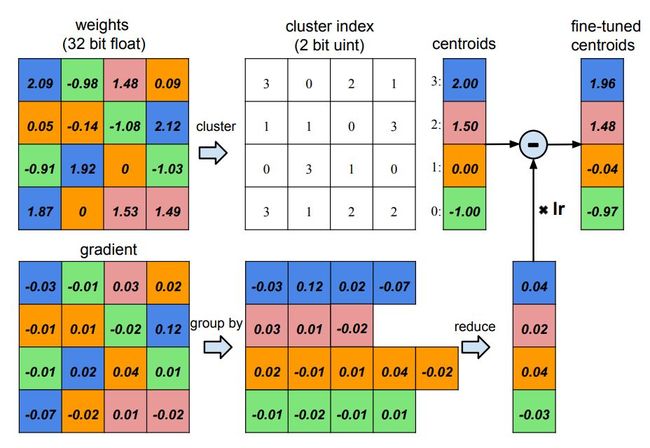
如上所示权重矩阵的所有参数可以聚类为 4 个类别,不同的类别使用不同的颜色表示。上半部分的权重矩阵可以取聚类中心,并储存在 centroids 向量中,随后原来的权重矩阵只需要很少的空间储存对应的索引。下半部是韩松等研究者利用反向传播的梯度对当前 centroids 向量进行修正的过程。这种量化过程能大量降低内存的需求,因为我们不再需要储存 FP64 或 FP32 的数据,而只需要储存 INT8 或更少占位的数据。
Distiller 简介
Intel 主要根据以下特征和工具构建了 Distiller:
-
集成了剪枝、正则化和量化算法的框架
-
分析和评估压缩性能的一组工具
-
当前最优压缩算法的示例实现
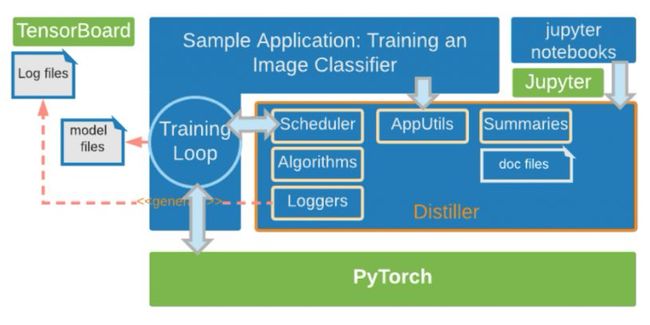
剪枝和正则化是两种可以令深度网络参数张量产生稀疏性的方法,其中稀疏性度量的是参数张量中有多少数值精确为 0。稀疏张量可以更紧凑地储存在内存中,并且可以减少执行 DNN 运算所需要的计算量和能耗。量化是另一种减少 DNN 中数据精度的方法,它同样会减少内存、能耗和计算力需求。Distiller 为量化、剪枝(结构化剪枝和细粒度剪枝)和诱导稀疏性的正则化等方法提供了越来越多的当前最优算法,并支持训练更快、更紧凑和更节能的模型。
为了帮助研究者更专注于它们的任务,Intel 尝试提供一些大多数研究者都需要了解的压缩算法,并同时提供了高级和底层函数以方便使用。例如:
-
剪枝方法在深度网络经过训练后,动态地从卷积网络层级移除卷积核与通道。Distiller 将在目标层配置中执行这些变化,并且同时对网络的参数张量做剪枝。此外,Distiller 还将分析模型中的数据依赖性,并在需要时修改依赖层。
-
Distiller 可以自动对模型执行量化操作,即使用量化后的层级副本替代具体的层级类型。这将节省手动转换每一个浮点模型为低精度形式的工作,并允许我们专注于开发量化方法,且在多种模型中扩展和测试它。
Intel 已经通过 Jupyter Notebook 介绍并展示如何从网络模型和压缩过程中访问统计信息。例如,如果我们希望移除一些卷积核,那么可以运行用于滤波器剪枝敏感性分析的模块,并得到类似以下的结果:
Jupyter Notebook 地址:https://nervanasystems.github.io/distiller/jupyter/index.html
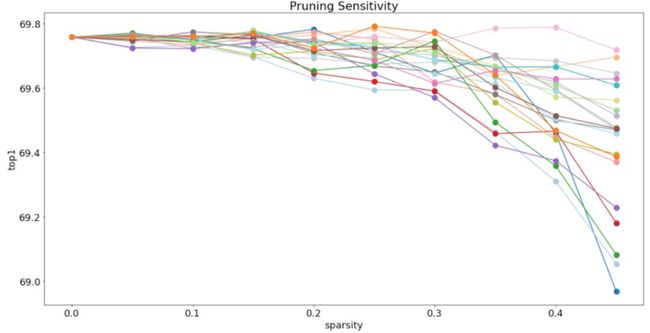
Distiller 的统计数据可导出为 Pandas DataFrames,它可用于数据选择(索引和截取等)和可视化。
Distiller 还展示了一些示例应用,并使用量化和剪枝等方法压缩图像分类网络和语言模型。Distiller 还实现了一些神经网络压缩的前沿研究论文,它们也可以作为我们尝试新方法的模板。此外,我们也可以在官方 PyTorch 深度预训练模型上使用这些压缩算法,以降低计算资源的需求。
Distiller 压缩示例:https://nervanasystems.github.io/distiller/model_zoo/index.html
这只是个开始
Distiller 是一个用于压缩算法研究的库,它致力于帮助科学家和工程师训练并部署 DL 的解决方案、帮助发布研究论文以及促进算法更新与创新。Intel 目前也在添加更多的算法、特征和应用领域,如果读者对于研究并实现 DNN 压缩算法很感兴趣,也可以帮助改进并提升 Distiller 库。最后,Distiller 非常欢迎新的想法与深度网络压缩算法,同时也希望开发者能多发现该库的 Bug。
[1] Forrest N. Iandola, Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally and Kurt Keutzer. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size.」_arXiv:1602.07360 (https://arxiv.org/abs/1602.07360)_ [cs.CV]
[2] Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto and Hartwig Adam. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. (_https://arxiv.org/abs/1704.04861_).
[3] Michael Zhu and Suyog Gupta,「To prune, or not to prune: exploring the efficacy of pruning for model compression」, 2017 NIPS Workshop on Machine Learning of Phones and other Consumer Devices (_https://arxiv.org/pdf/1710.01878.pdf_)
[4] Sharan Narang, Gregory Diamos, Shubho Sengupta, and Erich Elsen. (2017).「Exploring Sparsity in Recurrent Neural Networks.」(_https://arxiv.org/abs/1704.05119_)
[5] Raanan Y. Yehezkel Rohekar, Guy Koren, Shami Nisimov and Gal Novik.「Unsupervised Deep Structure Learning by Recursive Independence Testing.」, 2017 NIPS Workshop on Bayesian Deep Learning (_http://bayesiandeeplearning.org/2017/papers/18.pdf_).
转自:
机器之心