马尔可夫链蒙特卡洛采样(MCMC)
首先我们要明确的是马尔可夫链蒙特卡洛采样以下简称MCMC,它首先是个采样方法。
1.采样的目的
- 采样作为任务,用于生成新的样本
- 求和/求积分
比如我们知道样本z的后验分布![]() ,我们经常会有一个需求,得到目标函数f(x)在概率分布上的期望,通常这个期望是很难计算的,我们可以根据p(z|x)采用N个样本,分别为
,我们经常会有一个需求,得到目标函数f(x)在概率分布上的期望,通常这个期望是很难计算的,我们可以根据p(z|x)采用N个样本,分别为![]() ,当N足够大我们便可以得到该期望值。如下式:
,当N足够大我们便可以得到该期望值。如下式:

也就是说,从概率分布中c采样点,从而近似计算这个积分。
采样结束后,我们需要评价采样出来的样本点是不是好的样本集:
- 样本趋向于高概率的区域
- 样本之间必须独立
2.常见的采样方法
1.概率分布采样
首先求得概率密度的累积密度函数 CDF,然后求得 CDF 的反函数如下图,在0到1之间均匀采样,代入反函数,就得到了采样点。但是实际大部分概率分布不能得到 CDF。
2.Rejection Sampling 拒绝采样
对于概率分布 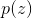 引入简单的提议分布
引入简单的提议分布 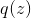 使得任意存在一个
使得任意存在一个![]() ,使得
,使得![]() ,为啥要这样做呢?我们知道一个概率分布函数在[0,1]上的积分一定为0,即一个概率分布函数不可能永远在一个在另一个概率分布函数上方,但是如果是M倍就完全满足。
,为啥要这样做呢?我们知道一个概率分布函数在[0,1]上的积分一定为0,即一个概率分布函数不可能永远在一个在另一个概率分布函数上方,但是如果是M倍就完全满足。
具体做法:
1.首先定义接受率:
2.我们先在p(z) 中采样
3.在均匀分布[0,1]中选取 u
4.如果
,则接受这个采样
,否则丢弃这个采样,不要了。
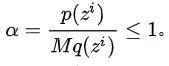
3.Importance Sampling(重要性采样)
直接对下面期望进行采样进行采样,当我们要计算 在上的期望时,我们引入一个区别于不同的分布,这样就可以把
在上的期望时,我们引入一个区别于不同的分布,这样就可以把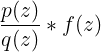 看成
看成 ,然后在这个上采样
,然后在这个上采样![]() ,从而使得在上很难采样转换到一个很好采样的上,即:
,从而使得在上很难采样转换到一个很好采样的上,即:
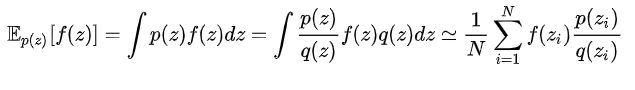
3.MCMC采样
大概思想:构建一个马尔可夫链式,马尔可夫链式是一种时间状态都是离散的随机变量序列。我们关注的主要是齐次一阶马尔可夫链,就是当前状态只与前一个状态有关,与前面的其他状态都无关:
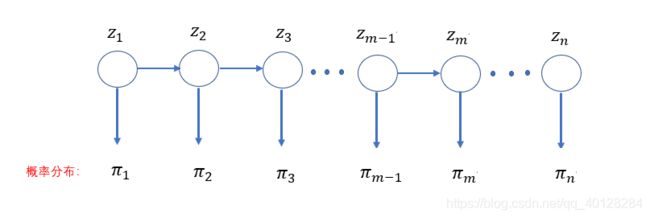
马尔可夫链式有个特性,就是从一个转态 开始,后面每个状态的概率分布都变成一致,就是平稳分布,这里令我们的要采样的概率分布等于这个平稳分布,
开始,后面每个状态的概率分布都变成一致,就是平稳分布,这里令我们的要采样的概率分布等于这个平稳分布,![]() ,这时我们可以依次采样
,这时我们可以依次采样![]() ,然后根据状态转移矩阵,依次采样剩下的所有样本,还未达到平稳分布之前采样得到的样本全都舍弃,剩下的样本就等价从这个概率分布采样得到的样本。
,然后根据状态转移矩阵,依次采样剩下的所有样本,还未达到平稳分布之前采样得到的样本全都舍弃,剩下的样本就等价从这个概率分布采样得到的样本。
看到这可能还是不能理解,下面我举一个在网上看到的例子:社会学家经常把人按其经济状况分成3类:下层(lower-class)、中层(middle-class)、上层(upper-class),我们用1、2、3 分别代表这三个阶层。社会学家们发现决定一个人的收入阶层的最重要的因素就是其父母的收入阶层。如果一个人的收入属于下层类别,那么他的孩子属于下层收入的概率是 0.65, 属于中层收入的概率是 0.28, 属于上层收入的概率是 0.07。事实上,从父代到子代,收入阶层的变化的转移概率如下:
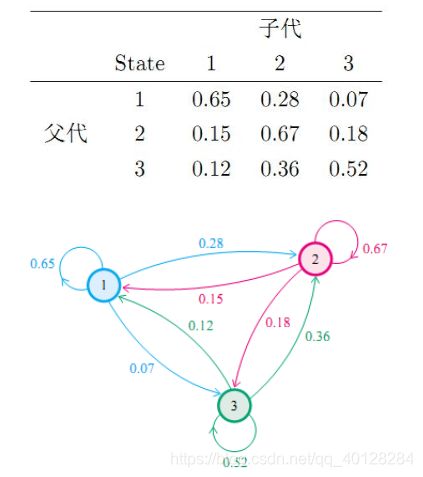
使用矩阵的表示方式,转移概率矩阵记为: 。
。
假设当前这一代人处在下层、中层、上层的人比例是概率分布向量![]() ,那么他们的子女的分布比例将是
,那么他们的子女的分布比例将是![]() ,他们的孙子代的分布比例将是
,他们的孙子代的分布比例将是![]() ,如此下去...............,那么我们可知第
,如此下去...............,那么我们可知第 代子孙的收入分布比例将是
代子孙的收入分布比例将是![]() ,假设初始概率分布为
,假设初始概率分布为![]() ,则我们可以计算前代人的分布状况如下:
,则我们可以计算前代人的分布状况如下:
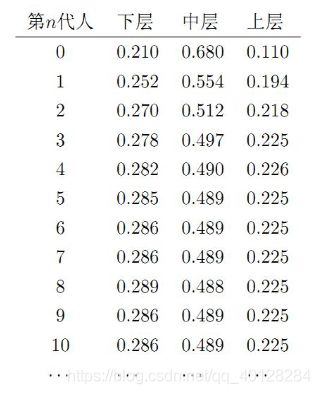
从上面的分布状况表中,我们发现从第7代人开始,这个分布就稳定不变了;事实上,在这个问题中,从任意初始概率分布开始都会收敛到这个上面这个稳定的结果。 对应我们构建的马尔可夫链式不管最初的分布是啥?都能收敛到我们需要采样的分布
下面来介绍啥是状态转移矩阵:
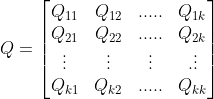
假设我们在马尔可夫模型中,每个节点都有 个状态,即:
个状态,即:![]() ,定义我们的状态转移矩阵为:
,定义我们的状态转移矩阵为:
 其中
其中![]()
通俗来讲就是每一项都是一个条件概率。
如此,我们便有了采样的大体思路:假设最初的概率分布为
,且每个属性都是2值属性(0,1),即
p 0.2 0.7 0.1 根据此概率分布,我们假设的采样为
,根据状态转移矩阵
很容易得到
的概率分布,再从该概率分布采样,如此下去,马尔可夫链每个节点的值都能采样取得,这时只要确定从哪个节点开始其概率分布达到了平稳分布,前面节点的采样丢弃,后面节点采样的结果便可看成从
但是问题又来了,我咋判断到达了平稳分布呢?其实如果达到平稳分布了,一定满足如下细致平衡式子:
![]()
如果一个分布满足细致平衡,那么一定满足平稳分布(反之不成立),这个切记。
细致平衡条件将平稳分布的序列和马尔可夫链的转移矩阵联系在一起了,通过转移矩阵可以不断生成样本点。假定随机取一个转移矩阵 Q,作为一个提议矩阵。我们有:
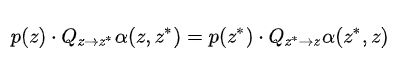
其中这个![]() 我随机给定,相当于就是已知的,后面
我随机给定,相当于就是已知的,后面 ,我们取:
,我们取:
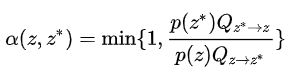
则:
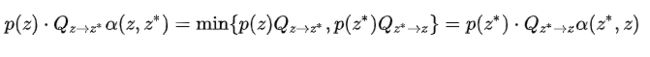
于是,迭代就得到了序列,这个算法叫做 Metropolis-Hastings 算法,具体做法如下:
1.在[0,1]均匀分布取一个点。
2.随机取
,进行采样。
3.计算
即:
4.
这样的样本就服从:p(z)
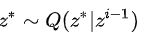
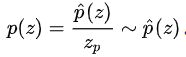
4.Gibbs 采样
下面介绍另一种采样方式 Gibbs 采样,上述采样如果维度很高,采样便很难进行,下面引入Gibbs ,那么通过固定被采样的维度其余的维度来简化采样过程,即:
![]()
思想:其实思想很简单,就当采样的时候,一个维度一个维度采样,在第i个维度采样,先确定其他维度的值不变.
- 步骤:
1.给定初始值
.
2.在t+1时刻,采样:
从一个维度一个维度采样。
- 例子:
假设随机变量的维度为3,即
t时刻:
t+1时刻的采样:
Gibbs 采样其实是一种特殊的MH方法,这里不证明。