数学之美读书笔记--摘抄
![]() “系列一: 统计语言模型”
“系列一: 统计语言模型”
“利用统计语言模型进行语言处理”
“假定任意一个词wi的出现概率只同它前面的词 wi-1 有关(即马尔可夫假设)”
P(S) = P(w1)P(w2|w1)P(w3|w2)…P(wi|wi-1)…
![]() “系列 二——谈谈中文分词”
“系列 二——谈谈中文分词”
“最少词数的分词理论”--》解决二义性--〉“计算出每种分词后句子出现的概率,并找出其中概率最大的”--》“中文分词的方法也被应用到英语处理,主要是手写体识别中”
![]() “系列 三——隐含马尔可夫模型在语言处理中的应用”
“系列 三——隐含马尔可夫模型在语言处理中的应用”
语音识别、机器翻译、字体识别


![]() “系列 四——怎样度量信息?”
“系列 四——怎样度量信息?”
信息熵--信息度量等于不确定性的多少,
“变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。”
![]() “系列五 -- 简单之美:布尔代数和搜索引擎的索引”
“系列五 -- 简单之美:布尔代数和搜索引擎的索引”
“最大好处是容易实现,速度快,这对于海量的信息查找是至关重要的。它的不足是只能给出是与否的判断,而不能给出量化的度量。”
![]() 系列六:图论和网络爬虫 (Web Crawlers)
系列六:图论和网络爬虫 (Web Crawlers)
遍历、超链接、网络爬虫:
“我们来看看网络爬虫如何下载整个互联网。假定我们从一家门户网站的首页出发,先下载这个网页,然后通过分析这个网页,可以找到藏在它里面的所有超链接,也就等于知道了这家门户网站首页所直接连接的全部网页,诸如雅虎邮件、雅虎财经、雅虎新闻等等。我们接下来访问、下载并分析这家门户网站的邮件等网页,又能找到其他相连的网页。我们让计算机不停地做下去,就能下载整个的互联网。当然,我们也要记载哪个网页下载过了,以免重复。在网络爬虫中,我们使用一个称为“ 哈希表 ”(Hash Table)的列表而不是一个记事本纪录网页是否下载过的信息。 ”
![]() “系列七:信息论在信息处理中的应用”
“系列七:信息论在信息处理中的应用”
信息熵--“语言模型是为了用上下文预测当前的文字,模型越好,预测得越准,那么当前文字的不确定性就越小。 可用于衡量
又称为语言模型复杂度
“互信息”--是信息熵的引申概念,它是对两个随机事件相关性的度量。”
解决二义性问题--
“首先从大量文本中找出和总统布什一起出现的互信息最大的一些词,比如总统、美国、国会、华盛顿等等,当然,再用同样的方法找出和灌木丛一起出现的互信息最大的词,比如土壤、植物、野生等等。有了这两组词,在翻译 Bush 时,看看上下文中哪类相关的词多就可以了。”
“相对熵用来衡量两个正函数是否相似,对于两个完全相同的函数,它们的相对熵等于零。在自然语言处理中可以用相对熵来衡量两个常用词(在语法上和语义上)是否同义,或者两篇文章的内容是否相近等等。利用相对熵,我们可以到处信息检索中最重要的一个概念:词频率-逆向文档频率(TF/IDF)。”
![]() “系列八:贾里尼克的故事和现代语言处理”
“系列八:贾里尼克的故事和现代语言处理”
![]() “系列九:如何确定网页和查询的相关性”
“系列九:如何确定网页和查询的相关性”
相关性:
根据网页的长度,对关键词的次数进行归一化,也就是用关键词的次数除以网页的总字数。我们把这个商称为“关键词的频率”,或者“单文本词汇频率“
“假定一个关键词 w 在 Dw 个网页中出现过,那么 Dw 越大,w 的权重越小”
![]() “系列十:有限状态机和地址识别”
“系列十:有限状态机和地址识别”
“使用有限状态机识别地址,关键要解决两个问题,即通过一些有效的地址建立状态机,以及给定一个有限状态机后,地址字串的匹配算法。”
严格匹配---模糊匹配(当用户输入的地址不太标准或者有错别字时,有限状态机会束手无策,因为它只能进行严格匹配)
-----“基于概率的有限状态机和离散的马尔可夫链”
![]() “系列十二:余弦定理和新闻的分类”
“系列十二:余弦定理和新闻的分类”
用向量描述新闻---如果两篇新闻的特征向量相近,则对应的新闻内容相似,它们应当归在一类,反之亦然。
用余弦定理计算向量夹角与方向
![]() “系列十三:信息指纹及其应用
“系列十三:信息指纹及其应用
“网络爬虫在下载网页时,它将访问过的网页的网址都变成一个个信息指纹,存到哈希表中,每当遇到一个新网址时,计算机就计算出它的指纹,然后比较该指纹是否已经在哈希表中,来决定是否下载这个网页。”
信息指纹--不可逆
“一个网站可以根据用户的Cookie 识别不同用户,这个 cookie 就是信息指纹。但是网站无法根据信息指纹了解用户的身份,这样就可以保护用户的隐私。”
![]() “系列十六:不要把所有的鸡蛋放在一个篮子里 -- 谈谈最大熵模型”
“系列十六:不要把所有的鸡蛋放在一个篮子里 -- 谈谈最大熵模型”
“我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。(不做主观假设这点很重要。)在这种情况下,概率分布最均匀,预测的风险最小。因为这时概率分布的信息熵最大,所以人们称这种模型叫“最大熵模型”。”
模型训练--通用迭代算法
“1. 假定第零次迭代的初始模型为等概率的均匀分布。
2. 用第 N 次迭代的模型来估算每种信息特征在训练数据中的分布,如果超过了实际的,就把相应的模型参数变小;否则,将它们便大。
3. 重复步骤 2 直到收敛。”
缺点:计算量大
改进:“将上下文信息、词性(名词、动词和形容词等)、句子成分(主谓宾)通过最大熵模型结合起来,”
![]() “系列十七:闪光的不一定是金子 谈谈搜索引擎作弊问题(Search Engine )”
“系列十七:闪光的不一定是金子 谈谈搜索引擎作弊问题(Search Engine )”
“搜索引擎的作弊者所作的事,就如同在手机信号中加入了噪音,使得搜索结果的排名完全乱了。但是,这种人为加入的噪音并不难消除,因为作弊者的方法不可能是随机的(否则就无法提高排名了)。而且,作弊者也不可能是一天换一种方法,即作弊方法是时间相关的。因此,搞搜索引擎排名算法的人,可以在搜集一段时间的作弊信息后,将作弊者抓出来,还原原有的排名。当然这个过程需要时间,就如同采集汽车发动机噪音需要时间一样,在这段时间内,作弊者可能会尝到些甜头。因此,有些人看到自己的网站经过所谓的优化(其实是作弊),排名在短期内靠前了,以为这种所谓的优化是有效的。但是,不久就会发现排名掉下去了很多。这倒不是搜索引擎以前宽容,现在严厉了,而是说明抓作弊需要一定的时间,以前只是还没有检测到这些作弊的网站而已。
”
![]() “系列十八:矩阵运算和文本处理中的分类问题”
“系列十八:矩阵运算和文本处理中的分类问题”
分析新闻相关性:1.余弦相似定理--时间长
2.“矩阵运算中的奇异值分解”--
“首先,我们可以用一个大矩阵A来描述这一百万篇文章和五十万词的关联性。这个矩阵中,每一行对应一篇文章,每一列对应一个词。
“奇异值分解就是把上面这样一个大矩阵,分解成三个小矩阵相乘”
“第一个矩阵X中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大越相关。最后一个矩阵Y中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。中间的矩阵则表示类词和文章雷之间的相关性。”
![]() “系列十九:马尔可夫链的扩展 贝叶斯网络 ”
“系列十九:马尔可夫链的扩展 贝叶斯网络 ”
“系列二十一:布隆过滤器(Bloom Filter)”
存储信息---哈希表--空间要求高、慢--布隆过滤器--好处在于快速,省空间。但是有一定的误识别率。常见的补救办法是在建立一个小的白名单,存储那些可能别误判的邮件地址。
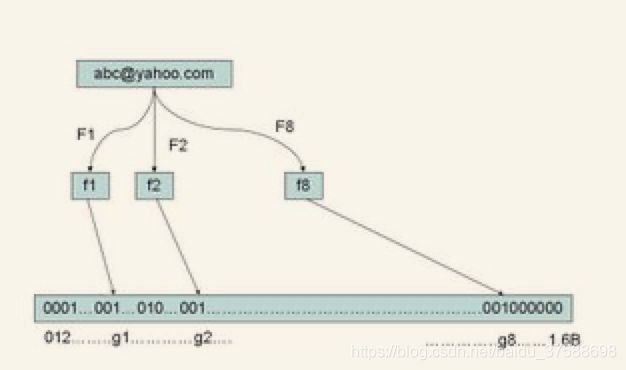
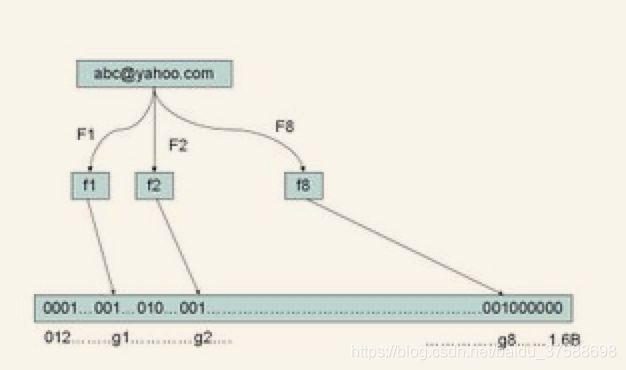
“让我们看看如何用布隆过滤器来检测一个可疑的电子邮件地址 Y 是否在黑名单中。我们用相同的八个随机数产生器(F1, F2, ..., F8)对这个地址产生八个信息指纹 s1,s2,...,s8,然后将这八个指纹对应到布隆过滤器的八个二进制位,分别是 t1,t2,...,t8。如果 Y 在黑名单中,显然,t1,t2,..,t8 对应的八个二进制一定是一。这样在遇到任何在黑名单中的电子邮件地址,我们都能准确地发现。”
![]() “系列二十二:由电视剧《暗算》所想到的 — 谈谈密码学的数学原理”
“系列二十二:由电视剧《暗算》所想到的 — 谈谈密码学的数学原理”
凯撒密码--频率破译
对称加密--非对称加密--公钥私钥
![]() “系列 二十三 输入一个汉字需要敲多少个键 — 谈谈香农第一定律”
“系列 二十三 输入一个汉字需要敲多少个键 — 谈谈香农第一定律”
“香农第一定理指出:这个编码的长度的最小值是汉字的信息熵,也就是说任何输入方面不可能突破信息熵给定的极限。”
“如果我们把汉字组成词,再以词为单位统计信息熵,那么,每个汉字的平均信息熵将会减少。”
“再考虑上下文的相关性,对汉语建立一个基于词的 统计语言模型 ,我们可以将每个汉字的信息熵降到 6 比特作用”
“不容易达到信息论极限的输入速度的原因在于”
- “输入方法提供给用户的是一个压缩的很厉害的语音模型,而有的输入方法为了减小内存占用,根本没有语言模型。拼音输入法的好坏关键在准确而有效的语言模型。 ”
- “从认知科学的角度上讲,人一心无二用,人们在没有稿子边想边写的情况下不太可能在回忆每个词复杂的编码的同时又不中断思维。”
![]() “二十四 从全球导航到输入法——谈谈动态规划”
“二十四 从全球导航到输入法——谈谈动态规划”
“从第一个字到最后一个字可以组成很多很多句子,我们的拼音输入法就是要根据上下文找到一个最优的句子。如果我们再将上下文的相关性量化,作为从前一个汉字到后一个汉字的距离,那么,寻找给定拼音条件下最合理句子的问题就变成了一个典型的“最短路径”问题,我们的算法就是动态规划。”