AUC原理详细讲解
一、AUC含义
首先,在试图弄懂AUC和ROC曲线之前,首先要彻底理解混淆矩阵的定义!
混淆矩阵中有着Positive、Negative、True、False的概念,其意义如下:
- 称预测类别为1的为Positive(阳性),预测类别为0的为Negative(阴性)。
- 预测正确的为True(真),预测错误的为False(伪)。
对上述概念进行组合,就产生了如下的混淆矩阵:

然后,由此引出True Positive Rate(真阳率)、False Positive(伪阳率)两个概念:
T P R a t e = T P T P + F N TP_{Rate} = \frac{TP}{TP+FN} TPRate=TP+FNTP
F P R a t e = F P F P + T N FP_{Rate} = \frac{FP}{FP+TN} FPRate=FP+TNFP
仔细看这两个公式,发现其实 T P R a t e TP_{Rate} TPRate就是 T P TP TP除以 T P TP TP所在的列, F P R a t e FP_{Rate} FPRate就是 F P FP FP除以 F P FP FP所在的列,二者意义如下:
- T P R a t e TP_{Rate} TPRate的意义是所有真实类别为1的样本中,预测类别为1的比例。
- F P R a t e FP_{Rate} FPRate的意义是所有真实类别为0的样本中,预测类别为1的比例。
如果上述概念都弄懂了,那么ROC曲线和AUC就很容易理解了:
按照定义,AUC即ROC曲线下的面积,而ROC曲线的横轴是 F P R a t e FP_{Rate} FPRate,纵轴是 T P R a t e TP_{Rate} TPRate,当二者相等时,即y=x,如下图:

表示的意义是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的。
换句话说,分类器对于正例和负例毫无区分能力,和抛硬币没什么区别,一个抛硬币的分类器是我们能想象的最差的情况,因此一般来说我们认为AUC的最小值为0.5(当然也存在预测相反这种极端的情况,AUC小于0.5,这种情况相当于分类器总是把对的说成错的,错的认为是对的,那么只要把预测类别取反,便得到了一个AUC大于0.5的分类器)。
而我们希望分类器达到的效果是:对于真实类别为1的样本,分类器预测为1的概率(即 T P R a t e TP_{Rate} TPRate),要大于真实类别为0而预测类别为1的概率(即 F P R a t e FP_{Rate} FPRate),即 y > x y>x y>x,因此大部分的ROC曲线长成下面这个样子:

最理想的情况下,既没有真实类别为1而错分为0的样本—— T P R a t e TP_{Rate} TPRate一直为1,也没有真实类别为0而错分为1的样本—— F P r a t e FP_{rate} FPrate一直为0,AUC为1,这便是AUC的极大值。
下面举个简单的例子。
首先对于硬分类器(例如SVM,NB,LR),预测类别为离散标签,对于8个样本的预测情况如下:

得到混淆矩阵如下:

进而算得 T P R a t e TP_{Rate} TPRate=3/4, F P R a t e FP_{Rate} FPRate=2/4,得到ROC曲线:
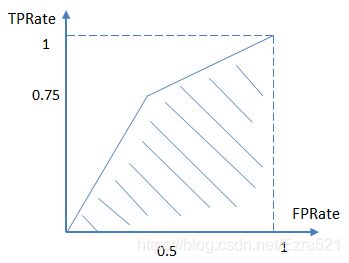
最终得到AUC为0.625。
对于LR等预测类别为概率的分类器,依然用上述例子,假设预测结果如下:

这时,需要设置阈值来得到混淆矩阵,不同的阈值会影响得到的 T P R a t e TP_{Rate} TPRate, F P R a t e FP_{Rate} FPRate,如果阈值取0.5,小于0.5的为0,否则为1,那么我们就得到了与之前一样的混淆矩阵。其他的阈值就不再啰嗦了。依次使用所有预测值作为阈值,得到一系列 T P R a t e TP_{Rate} TPRate和 F P R a t e FP_{Rate} FPRate的描点,求面积,即可得到AUC。
二、AUC公式
AUC是指随机给定一个正样本和一个负样本,分类器输出该正样本为正的那个概率值比分类器输出该负样本为正的那个概率值要大的可能性。
随机抽取一个样本, 对应每一潜在可能值X都对应有一个判定位正样本的概率P。对一批已知正负的样本集合进行分类,具体数据如下表:
| label | predict | r a n k i n s i rank_{ins_i} rankinsi |
|---|---|---|
| 1 | 0.9 | 7 |
| 1 | 0.8 | 6 |
| 0 | 0.7 | 5 |
| 1 | 0.6 | 4 |
| 1 | 0.5 | 3 |
| 0 | 0.3 | 2 |
| 0 | 0.1 | 1 |
按概率从高到矮排个降序
- 正样本中概率最高的,排序为 r a n k 1 rank_1 rank1,
- 比它概率小的有 M − 1 M-1 M−1个正样本( M M M为正样本个数), ( r a n k 1 − M + 0 ) (rank_1 - M+0) (rank1−M+0) 个负样本。
- 正样本概率第二高的, 排序为 r a n k 2 rank_2 rank2,
- 比它概率小的有 M − 2 M-2 M−2个正样本, ( r a n k 2 − M + 1 ) (rank_2 - M + 1) (rank2−M+1)个 负样本。
- 正样本概率第三高的, 排序为 r a n k 3 rank_3 rank3,
- 比它概率小的有 M − 3 M-3 M−3个正样本, ( r a n k 3 − M + 2 ) (rank_3 - M + 2) (rank3−M+2)个 负样本。
以此类推…
正样本中概率最小的, 排序为r a n k M ank_M ankM,比它概率小的有0个正样本, r a n k M − M + ( M − 1 ) = r a n k M − 1 rank_M - M + (M-1) = rank_M-1 rankM−M+(M−1)=rankM−1个负样本。
总共有 M × N M \times N M×N个正负样本对( N N N为负样本个数)。把所有比较中正样本概率大于负样本概率的例子都计算之后得到公式:
A U C = ( r a n k 1 − M + r a n k 2 − M + 1.... + r a n k M − 1 ) ( M × N ) AUC = \frac{(rank_1 - M + rank_2 - M + 1 .... + rank_M - 1)} {(M \times N)} AUC=(M×N)(rank1−M+rank2−M+1....+rankM−1)
就是正样本概率大于负样本概率的可能性了。 化简后(因为后面是个等差数列)得:
A U C = ∑ i n s i ∈ p o s i t i c e c l a s s r a n k i n s i − M × ( M + 1 ) 2 M × N = 7 + 6 + 4 + 3 − 4 × ( 4 + 1 ) 2 4 × 3 = 20 − 10 12 = 5 6 ≈ 0.8333 AUC = \frac{\sum_{ins_i\in positiceclass}rank_{ins_i}-\frac{M\times (M+1)}{2}}{M\times N}=\frac{7+6+4+3-\frac{4\times (4+1)}{2}}{4\times 3}=\frac{20-10}{12}=\frac{5}{6}\approx 0.8333 AUC=M×N∑insi∈positiceclassrankinsi−2M×(M+1)=4×37+6+4+3−24×(4+1)=1220−10=65≈0.8333
三、AUC优势
AUC的计算方法同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价。
例如在反欺诈场景,设欺诈类样本为正例,正例占比很少(假设0.1%),如果使用准确率评估,把所有的样本预测为负例,便可以获得99.9%的准确率。
但是如果使用AUC,把所有样本预测为负例, T P R a t e TP_{Rate} TPRate和 F P R a t e FP_{Rate} FPRate同时为0(没有Positive),与(0,0) (1,1)连接,得出AUC仅为0.5,成功规避了样本不均匀带来的问题。