tf.keras.losses.CategoricalCrossentropy函数
函数原型
tf.keras.losses.CategoricalCrossentropy(
from_logits=False,
label_smoothing=0.0,
axis=-1,
reduction=losses_utils.ReductionV2.AUTO,
name='categorical_crossentropy'
)
函数说明
CategoricalCrossentropy函数用于计算多分类问题的交叉熵。使用的公式如下:
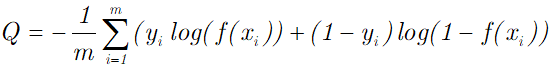
参数from_logtis默认为False, 表示输出的logits需要经过激活函数的处理。如果为True,则不需要经过激活函数的处理。
函数使用
CategoricalCrossentropy函数用于y_true的标签为one_hot编码的形式,如果y_true的标签为整数类型的数,则需要用到另外一个SparseCategoricalCrossentropy函数。
# y_true为one_hot编码形式,[0, 0, 1]对应类型2,[0, 1, 0]对应类型1,[1, 0, 0]对应类型0
# y_pred为各个类型对应的概率,比如[0.5, 0.3, 0.2]表示对应类型1的概率为0.5,对应类型2的概率为0.3
>>> y_true = [[0, 0, 1], [0, 1, 0], [0, 1, 0]]
>>> y_pred = [[0.5, 0.3, 0.2], [0.3, 0.6, 0.1], [0.4, 0.4, 0.2]]
>>> loss = tf.keras.losses.CategoricalCrossentropy()
>>> loss_calc = loss(y_true, y_pred)
>>> loss_calc
# 对比
# y_true为整数标签形式
>>> y_true = [2, 1, 1]
>>> y_pred = [[0.5, 0.3, 0.2], [0.3, 0.6, 0.1], [0.4, 0.4, 0.2]]
>>> loss = tf.keras.losses.SparseCategoricalCrossentropy()
>>> loss_calc = loss(y_true, y_pred)
>>> loss_calc
# y_pred为没有经过激活函数处理的logits
>>> y_true = [[0, 0, 1], [0, 1, 0], [0, 1, 0]]
>>> y_pred = [[-13.0, 23.0, 6.0], [3.0, 5.0, -22.0], [3.0, 4.0, 9.0]]
>>> loss = tf.keras.losses.CategoricalCrossentropy()
>>> loss_calc = loss(y_true, y_pred)
>>> loss_calc