动手学深度学习---深度学习计算篇
第5章 深度学习计算
1.层和块
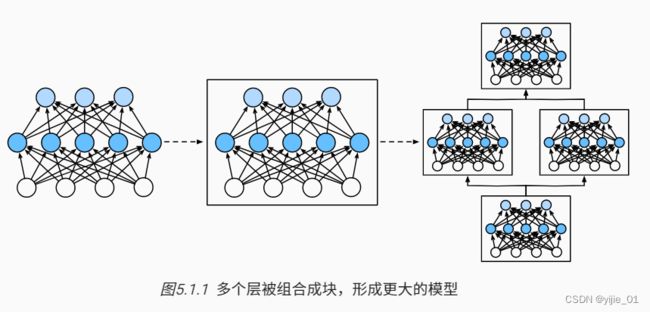
事实证明,研究讨论**‘’比单个层大‘’但’‘比整个模型小’'**更有价值。
-
神经网络—块
**块(block)**可以描述单个层、由多个层组成的组件或整个模型本身
使用块的好处:可以将多个块组合成为更大的组件,如下图
从编程角度来看,block由class表示。它的任何子类都必须定义一个将其输入转化为输出的前向传播函数,并且必须存储任何必须的参数,最后,为了计算梯度(gradient),块必须具有反向传播函数。在自行定义block时,因为自动微分提供了一些后端实现,所以我们只需要考虑
①前向传播函数
②必须的参数
在构造自定义块之前,我们先回顾一下多层感知机的代码。
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
X = torch.rand(2, 20)
net(X)
result:
tensor([[-0.0317, 0.0599, 0.0677, -0.0397, -0.2779, -0.1492, 0.2559, -0.1335,
0.1436, 0.0724],
[ 0.0539, 0.0003, 0.2255, 0.1326, -0.1195, -0.2064, 0.2232, -0.1109,
0.0944, 0.0557]], grad_fn=<AddmmBackward0>)
nn.Sequential定义了一种特殊的Module,即在Pytorch中表示一个块的类,nn.Sequential维护了一个由Module组成的有序list,而上面的两个全连接层都是Linear的实例,Linear类本身就是Module的子类。
另外,我们一直在通过net(X)调用模型的前向传播函数来获得模型的输出,net(X)实际是net.——call——(X)方法的简写。这个前向传播函数非常简单:他将list中的每个块连接在一起,将每个块连接一起,将每个块的输出作为下一块的输入。
-
自定义块
在自定义块之前,我们简要总结一下每个块必须提供的基本功能:
1.能够接受输入数据作为forward function的参数
2.具有forward function 来生成输出
3.能够计算其输出关于输入的梯度,可通过其反向传播函数进行访问。通过这个是自动发生的
4.能够存储和访问前向传播计算所需的参数
5.可以根据需要初始化模型参数
下面我们从零开始编写一个块,我们的实现只需要提供自己的构造函数(——init——函数)和前向传播函数
class MLP(nn.module):#MLP为nn.module的子类
# 用模型参数声明层。这里,我们声明两个全连接的层
def __init__(self):
# 调用MLP的父类Module的构造函数来执行必要的初始化。
# 这样,在类实例化时也可以指定其他函数参数,例如模型参数params(稍后将介绍)
#继承module的方法
super().__init__()
self.hidden=nn.Linear(20,256) # 隐藏层
self.out=nn.Linear(256,10)# 输出层
# 定义模型的前向传播,即如何根据输入X返回所需的模型输出
def forward(self,X):
#注意,这里我们使用ReLU的函数版本,其在nn.functional模块中定义。
return self.out(F.relu(self.hidden(x)))
讲解:首先我们定制的——init——函数通过super().——init——()调用父类的——init——函数,省去了重复编写模板代码的痛苦。 然后,我们实例化两个全连接层, 分别为self.hidden和self.out。 注意,除非我们实现一个新的运算符, 否则我们不必担心反向传播函数或参数初始化, 系统将自动生成。
net=MLP()
net(X)
result:
tensor([[-0.2483, -0.0997, 0.0449, 0.0865, 0.0789, 0.1179, -0.0869, 0.0793,
0.1143, -0.0995],
[-0.2792, -0.1567, 0.1541, 0.0910, 0.0766, 0.0490, -0.1328, -0.1031,
0.0536, -0.0458]], grad_fn=<AddmmBackward0>)
-
顺序块
现在我们仔细查看Sequential类如何工作的,Sequential的设计是为了串联所有block,为了构建类似Sequential的MySequential,我们只需要定义两个关键函数:
①一种将block逐个追加list的函数
②一种前向传播函数,用于将输入按追加块的顺序传递给块组成的“链条”。
下面的MySequential类提供了与默认Sequential类相同的功能
以下展示了使用 enumerate() 方法的实例:
>>> seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
class MySquential(nn.Module):
def __init__(self,*args):
super().__init__()
for idx,module in enumerate(args):
class MySequential(nn.Module):
def __init__(self, *args):# *args进行list解包
super().__init__()
for idx, module in enumerate(args):
#enumerate将list创变成 索引序列,下文中的idx由 enumerate产生
# 这里,module是Module子类的一个实例。我们把它保存在'Module'类的成员
# 变量_modules中。module的类型是OrderedDict
self._modules[str(idx)] = module
def forward(self, X):
# OrderedDict保证了按照成员添加的顺序遍历它们
for block in self._modules.values():
X = block(X)
return X
讲解:
__init__函数将每个block逐个添加到有序字典_modules中
为什么每个Module都有一个_modules属性?而不是自行定义一个Python列表?因为_modules主要优点是:在模块的参数初始化过程中,系统会自行在_modules字典中查找需要初始化参数的子块
当MySequential的前向传播函数被调用时, 每个添加的块都按照它们被添加的顺序执行
下面我们使用自行定义 MySquential类重新实现多层感知机
net=MySquential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10))
net(X)
result:
tensor([[-0.1438, -0.0631, -0.2420, -0.0499, 0.2361, 0.0188, 0.1304, 0.2161,
-0.1725, -0.0187],
[-0.1461, -0.0612, -0.1650, 0.0629, 0.3020, -0.0028, 0.1891, 0.1974,
-0.2368, -0.2183]], grad_fn=)
-
在前向传播中执行代码
Sequential类使模型构造变得简单,允许直接构造新的架构,而不必定义自己的类。但当我们需要更强的灵活性时,我们需要定义自己的块。
例:构造一个可以在前向传播函数中执行python控制流,同时能够将常数参数合并入计算流中例如,我们需要一个计算函数 f(x,w)=c⋅w⊤x的层, 其中x是输入, w是参数, c是某个在优化过程中没有更新的指定常量。 因此我们实现了一个FixedHiddenMLP类,如下所示:
class FixedHiddenMLP(nn.Module):
def __init__():
super().__init()
# 不计算梯度的随机权重参数。因此其在训练期间保持不变
self.rand_weigt=torch.rand((20,20),requires_grad=True)
self.linear=nn.linear(20,20)
def forward(self,x):
x=self.linear(x)
# 使用创建的常量参数以及relu和mm函数
x=F.relu(torch.mm(X,self.rand_weight)+1)
# 复用全连接层。这相当于两个全连接层共享参数
x=self.linear(x)
# 控制流
while X.abs().sum()>1:
x/=2
return x.sum()
net=FixedHiddenMLP()
net(x)
result:
tensor(0.2580, grad_fn=<SumBackward0>)
-
按需混合搭配块
我们还可以混合搭配各种组合块,例如下面的嵌套块
class NestMLP(nn.Module):
def __init__(self):
super().__init__()
#nn.linear(20,64)代表W的shape
self.net=nn.Sequential(nn.linear(20,64),nn.ReLU(),nn.Linear(64,32),nn.ReLU())
self.linear=nn.linear(32,16)
def forward(self,X):
return self.linear(self.net(X))
#进行实例化
chimera=nn.Sequential(NestMLP(),nn.Linear(16,20),FixedHiddenMLP)
#X的shape为(2,20)
chimera(X)
tensor(0.0615, grad_fn=)
2.参数管理
前言:经过训练后,模型参数值已达到最优。有时我们希望提取模型参数,便于在其他环境直接复用,或者是将模型保存下来,以便于可以在其它软件中执行
前面只依靠深度学习框架进行了训练工作,忽略了操作参数的具体细节
本节我们将介绍以下内容:
我们以具有单隐藏层的MLP为例
import torch
from torch import nn
net=nn.Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,1))
X=torch.rand(size=(2,4))
net(X)
result:
tensor([[-0.5571],
[-0.5239]], grad_fn=)
-
模型参数访问
我们从已有模型中访问参数。当用Sequential类定义模型时,我们通过索引来访问模型的任意层。模型像一个list,每层的参数都在层的属性中。
如下所示,我们可以检查第二个全连接层的参数
print(net(2).state_dict())
#net(2)代表第二层
#net(2).state_dict() 表明state_dict()是net(2)的属性
result::
OrderedDict([('weight', tensor([[ 0.3231, -0.3373, 0.1639, -0.3125, 0.0527, -0.2957, 0.0192, 0.0039]])), ('bias', tensor([-0.2930]))])
输出的结果表明:
①net(2)包含两个参数,分别是权重和偏置
②两者都存储为单精度浮点数(float32)
③参数名称允许唯一标识每个参数,即使在包含数百个层的网络中也是如此
-
目标参数
注意:每个参数都是**参数类(parameter)**的一个实例。
要对参数执行任何操作,首先我们需要访问底层的数值。如下操作所示:
print(type(net[2].bias))
print(net[2].bais)
print(net[2].bias.data)
result:
<class 'torch.nn.parameter.Parameter'> #这个为type,证明了每个参数都是参数类实例
Parameter containing:
tensor([-0.2930], requires_grad=True) #这个为bias
tensor([-0.2930])#这个为bias.data
由上述第二个打印结果可知,参数是复合的对象
这就是我们需要显示参数值的原因,除了值之外,我们还可以访问每个参数的梯度,因为上面网络还没有调用反向传播,所以参数梯度处于None
net[2].weight.grad==None
result:
True
-
一次性访问所有参数
当我们需要对所有参数执行操作时,逐个访问会变得很麻烦。因此我们需要递归整个树来提取每个子块的参数。下面,我们将通过演示来比较访问第一个全连接层的参数和访问所有层
print(*[(name,param.shape) for name,param in net[0].named_parameters()])
print(*[(name,param.shape) for name,param in net.named_parameters()])
result:
('weight', torch.Size([8, 4])) ('bias', torch.Size([8]))
('0.weight', torch.Size([8, 4])) ('0.bias', torch.Size([8])) ('2.weight', torch.Size([1, 8])) ('2.bias', torch.Size([1]))
这为我们提供了另一种访问网络参数的方式
net.state_dict()['2.bias'].data
#可以看出 ['2.bias']充当索引 即键的作用
result:
tensor([-0.2930])
-
从嵌套块收集参数
接下来,我们将多个块进行互相嵌套,来观察参数命名约定是如何工作的。
首先我们定义一个生成块的函数,然后把这些块组合到更大的块中。
def block1():
#定义一个四层网络的块
return nn.Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,4),nn.ReLU())
def block2():
net=nn.Sequential()
for i in range(4):
# 嵌套生成四个连接的相同块
net.add_module('f'block{i}',block1())
return net
rgnet=nn.Sequential(block2(),nn.Linear(4,1))
rgnet(X)
result:
tensor([[0.4196],
[0.4195]], grad_fn=)
设计了网络后,我们观察他的工作原理
print(rgnet)
Sequential(
#第一个块|层
(0): Sequential(
#第1个子块
(block 0): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)#第1层
(1): ReLU()#第2层
(2): Linear(in_features=8, out_features=4, bias=True)#第3层
(3): ReLU()#第4层
)
#第2个子块
(block 1): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)#第1层
(1): ReLU()#第2层
(2): Linear(in_features=8, out_features=4, bias=True)#第3层
(3): ReLU()#第4层
)
#第3个子块
(block 2): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)#第1层
(1): ReLU()#第2层
(2): Linear(in_features=8, out_features=4, bias=True)#第3层
(3): ReLU()#第4层
)
#第4个子块
(block 3): Sequential(
(0): Linear(in_features=4, out_features=8, bias=True)#第1层
(1): ReLU()#第2层
(2): Linear(in_features=8, out_features=4, bias=True)#第3层
(3): ReLU()#第4层
)
)
#第二个块|层
(1): Linear(in_features=4, out_features=1, bias=True)
)
因为层是分层嵌套的,所以我们可以通过嵌套列表索引来访问他们。这里,我们访问第一个主要的块中、第二个子块的第一层的偏置项
rgnet[0][1][0].bias.data
result:
tensor([-0.2726, 0.2247, -0.3964, 0.3576, -0.2231, 0.1649, -0.1170, -0.3014])
-
参数初始化
直到如何访问参数后,我们来看看如何正确初始化参数。通过第四章我们知道了良好初始化模型参数的必要性。
默认情况下, PyTorch会根据一个范围均匀地初始化权重和偏置矩阵, 这个范围是根据输入和输出维度(nin,nout)计算出的。 PyTorch的nn.init模块提供了多种预置初始化方法。**
①内置初始化
首先调用内置的初始化器。下面我们将所有权重参数初始化为标准差为0.01的高斯随机变量,且将bias设置为0
def init_normal(m):
if type(m)=nn.Linear:
#nn.init模块提供了多种预置初始化方法
nn.init.normal_(m.weght,mean=0,std=0.01)
nn.init.zeros(m.bias)
net.apply(init_normal)
net[0].weight.data[0],net[0].bias.data[0]
#打印第一层权重参数中的第一行,打印第一层偏置参数中的第一行
result:
(tensor([1., 1., 1., 1.]), tensor(0.))
我们还可以对某些块应用不同的初始化方法。
例如我们使用Xavier初始化方法初始化第一个神经网络层, 然后将第三个神经网络层初始化为常量值42
def xavier(m):
if type(m)==nn.Linear:
#nn.init模块提供了多种预置初始化方法
nn.init.xavier_uniform_(m.weight)#模型参数使用Xavier初始化方法
def init_42(m):
if type(m)==nn.Linear:
nn.init.constant_(m.weight,42)#进行参数初始化模型参数
net[0].apply(xavier)#使用Xavier初始化方法初始化第一个神经网络层
net[2].apply(init_42)#第三个神经网络层初始化为常量值42
print(net[0].weight.data[0])
print(net[2].weight.data)
result:
tensor([-0.4645, 0.0062, -0.5186, 0.3513])
tensor([[42., 42., 42., 42., 42., 42., 42., 42.]])
②自定义初始化
因为deep learning有时没有我们需要的初始化方法,所以我们需要自己实现。
在下面例子中,我们使用以下分布为 任意权重参数w 定义初始化方法:

于是,我们实现了一个my_init函数来应用到net
def my_init(m):
if type(m)==nn.Linear:
print("Init",*[(name,param.shape) for name,param in m.named_parameters()[0]])
nn.init.uniform_(m.weight,-10,10)
m.weight.data *=m.weight.data.abs()>=5
#因为初期将模型参数初始化范围为(-10,10)
#参数的绝对值>=5的概率是二分之一
#m.weight.data.abs()>=5 权重有一半概率>=5,一半<5,该语句得到布尔矩阵
#将m.weight.data *=m.weight.data.abs()>=5 ,若绝对值>=5则参数不变,<5则置为0
#经此操作得到了自定义初始化方法下的模型参数
result:
Init weight torch.Size([8, 4])
Init weight torch.Size([1, 8])
tensor([[ 8.8025, 6.4078, 0.0000, -8.4598],
[-0.0000, 9.0582, 8.8258, 7.4997]], grad_fn=<SliceBackward0>)
注意,我们始终可以直接设置参数
net[0].weight.data[:]+=1
net[0].weight.data[0, 0] = 42
net[0].weight.data[0]
result:
tensor([42.0000, 7.4078, 1.0000, -7.4598])
-
参数绑定
有时我们希望在多个层间共享参数: 我们可以定义一个稠密层,然后使用它的参数来设置另一个层的参数。
例:共同使用一个层对象
# 我们需要给共享层一个名称,以便可以引用它的参数
shared=nn.Linear(8,8)
net=nn.Sequential(nn.Linear(4,8),nn.ReLU(),shared,nn,ReLU(),shared,nn.ReLU(),nn.Linear(8,1))
net(x)
# 检查参数是否相同
print(net[2].weight.data[0]==net[4].weight.data[0])
net[2].weight.data[0,0]=100
# 确保它们实际上是同一个对象,而不只是有相同的值
print(net[2].weight.data[0]==net[4].weight.data[0])
tensor([True, True, True, True, True, True, True, True])
tensor([True, True, True, True, True, True, True, True])
这个例子表明,第三个和第五个神经网络层的参数是绑定的。因此,只要我们改变该层其中一个参数,另一个层的相应参数也会改变。
你可能会思考:当参数绑定时,梯度会发生什么情况? 答案是由于模型参数包含梯度,因此在反向传播期间第二个隐藏层 (即第三个神经网络层)和第三个隐藏层(即第五个神经网络层)的梯度会加在一起。
共享参数好处:通常可以节省内存
3.延后初始化
到目前为止,我们忽略了建立网络时需要做的以下事情:
- 我们定义了网络架构,但没有指定输入维度。
- 我们添加层时没有指定前一层的输出维度。
- 我们在初始化参数时,甚至没有足够的信息来确定模型应该包含多少参数。
当未指定网络的输入维度时,代码却能运行,这里的诀窍是 延后初始化(defers initialization), 即直到数据第一次通过模型传递时,框架才会动态地推断出每个层的大小
现在我们在编写代码时无需知道维度是什么就可以设置参数,这种能力大大简化了 定义和修改模型的任务。 接下来,我们将更深入地研究初始化机制。
-
实例化网络
from mxnet import np, npx
from mxnet.gluon import nn
npx.set_np()
def get_net():
net = nn.Sequential()#实例化Sequential类
net.add(nn.Dense(256, activation='relu'))#第一层输出维度为256,输入维度未知
net.add(nn.Dense(10))#第一层输出维度为10,输入维度未知
return net
net = get_net()
此时,因为输入维数是未知的,所以网络不可能知道输入层权重的维数。 因此,框架尚未初始化任何参数,我们通过尝试访问以下参数进行确认。
print(net.collect_params)
print(net.collect_params())
result:
<bound method Block.collect_params of Sequential(
(0): Dense(-1 -> 256, Activation(relu))
(1): Dense(-1 -> 10, linear)
)>
sequential0_ (
Parameter dense0_weight (shape=(256, -1), dtype=float32)
Parameter dense0_bias (shape=(256,), dtype=float32)
Parameter dense1_weight (shape=(10, -1), dtype=float32)
Parameter dense1_bias (shape=(10,), dtype=float32)
)
可以看出,当参数对象存在时,每个层的输入维度为-1。 MXNet使用特殊值-1表示参数维度仍然未知。 此时,尝试访问net[0].weight.data()将触发运行时错误, 提示必须先初始化网络,然后才能访问参数。 现在让我们看看当我们试图通过initialize函数初始化参数时会发生什么
net.initialize()
net.collect_params()
result:
sequential0_ (
Parameter dense0_weight (shape=(256, -1), dtype=float32)
Parameter dense0_bias (shape=(256,), dtype=float32)
Parameter dense1_weight (shape=(10, -1), dtype=float32)
Parameter dense1_bias (shape=(10,), dtype=float32)
)
如我们所见,一切都没有改变。 当输入维度未知时,调用initialize不会真正初始化参数。 而是会在MXNet内部声明希望初始化参数,并且可以选择初始化分布。
接下来让我们将数据通过网络,最终使框架初始化参数。
X = np.random.uniform(size=(2, 20))
net(X)
net.collect_params()
result:
sequential0_ (
Parameter dense0_weight (shape=(256, 20), dtype=float32)
Parameter dense0_bias (shape=(256,), dtype=float32)
Parameter dense1_weight (shape=(10, 256), dtype=float32)
Parameter dense1_bias (shape=(10,), dtype=float32)
)
可以从上述结果看出,当输入X(shape为(2,20))时,框架动态判断了输入维度是20, 识别出第一层的形状后,框架处理第二层,依此类推,直到所有形状都已知为止。 注意,在这种情况下,只有第一层需要延迟初始化,但是框架仍是按顺序初始化的。 等到知道了所有的参数形状,框架就可以初始化参数。
本小节总结:当我们构建网络层时,可以不用指定输入维度,让神经网络进行动态判断,这种能力大大简化了定义和修改模型的任务。
4.自定义层
未来,我们会遇到或要自己发明一个现在在深度学习框架中还不存在的层。在本节中,我们将展现如何构建自定义层 (属性+方法)
-
不带参数的层
构建从输入减去均值的层,不具有模型参数
import torch
import torch.nn.functional as F
from torch import nn
class CenteredLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X):
return X - X.mean()
让我们向该层提供一些数据,验证它是否能按预期工作
layer = CenteredLayer()
layer(torch.FloatTensor([1, 2, 3, 4, 5]))
result:
tensor([-2., -1., 0., 1., 2.])
现在,我们可以将层作为组件合并到更复杂的模型中。
net = nn.Sequential(nn.Linear(8, 128), CenteredLayer())
作为额外的健全性检查,我们可以在向该网络发送随机数据后,检查均值是否为0。 由于我们处理的是浮点数,因为存储精度的原因,我们仍然可能会看到一个非常小的非零数。
Y = net(torch.rand(4, 8))
Y.mean()
result:
tensor(9.3132e-10, grad_fn=)
-
带参数的层
下面我们定义具有参数的层,这些参数可以通过训练调整。这里我们使用内置函数创建参数,这些函数提供一些基本的管理功能:
现在,我们自行实现全连接层。在此实现中,我们使用ReLU作为激活函数。该层需要输入参数: in_units和units,分别表示输入数和输出数。
#在自定义全连接层中,我们可以看出nn.liear(in_units,units)的运行原理
class Mylinear(nn.Module):
def __init__(self,in_units,units):
super().__init__()
#实例化全连接层的参数
self.weight=nn.Parameter(torch.randn(in_units,units))
self.bias=nn.Parameter(torch.randn(units))
def forword(self,X):
linear=torch.matmul(X,self.weight.data)+self.bias.data
return F.relu(linear)
接下来,我们实例化MyLinear类并访问其模型参数。
linear = MyLinear(5, 3)#相当于 nn.linear(5,3) 既实例化了层,又初始化了层的参数
linear.weight
result:
Parameter containing:
tensor([[ 1.9054, -3.4102, -0.9792],
[ 1.5522, 0.8707, 0.6481],
[ 1.0974, 0.2568, 0.4034],
[ 0.1416, -1.1389, 0.5875],
[-0.7209, 0.4432, 0.1222]], requires_grad=True)
我们可以使用自定义层直接执行前向传播计算。
linear(torch.rand(2, 5))
result:
tensor([[2.4784, 0.0000, 0.8991],
[3.6132, 0.0000, 1.1160]])
我们还可以使用自定义层构建模型,就像使用内置的全连接层一样使用自定义层。
net = nn.Sequential(MyLinear(64, 8), MyLinear(8, 1))
net(torch.rand(2, 64))
result:
tensor([[0.],
[0.]])
5.读写文件
当我们需要保存训练好的模型(模型参数),以便于在不同环境进行直接部署。此外 当运行一个耗时较长的训练过程时, 最佳的做法是定期保存中间结果, 以确保在服务器电源被不小心断掉时,我们不会损失几天的计算结果。 因此,现在是时候学习如何加载和存储 ** 权重向量和整个模型**。
-
加载和保存张量
①对于单个tensor,我们直接调用load和save函数分别进行读写
import torch
from torch import nn
from torch.nn import functional as F
x = torch.arange(4)
torch.save(x, 'x-file')
#x为数据,'x-file'为文件名 //默认保存在相对路径,除非直接将绝对路径作为参数
我们现在可以将存储在文件中的数据读回内存。
x2 = torch.load('x-file')
x2
result:
tensor([0, 1, 2, 3])
②存储tensor 列表
y = torch.zeros(4)
torch.save([x, y],'x-files')
x2, y2 = torch.load('x-files')
(x2, y2)
result:
(tensor([0, 1, 2, 3]), tensor([0., 0., 0., 0.]))
③存储权重字典
mydict = {'x': x, 'y': y}
torch.save(mydict, 'mydict')
mydict2 = torch.load('mydict')
mydict2
result:
{'x': tensor([0, 1, 2, 3]), 'y': tensor([0., 0., 0., 0.])}
-
加载和保存模型参数
深度学习框架提供内置函数来保存和加载整个网络 ,需要注意的是:保存的是模型的参数而非整个模型
让我们从熟悉的多层感知机额开始尝试
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden=nn.Linear(20,256)
self.output=nn.Linear(256,10)
def forward(self,x):
return self.output(F.relu(self.hidden(x)))
net=MLP()
X = torch.randn(size=(2, 20))
Y = net(X)
接下来,我们将模型的参数存储在一个叫做“mlp.params”的文件中。
torch.save(net.state_dict(),'mlp.params')
#net,state_dict()为参数字典
为恢复模型,我们实例化原始多层感知机模型备份。 我们不再需要随机初始化模型参数,而是直接读取文件中存储的参数。
clone=MLP()
clone.load_state_dict(torch.load('mlp.params'))
clone.eval()
#torch.load('mlp.params')将文件数据载入磁盘
clone.load_state_dict(torch.load('mlp.params'))#将磁盘中的数据字典载入模型作为模型参数
result:
MLP(
(hidden): Linear(in_features=20, out_features=256, bias=True)
(output): Linear(in_features=256, out_features=10, bias=True)
)
由于两个实例具有相同的模型参数,在输入相同的X时, 两个实例的计算结果应该相同。
Y_clone = clone(X)
Y_clone == Y
result:
tensor([[True, True, True, True, True, True, True, True, True, True],
[True, True, True, True, True, True, True, True, True, True]])
6.GPU
本节我们讨论如何使用GPU的强大计算性能,首先是如何使用单个GPU,然后是如何使用多个GPU和多个服务器(具有多个GPU)
使用 nvidia-smi来查看显卡信息
nvidia-smi
Thu Mar 31 23:45:57 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.27.04 Driver Version: 460.27.04 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... Off | 00000000:00:1B.0 Off | 0 |
| N/A 44C P0 77W / 300W | 1612MiB / 16160MiB | 63% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-SXM2... Off | 00000000:00:1C.0 Off | 0 |
| N/A 47C P0 38W / 300W | 0MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 Tesla V100-SXM2... Off | 00000000:00:1D.0 Off | 0 |
| N/A 44C P0 77W / 300W | 1624MiB / 16160MiB | 61% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-SXM2... Off | 00000000:00:1E.0 Off | 0 |
| N/A 52C P0 42W / 300W | 0MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 94484 C ...l-zh-release-0/bin/python 1609MiB |
| 2 N/A N/A 94484 C ...l-zh-release-0/bin/python 1621MiB |
+-----------------------------------------------------------------------------+
在PyTorch中,每个数组都有一个设备(device),通常将其称为上下文(context)。
默认下,所有变量和相关计算都分配给CPU,有时上下文可能是GPU。
当跨多个服务器部署作业时,通过智能地将数组分配给上下文,我们 可以最大限度地减少在设备之间传输数据的时间 。例如,当在带有GPU的服务器上训练神经网络时, 我们通常希望模型的参数在GPU上。
本节将展示数据如何在不同的上下文之间传递,要运行此部分程序,至少需要两个GPU
-
计算设备
可以指定用于存储和计算的设备,如GPU和CPU。
在PyTorch中,CPU和GPU可以用torch.device('cpu') 和torch.device('cuda')表示。
如果有多个GPU,我们使用torch.device(f'cuda:{i}') 来表示第i块GPU(i从0开始)。 另外,cuda:0和cuda是等价的。
import torch
from torch import nn
torch.device('cpu'),torch.device('cuda'),torch.device('cuda:1')
result:
(device(type='cpu'), device(type='cuda'), device(type='cuda', index=1))
我们可以查询可用gpu的数量。
torch.cuda.device_count()
result:
2
现在我们定义了两个方便的函数, 这两个函数允许我们在不存在所需所有GPU的情况下运行代码。
def try_gpu(i=0):
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count()>=i+1:#如果存在gpu
return torch.device(f'cuda:{i}')#使用第一块gpu
return torch.device('cpu')#没有gpu,使用cpu
def try_all_gpus():
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""
devices=[torch.device(f'cuda:{i}')
for i in range(torch.cuda_count())]
return devices if devices else [torch.device('cpu')]
try_gpu(), try_gpu(10), try_all_gpus()
result:
(device(type='cuda', index=0),#使用第一个gpu
device(type='cpu'),#没有第11个gpu,默认使用cpu
[device(type='cuda', index=0), device(type='cuda', index=1)])#使用所有的gpu
虽然gpu有多个,但涉及对多个项进行操作,这几个项必须在同一 device|context上。否则,框架不知道在哪里存储结果,甚至不知道在哪里执行计算
-
存储在不同GPU上
在创建tensor时指定存储设备
X = torch.ones(2, 3, device=try_gpu())
X
result:
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:0')
假设你至少有两个GPU,下面的代码将在第二个GPU上创建一个随机张量
Y = torch.rand(2, 3, device=try_gpu(1))
Y
result:
tensor([[0.1206, 0.2283, 0.4548],
[0.9806, 0.9616, 0.0501]], device='cuda:1')
-
复制
如果计算需要使用不同GPU上存储的数据,我们需要决定在哪里执行这个操作。
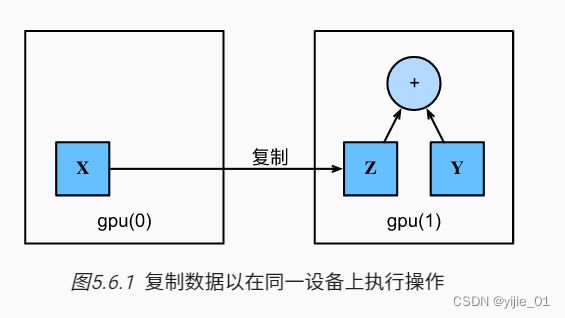
Z = X.cuda(1)
print(X)
print(Z)
result:
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:0')
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:1')
现在数据在同一个GPU上(Z和Y都在),我们可以将它们相加。
Y + Z
result:
tensor([[1.1206, 1.2283, 1.4548],
[1.9806, 1.9616, 1.0501]], device='cuda:1')
假设变量Z已经存在于第二个GPU上。 如果我们还是调用Z.cuda(1)会发生什么? 它将返回Z,而不会复制并分配新内存。
Z.cuda(1) is Z
result:
True
-
神经网络与GPU
类似,神经网络模型同样可以指定设备。下面代码将模型参数放在GPU上
net=nn.Sequential(nn.Linear(3,1))
net=net.to(device=try_gpu())
#看似是放置网络模型,实质是放置了net的属性(如 arameters)与计算结果到同一上下文
当输入为GPU上的张量时,模型将在同一GPU上计算结果。
net(X)
result:
tensor([[-0.7803],
[-0.7803]], device='cuda:0', grad_fn=)
让我们确认模型参数存储在同一个GPU上。
net[0].weight.data.device
result:
device(type='cuda', index=0)
总之,只要所有的数据和模型参数都在同一个设备上, 我们就可以有效地学习模型。 。