Anaconda3使用Spark的正确方法
目录
一、理论知识
二、部署环境
三、部署流程
3.1、创建Anaconda的环境,安装Anaconda3工具
3.2、部署Java环境、Scala环境,添加环境变量
3.3、创建Spark的环境,建立新项目
3.4、输入代码,进行验证
四、总结
一、理论知识
Apache Spark 是用于大规模数据处理的统一分析引擎。它提供 Java、Scala、Python 和 R 中的高级 API,以及支持通用执行图的优化引擎。它还支持一组丰富的高级工具,包括用于 SQL 和结构化数据处理的Spark SQL 、用于机器学习的MLlib、用于图形处理的 GraphX,以及用于增量计算和流处理的结构化流。(详细的理论可以翻阅官网手册)
关于我使用的版本的介绍。(一定要看官方手册,针对具体问题具体分析。自己在博客找了很多文档,都不适合自己环境。挖坑几天了,费时费力。)
官方地址Overview - Spark 3.1.2 Documentation

二、部署环境
Windowns10,Anaconda3(自带python3.7,R语言),jdk-8u341-windows-x64、scala-2.12.8.msi、pyspark3.1.2
三、部署流程
3.1、创建Anaconda的环境,安装Anaconda3工具
这里可以看我的博客,基本上从官网下载,基本上都是默认安装
Python-IDE舍弃Pycharm追求Anacanda之旅_业里村牛欢喜的博客-CSDN博客
(注意添加python路径给系统中)

3.2、部署Java环境、Scala环境,添加环境变量
下载java程序包,Scala的程序包。
傻瓜式默认安装java程序包,在添加系统路径,这里我是安装在C盘路径下面。(默认安装C盘下)

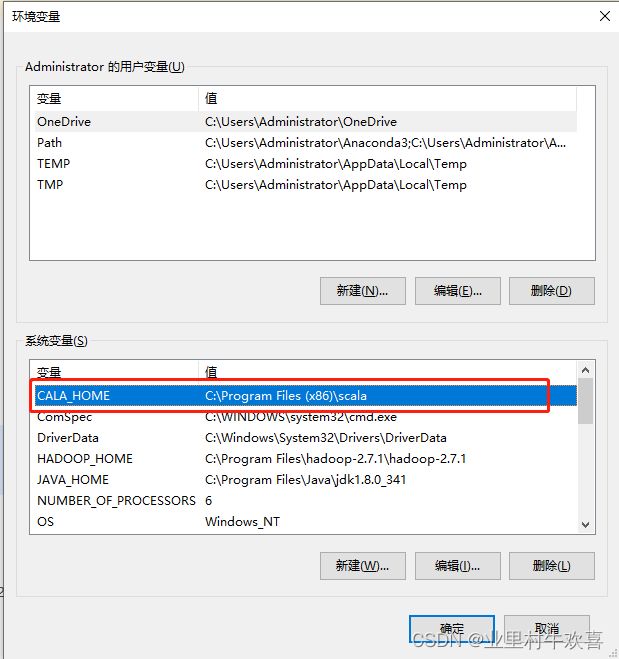
Scala 默认安装路径,在系统变量中添加
3.3、创建Spark的环境,建立新项目
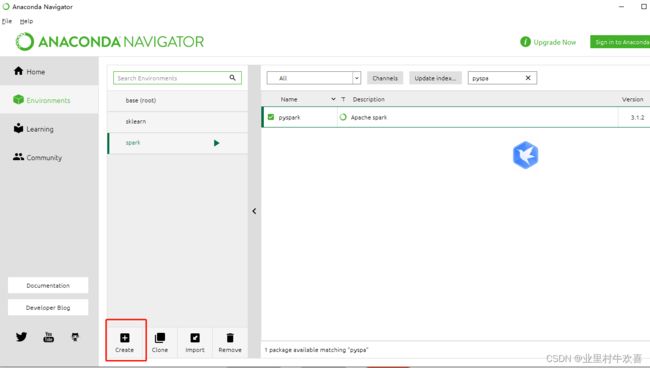
打开Anaconda3的工作平台,创建一个项目环境。
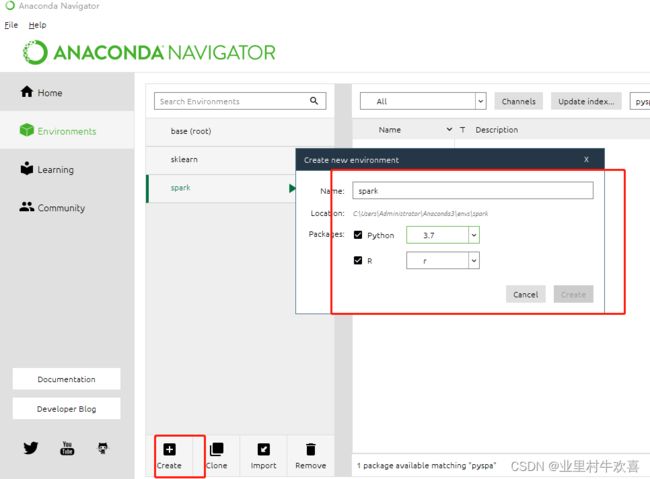
这里选择创建名字,记得把python3.7+R语言都勾选上。
在项目中,选择pyspark模块进行安装,这里可以选择3.1.2版本。

打开终端,测试一下Java路径和scala路径,验证是否环境变量配置是否正常。
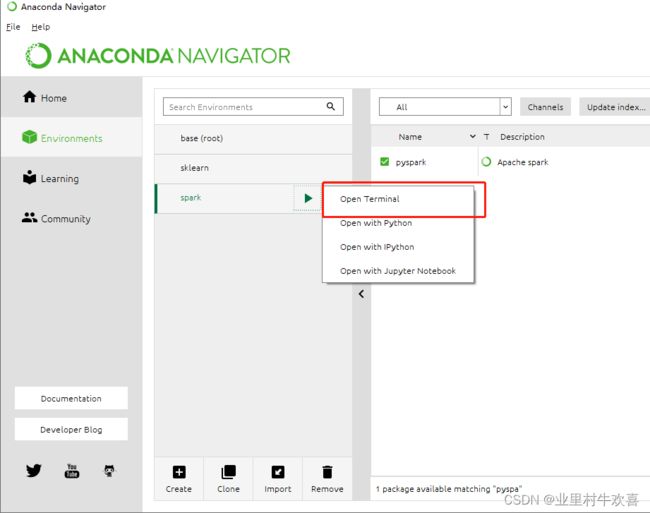
验证配置环境变量是否正常了,在新的环境下面输入变量。


3.4、输入代码,进行验证
使用jupyter nootbook
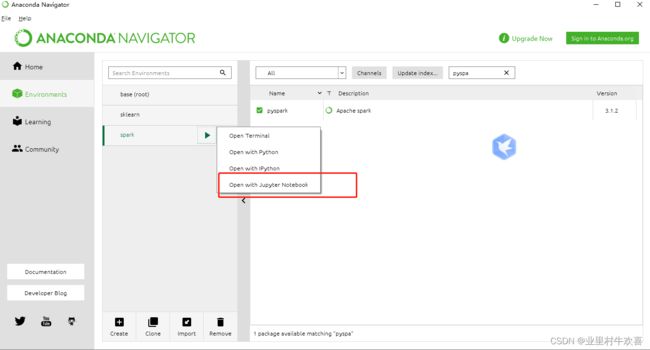
创建一个新的脚本文件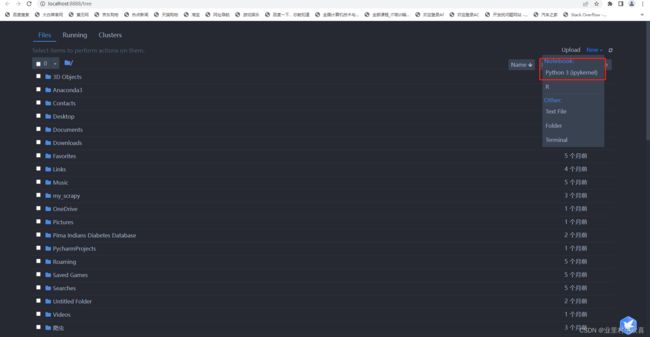
输入Spark测试代码,进行运行。(如果Spark安装成功的话,代码不会运行错误。)
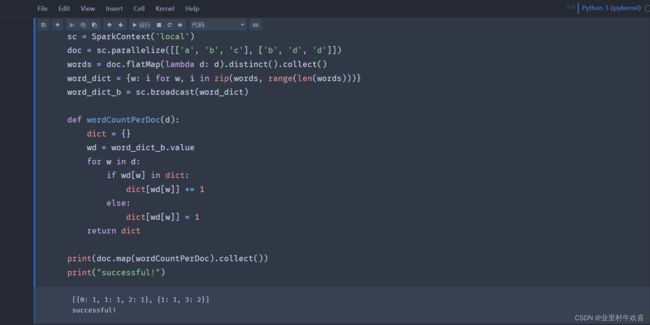
Jubyter nootbook运行日志,显示无异常。

spark测试代码片段:
from pyspark import SparkContext
sc = SparkContext('local')
doc = sc.parallelize([['a', 'b', 'c'], ['b', 'd', 'd']])
words = doc.flatMap(lambda d: d).distinct().collect()
word_dict = {w: i for w, i in zip(words, range(len(words)))}
word_dict_b = sc.broadcast(word_dict)
def wordCountPerDoc(d):
dict = {}
wd = word_dict_b.value
for w in d:
if wd[w] in dict:
dict[wd[w]] += 1
else:
dict[wd[w]] = 1
return dict
print(doc.map(wordCountPerDoc).collect())
print("successful!")挖坑经历:
这里演示一下换另外一个环境进行测试,在sklearn中进行测试。在sklearn环境中,我没有安装R语言,但是环境配置都是正常的了。
每次运行时候就报错,这里报错之后,jubyter nootbook就停止工作需要重启。
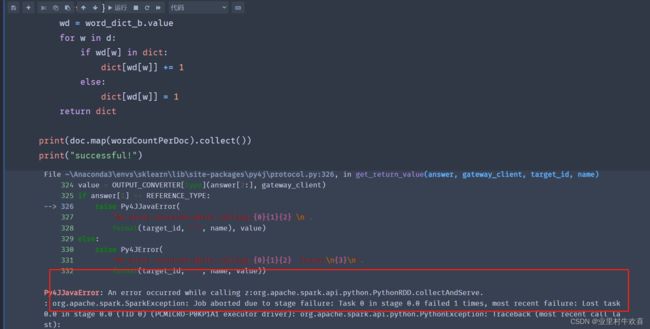
然后我们来看看jubyter的日志。分析一下日志,jubyter从启动到创建脚本,各种都正常,但是运行代码之后,系统一直报错。系统平台截止。从日志上面分析,系统一直提示我们安装的python环境和pyspark的环境不相匹配。我试了很多遍,不管是用spark什么版本都不对。最后是按照官网手册建立R语言,运行才正常。

四、总结
1、看官方手册,按照spark对应的版本需要的插件进行安装。博客千万条,不一定适合自己的环境。
2、java,scala是必要的插件,我第一次使用pyspark时,就报错缺少java的环境支持,我按照完java环境,就提示另外错误。
3、hadoop不需要安装,官网手册里面写到不要安装。很多博客里面还要安装hadoop,winutils,还需要将winutils的文件安装到hadoop路径下面。
参考文献:
Windows环境下Anaconda 安装R+Python3.5详细过程 - 腾讯云开发者社区-腾讯云
spark安装_Spark从零开始-慕课网
Overview - Spark 3.1.2 Documentation
Python运行spark时出现版本不同的错误_善守的大龙猫的博客-CSDN博客
https://www.jianshu.com/p/a3af36409e0b
pyspark入门教程_wapecheng的博客-CSDN博客_pyspark