bert-as-service 详细使用指南写给初学者
一.背景
1. 关于bert-as-service的github开源项目地址:
https://github.com/hanxiao/bert-as-service
2. 简述
bert-as-service主要功能是将我们预训练的BERT模型封装后当作一种服务来提供给客户端使用。
3. 示意图

4. 示意图解释
① BERT基于数据集进行预训练后,获得一个预训练模型;
② 然后,基于下游任务(问答,完形填空,命名实体识别等)进行微调;
③ 基于bert-as-service将模型进行封装,作为服务提供;
④ 用户从客户端输入句子,传输给服务端,用来计算语句之间的相似性;
⑤ 服务端计算完句子的embedding后,将结果传给客户端做进一步的处理;
二.实战篇
1. 安装anaconda,根据自己的系统(windows或linux)选择对应的anaconda版本。
下载地址:https://www.anaconda.com/products/individual#Downloads

图-01
2. 创建虚拟环境
① python版本3.6
② 虚拟环境名称:bert_env
③ 命令如下:conda create -n bert_env python=3.6

图-02
3. 启动虚拟环境
① 命令如下:conda activate bert_env

图-03
4. 安装依赖包
① 安装tensorflow命令:conda install tensorflow==1.15
② 安装bert-serving-client和bert-serving-server命令:
pip install bert-serving-client bert-serving-server
图-04-01
图-04-02
5. 下载预训练模型【中文模型】
地址:https://github.com/ymcui/Chinese-BERT-wwm#%E4%B8%AD%E6%96%87%E6%A8%A1%E5%9E%8B%E4%B8%8B%E8%BD%BD

图-05-01
【可以下载任意一个模型,我下载的BERT-base,Chinese】

图-05-02
6. 启动bert服务
① 命令如下:
bert-serving-start -model_dir=./chinese_L-12_H-768_A-12/ -num_worker=4
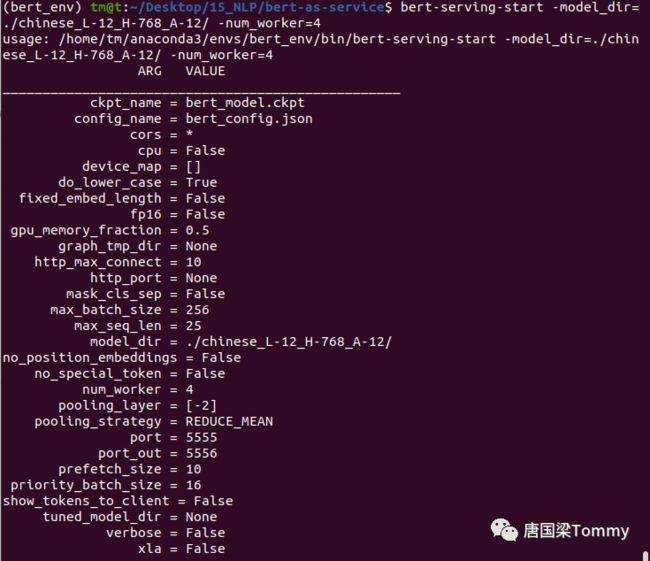
图-06-01
正常运行后的信息输出:
图-06-02
7. 使用Client客户端获取sentence encodes(语句编码)
① 打开一个新的命令行窗口,按照之前的操作方式进入到虚拟环境bert_env下;
② 进入python环境;
③ 输入以下命令:
from bert_serving.client import BertClient #导入客户端
bc = BertClient() # 创建客户端对象
result = bc.encode(['你好', '我来自中国', '中国是一个历史悠久、文化底蕴深厚的国家'])
result.shape # 查看输出结果shape

图-07
④ 解释一下以上的输出结果
result.shape = (3, 768) 意味着有3个文本,每个文本对应的vector是768维;
8. 远程调用BERT服务
说明:如果你的公司或学校有多台服务器,你把bert服务部署在服务器上,这时我们从本机去远程访问服务器获取服务,具体操作与本机操作基本上一致,区别在于设置一下访问的IP地址。
① 命令如下:
from bert_serving.client import BertClient
bc = BertClient(ip=’13.26.76.29’) # 这里的IP地址指向服务器
bc.encode([‘句子1’, ‘句子2’]) # 对语句进行embedding
【注意:我会在后续企业级案例实战案例中详细讲解如何部署、调用服务】
9. 案例一:计算两个语句的相似性,判断是否语句含义一致
第一步:查看本机启动的进程 PID,我们需要先关闭bert服务【如果你运行了之前的案例,否则,请忽略第一步】
① 命令:netstat -nltp
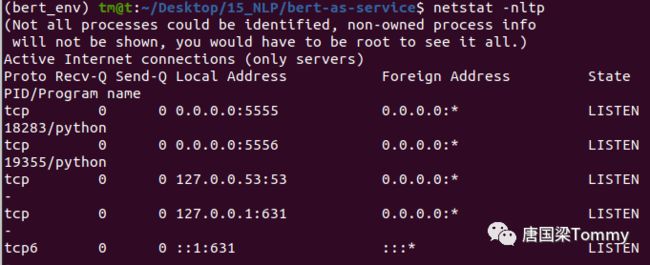
图09-01
② 命令:kill -9 18283 19355 【注意:你显示的PID或许与我的不同,不要直接拷贝运行】

图09-02
第二步:启动bert服务
①命令:bert-serving-start -model_dir=./chinese_L-12_H-768_A-12/ -num_worker=2
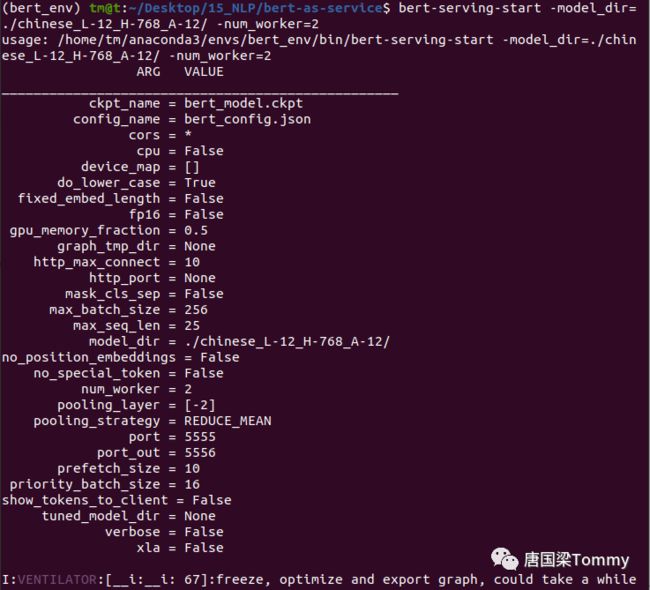
图09-03 部分输出信息截图
② 参数解释【详细参数解释,请查看bert-as-service github开源项目的README.md】
model_dir : 预训练的BERT模型
max_seq_len : 句子的最大长度,默认值为25
num_worker : 运行BERT模型的CPU或GPU数量
port : 从客户端向服务端推送数据的端口
port_out : 从服务端向客户端发送结果的端口
第三步:启动客户端,并从客户端输入数据,传给服务端计算并返回结果
① 脚本文件test_bert_service.py的代码内容如下:
# 导入依赖包
from bert_serving.client import BertClient
import numpy as np
# 定义类
class BertModel:
def __init__(self):
try:
self.bert_client = BertClient(ip='127.0.0.1', port=5555, port_out=5556) # 创建客户端对象
# 注意:可以参考API,查看其它参数的设置
# 127.0.0.1 表示本机IP,也可以用localhost
except:
raise Exception("cannot create BertClient")
def close_bert(self):
self.bert_client.close() # 关闭服务
def sentence_embedding(self, text):
'''对输入文本进行embedding
Args:
text: str, 输入文本
Returns:
text_vector: float, 返回一个列表,包含text的embedding编码值
'''
text_vector = self.bert_client.encode([text])[0]
return text_vector # 获取输出结果
def caculate_similarity(self, vec_1, vec_2):
'''根据两个语句的vector,计算它们的相似性
Args:
vec_1: float, 语句1的vector
vec_2: float, 语句2的vector
Returns:
sim_value: float, 返回相似性的计算值
'''
# 根据cosine的计算公式
v1 = np.mat(vec_1)
v2 = np.mat(vec_2)
a = float(v1 * v2.T)
b = np.linalg.norm(v1) * np.linalg.norm(v2)
cosine = a / b
return cosine
if __name__ == "__main__":
# 创建bert对象
bert = BertModel()
while True:
# --- 输入语句 ----
input_a = input('请输入语句1: ')
if input_a == "N" or input_a == "n":
bert.close_bert() # 关闭服务
break
input_b = input('请输入语句2: ')
# --- 对输入语句进行embedding ---
a_vec = bert.sentence_embedding(input_a)
print('a_vec shape : ', a_vec.shape)
b_vec = bert.sentence_embedding(input_b)
print('b_vec shape : ', b_vec.shape)
# 计算两个语句的相似性
cos = bert.caculate_similarity(a_vec, b_vec)
print('cosine value : ', cos)
print('\n\n')
# 如果相似性值大于0.85,则输出相似,否则,输出不同
if cos > 0.85:
print("2个语句的含义相似")
else:
print("不相似")
② 重新打开一个命令行窗口,运行如下的脚本文件【注意:按照前面的操作方式,进入到虚拟环境下。如果忘记如何操作,请往前查看。】
命令:python test_bert_service.py
③ 然后根据信息提示,分别输入2个语句,长度任意。
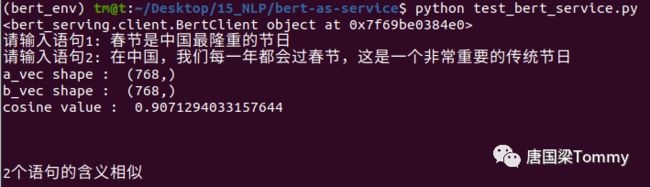
图09-04
解释:以上两个句子的含义相似度为0.907,根据我在代码中设定的阈值,如果相似度超过0.85,即可认为这两个句子的含义一致。反之,则不相同。
④ 当输入 N 或 n , 则退出程序

图09-05
本文转自:bert-as-service 详细使用指南 - 01 - 云+社区 - 腾讯云https://github.com/hanxiao/bert-as-service https://cloud.tencent.com/developer/article/1886981
https://cloud.tencent.com/developer/article/1886981