用MNIST数据集搭建简单卷积神经网络
一、MNIST数据集简介
MNIST数据集是NIST(National Institute of Standards and Technology,美国国家标准与技术研究所)数据集的一个子集,为手写数字数据库,由60000个例子组成的训练集,以及一个由10000个例子组成的测试集。对于想上尝试学习技术和模式识别方法的人来说,这是一个很好的数据库,在预处理和格式化方面花费的精力最少。
MNIST 数据集获取:http://yann.lecun.com/exdb/mnist/ 获取
二、搭建简单卷积神经网络
1.导入库文件和模块
import torch
import numpy
from torchvision import transforms #处理图像
from torchvision import datasets #处理数据集
from torch.utils.data import DataLoader #加载数据集
import torch.nn.functional as F #导入激活函数
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号补充:
import datasets是为了方便下载数据集,如MNIST、ImageNet、CIFAR10等
import transforms是pytorch中的图像预处理库,一般用Compose把多个步骤整合到一起
2.数据处理
#图像处理函数
transform = transforms.Compose([
transforms.ToTensor(),#将nump.ndarray转化成tensor
transforms.Normalize((0.1307,),(0.3081,))#归一化处理 (x-u)/s
])补充:
ToTensor()是将shape为(H, W, C)的nump.ndarray或img转为shape为(C, H, W)的tensor
Normalize()标准化处理,标准化系数就是计算要用到的均值和标准差,mnist的均值和标准差为0.1397和0.3081,这些系数都是数据集提供方计算好的数据
3.数据下载
#下载数据集,导入MNIST
train_dataset = datasets.MNIST(
root='/Users/ivy/test2015/dataset/mnist', #下载之后保存的文件路径
download=True, #若本地没有数据集,传入值为True(表示当root指定的路径下没有数据时,自动从下载MNIST,否则就不自动下载)
train=True, #是否是训练集True是训练集
transform = transform #对数据及逆行处理
)
test_dataset = datasets.MNIST(
root='/Users/ivy/test2015/dataset/mnist',
download=True,
train=False, #False是测试集
transform= transform
)补充:
root 指定MNIST数据集存放的路径
train 设置为True表示导入的是训练集,False为测试集
transform 指定导入数据集时需要进行何种变换操作
download 设置为True表示当root参数指定的数据集存放的路径下没有数据时,则自动从网络上下载MNIST数据集,否则就不自动下载
4.数据加载导入
根据上一步的dataset数据集构造DataLoader,加载MNIST数据集
#加载MNIST数据集
#归一化之后的训练集
train_loader = DataLoader(
dataset=train_dataset,
batch_size=64,
shuffle=True)
#归一化之后的测试集
test_loader = DataLoader(
dataset=test_dataset,
batch_size=64,
shuffle=True)补充:
dataset指定欲装载的MNIST数据集是训练集还是测试集
batch_size 设置了每批次装载的数据图片为64个(自行设置)
shuffle 设置为True表示在装载数据时随机乱序,常用于进行多批次的模型训练
加载完成后,可以加载任意图片看看效果
#显示数据集
for i, (images, labels) in enumerate(train_loader):
print(i)#下标
print(images)#64个图片 是64*1*28*28
print(labels)#64个图片对应的label 64*1
plt.imshow(images[1].resize(28,28))
plt.show()
break补充:这一步可以打印images和labels的数据
5.构建CNN模型
构建CNN网络模型,采用两层卷积层,卷积核5*5,激活函数ReLu,池化采用最大池化,最后拼接全连接层
#构建CNN模型
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc1 = torch.nn.Linear(320,10)
def forward(self,x):
#每次训练取多少元素
batch_size = x.size(0)
#先做Relu在做pooling
x = self.pooling(F.relu(self.conv1(x)))
x = self.pooling(F.relu(self.conv2(x)))
x = x.view(batch_size,-1)
x = self.fc1(x)
return x
#构建模型
model = Net()
6.构建损失和优化器
#构建损失
criterion = torch.nn.CrossEntropyLoss()
#构建优化器
optimizer = torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
7.训练模型
#训练模型
def train(epoch):
running_loss = 0
#datas 数据,1*batch_size*28*28 label
for batch_idx,datas in enumerate(train_loader,0):
inputs,targets = datas
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs,targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
#输出300次的平均损失
if batch_idx % 300 == 299:
print('[%d,%5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0补充:
最后一步是每计算300次的batch就输出300次平均的loss,这样便于查看模型的训练情况
batch_idx是把一个批次的数据放入模型中进行训练,如果现在有1000张图片,把批次大小设置为100,就是每次把100张图片放入模型中,一共要放入10次,batch_index就代表是第几个批次的数据
8.测试模型
#测试模型
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
image,label = data
output = model(image)
# _代表最大的元素 pre代表索引 索引本质就代表了预测元素值
_,pre = torch.max(output.data,dim=1)
total += label.size(0)
correct += (pre==label).sum().item()
print('准确率为:%d %%'%(100*correct/total))
if __name__ == '__main__':
for epoch in range(3):
#训练一次全部的数据 就测试一次准确率
train(epoch)
test()
整合以上代码,用python编译器进行编译,训练结果如下:
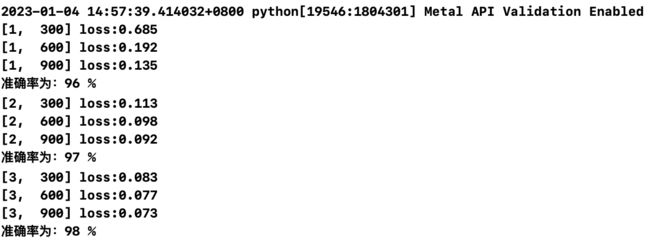
以上就是用MNIST数据集搭建简单的卷积神经网络并进行训练和测试的过程