史上最简单的LSTM文本分类实现:搜狗新闻文本分类(附代码)
本文主要介绍一下如何使用 PyTorch 实现一个简单的基于self-attention机制的LSTM文本分类模型。
目录
- LSTM
- self-attention机制
- 准备数据集
-
- 数据集处理
- 设置输入数据参数
- 训练模型
-
- 训练模型效果
- 测试模型
-
- 测试模型效果
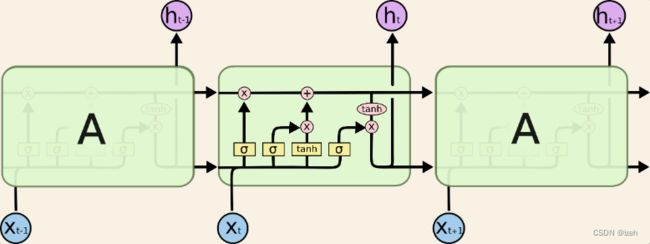
LSTM
LSTM是RNN的一种变种,可以有效地解决RNN的梯度爆炸或者消失问题。
self-attention机制
总的来说self-attention机制分为三步
第一步: query 和 key 进行相似度计算,得到权值:
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和:

准备数据集
这里因为我只是想跑一个简单的基于LSTM文本分类的模型,所以并没有用什么非常大型的数据集,而且数据集的格式多种多样,不同的数据集有不同的处理方式,所以为了处理方便,本文选择的是搜狗新闻的数据集总数为五万条,类数为10类,每个类别共5000条数据。
数据集处理
数据集我放在了自己的百度网盘,下载好后放在自己的代码的文件夹下就好,链接如下:
链接:链接: https://pan.baidu.com/s/1eoRwR3v1-hArjxknm6psFQ .
提取码:bz76
百度网盘分享的data文件夹里包括了四个文件,其中两个是训练集和验证集,另外两个分别是停用词和一个自己写的处理文本的工具。全部放在代码运行的文件夹下即可。
下图是已经分词完毕的数据:

数据集处理代码
import re
import copy
import time
import jieba
import string
import torch
import numpy as np
import pandas as pd
from torch import nn
import torch.optim as optim
import torch.utils.data as Data
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torchtext.legacy import data
from torchtext.vocab import vectors
from torch.utils.data import DataLoader
from sklearn.metrics import accuracy_score, confusion_matrix
from torchtext.legacy.data import Field, TabularDataset, Iterator, BucketIterator
from torch.autograd import Variable
stop_words = pd.read_csv("./stop_words.txt", header=None, names=["text"])
def chinese_pre(text_data):
# 操字母转化为小写,丢除数字,
text_data = text_data.lower()
text_data = re.sub("\d+", "", text_data)
##分词,使用精确模式
a = jieba.cut(text_data, cut_all=True)
# 毋丢停用词和多余空格
text_data = [word.strip() for word in text_data if word not in stop_words.text.values]
# 贽处理后的词语使用空格连接为字符串
text_data = " ".join(a)
return text_data
class DataProcessor(object):
def read_text(self, is_train_data):
if (is_train_data):
df = pd.read_csv("./cnews_train1.csv")
else:
df = pd.read_csv("./cnews_val1.csv")
return df["cutword"], df["label"]
def word_count(self, datas):
# 统计单词出现的频次,并将其降序排列,得出出现频次最多的单词
dic = {}
for data in datas:
data_list = data.split()
for word in data_list:
if (word in dic):
dic[word] += 1
else:
dic[word] = 1
word_count_sorted = sorted(dic.items(), key=lambda item: item[1], reverse=True)
return word_count_sorted
def word_index(self, datas, vocab_size):
# 创建词表
word_count_sorted = self.word_count(datas)
word2index = {}
# 词表中未出现的词
word2index["" ] = 0
# 句子添加的padding
word2index["" ] = 1
# 词表的实际大小由词的数量和限定大小决定
vocab_size = min(len(word_count_sorted), vocab_size)
for i in range(vocab_size):
word = word_count_sorted[i][0]
word2index[word] = i + 2
return word2index, vocab_size
def get_datasets(self, vocab_size, embedding_size, max_len):
# 注,由于nn.Embedding每次生成的词嵌入不固定,因此此处同时获取训练数据的词嵌入和测试数据的词嵌入
# 测试数据的词表也用训练数据创建
train_datas, train_labels = self.read_text(is_train_data=True)
test_datas, test_labels = self.read_text(is_train_data=False)
word2index, vocab_size = self.word_index(train_datas, vocab_size)
train_features = []
for data in train_datas:
feature = []
data_list = data.split()
for word in data_list:
word = word.lower() # 词表中的单词均为小写
if word in word2index:
feature.append(word2index[word])
else:
feature.append(word2index["" ]) # 词表中未出现的词用<unk>代替
if (len(feature) == max_len): # 限制句子的最大长度,超出部分直接截断
break
# 对未达到最大长度的句子添加padding
feature = feature + [word2index["" ]] * (max_len - len(feature))
train_features.append(feature)
test_features = []
for data in test_datas:
feature = []
data_list = data.split()
for word in data_list:
word = word.lower() #词表中的单词均为小写
if word in word2index:
feature.append(word2index[word])
else:
feature.append(word2index["" ]) #词表中未出现的词用<unk>代替
if(len(feature)==max_len): #限制句子的最大长度,超出部分直接截断
break
#对未达到最大长度的句子添加padding
feature = feature + [word2index["" ]] * (max_len - len(feature))
test_features.append(feature)
train_features = torch.LongTensor(train_features)
train_labels = torch.LongTensor(train_labels)
test_features = torch.LongTensor(test_features)
test_labels = torch.LongTensor(test_labels)
# 将词转化为embedding
# 词表中有两个特殊的词<unk>和<pad>,所以词表实际大小为vocab_size + 2
embed = nn.Embedding(vocab_size + 2, embedding_size)
train_features = embed(train_features)
test_features = embed(test_features)
# 指定输入特征是否需要计算梯度
train_features = Variable(train_features, requires_grad=False)
train_datasets = torch.utils.data.TensorDataset(train_features, train_labels)
test_features = Variable(test_features, requires_grad=False)
test_datasets = torch.utils.data.TensorDataset(test_features, test_labels)
return train_datasets,test_datasets
设置输入数据参数
在这一步主要是设置词表大小,词嵌入维度、句子最大长度和batch size等输入模型句子的各种参数。
processor = DataProcessor()
train_datasets,test_datasets = processor.get_datasets(vocab_size=6000, embedding_size=256, max_len=100)
batch_size = 16
train_dataloader = DataLoader(train_datasets,
batch_size=batch_size,
shuffle=True,
drop_last=True)
test_dataloader = DataLoader(test_datasets,
batch_size=batch_size,
shuffle=True,
drop_last=True)
训练模型
# -*- coding: utf-8 -*-
"""
Created on Fri May 29 09:25:58 2020
文本分类 双向LSTM + Attention 算法
@author:
"""
import torch.nn as nn
from Chinese_data_processor import DataProcessor
temp = 0
vocab_size = 6000 #词表大小
embedding_size = 256 #词向量维度
num_classes = 10 #二分类
sentence_max_len = 100 #单个句子的长度
hidden_size = 100
num_layers = 1 #一层lstm
num_directions = 2 #双向lstm
lr = 1e-3
epochs = 40
print_every_batch = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
filename = 'lstm.pth'
#Bi-LSTM模型
class BiLSTMModel(nn.Module):
def __init__(self, embedding_size,hidden_size, num_layers, num_directions, num_classes):
super(BiLSTMModel, self).__init__()
self.input_size = embedding_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.num_directions = num_directions
self.lstm = nn.LSTM(embedding_size, hidden_size, num_layers = num_layers,bidirectional = True)
self.attention_weights_layer = nn.Sequential(
nn.Linear(hidden_size, hidden_size),
nn.ReLU(inplace=True)
)
self.liner = nn.Linear(hidden_size, num_classes)
self.act_func = nn.Softmax(dim=1)
def forward(self, x):
#lstm的输入维度为 [seq_len, batch, input_size]
#x [batch_size, sentence_length, embedding_size]
x = x.permute(1, 0, 2) #[sentence_length, batch_size, embedding_size]
#由于数据集不一定是预先设置的batch_size的整数倍,所以用size(1)获取当前数据实际的batch
batch_size = x.size(1)
#设置lstm最初的前项输出
h_0 = torch.randn(self.num_layers*self.num_directions , batch_size, self.hidden_size).to(device)#
c_0 = torch.randn(self.num_layers*self.num_directions , batch_size, self.hidden_size).to(device)#
#out[seq_len, batch, num_directions * hidden_size]多层lstm,out只保存最后一层每个时间步t的输出h_t
# h_n, c_n [num_layers * num_directions, batch, hidden_size]
out, (h_n, c_n) = self.lstm(x, (h_0, c_0))
#将双向lstm的输出拆分为前向输出和后向输出
(forward_out, backward_out) = torch.chunk(out, 2, dim = 2)
out = forward_out + backward_out #[seq_len, batch, hidden_size]
out = out.permute(1, 0, 2) #[batch, seq_len, hidden_size]
# #为了使用到lstm最后一个时间步时,每层lstm的表达,用h_n生成attention的权重
h_n = h_n.permute(1, 0, 2) #[batch, num_layers * num_directions, hidden_size]
h_n = torch.sum(h_n, dim=1) #[batch, 1, hidden_size]
h_n = h_n.squeeze(dim=1) #[batch, hidden_size]
attention_w = self.attention_weights_layer(h_n) #[batch, hidden_size]
attention_w = attention_w.unsqueeze(dim=1) #[batch, 1, hidden_size]
attention_context = torch.bmm(attention_w, out.transpose(1, 2)) #[batch, 1, seq_len]
softmax_w = F.softmax(attention_context, dim=-1) #[batch, 1, seq_len],权重归一化
x = torch.bmm(softmax_w, out) #[batch, 1, hidden_size]
x = out[:,-1,:]
x = x.squeeze(dim=1) #[batch, hidden_size]
x = self.liner(x)
x = self.act_func(x)
return x
best_loss = 100000
model = BiLSTMModel(embedding_size, hidden_size, num_layers, num_directions, num_classes)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
loss_func = nn.CrossEntropyLoss()
for epoch in range(epochs):
model.train()
print("it is ",epoch)
print_avg_loss = 0
train_acc = 0
all_loss = 0
all_acc = 0
for i,(datas, labels) in enumerate(train_dataloader):
datas = datas.to(device)
labels = labels.to(device)
preds = model(datas)
loss = loss_func(preds, labels)
loss = (loss - 0.4).abs() + 0.4
optimizer.zero_grad()
loss.backward()
optimizer.step()
# scheduler.step()
#获取预测的最大概率出现的位置
preds = torch.argmax(preds, dim=1)
train_acc += torch.sum(preds == labels).item()
print_avg_loss += loss.item()
all_loss += loss.item()
all_acc += torch.sum(preds == labels).item()
if i % print_every_batch == (print_every_batch-1):
print("Batch: %d, Loss: %.4f" % ((i+1), print_avg_loss/print_every_batch))
print("Train Acc: {}".format(train_acc/(print_every_batch*batch_size)))
print_avg_loss = 0
train_acc = 0
temp = loss
if loss < best_loss:
best_loss = loss
state = {
"state_dict":model.state_dict(),
"optimizer":optimizer.state_dict()
}
torch.save(model.state_dict(),'lstm.pth')
训练模型效果
因为LSTM模型参数较少,所以训练速度还是比较快速的,并且第二、三代的时候就可以达到收敛,训练收敛图如下:

测试模型
model.eval()
import operator
from functools import reduce
from sklearn.metrics import classification_report
loss_val = 0.0
corrects = 0.0
y_true = []
y_pred = []
for datas, labels in test_dataloader:
datas = datas.to(device)
labels = labels.to(device)
y_true.append(labels.cpu().numpy().tolist())
preds = model(datas)
loss = loss_func(preds, labels)
loss_val += loss.item() * datas.size(0)
y_pred.append(preds.argmax(dim=1).detach().cpu().numpy().tolist())
#获取预测的最大概率出现的位置
preds = torch.argmax(preds, dim=1)
corrects += torch.sum(preds == labels).item()
test_loss = loss_val / len(test_dataloader.dataset)
test_acc = corrects / len(test_dataloader.dataset)
# print("Test Loss: {}, Test Acc: {},len{}".format(test_loss, test_acc,len(test_dataloader.dataset)))
y_p =reduce(operator.add, y_pred)
y_t =reduce(operator.add, y_true)
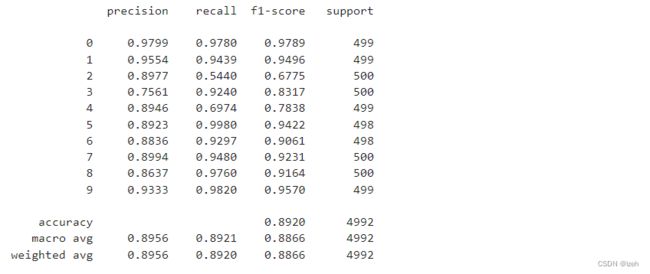
print(classification_report(y_true=y_t, y_pred=y_p,digits=4))
测试模型效果
本文模型主要采用了准确率、精确率、召回率和F1值,这四种比较常见的文本分类评价标准,具体数据如下图所示: