解读UDVD:《Unified Dynamic Convolutional Network for Super-Resolution withVariational Degradations》
目录
摘要:
结论:
Introduction:
CNN基础方法
本文贡献:
UDVD:
特征提取网络:
修复网络:
动态卷积的类型
动态卷积:
多级损失:
实验:
数据集和训练设置的细节:
UDVD的不同配置的比较:
动态核的学习:
通过使用合成图片用不同的应用设置评估UDVD:
多重退化的变化:
退化的空间变化:
Noise-Free degradation and variation:
使用真实图片的评估:
用于可变退化的统一动态卷积(UDVD)超分辨率网络
摘要:
深度卷积网络在单图像超分辨率上已经取得显著成果。尽管考虑到只有一个退化,最近的研究也包括了多种退化的效果以更好地映射到真实情况。然而大多数的工作都是假定有一个固定退化影响的组合,或者甚至对于不同的组合逐一训练单个的网络。取而代之,一个更加实用的方法是去训练一个网络去满足不同的情况。为了实现这一需求,文章提出了一种统一的网络去容纳来自跨图像变化(图像见间) and 图像内的(空间变化).变化。来自于现存工作的不同,我们合并了动态卷积,他是更加灵活可变的对于解决不同变化。带有非盲超分设置的单一图像超分,UDVD是被评估于具有一系列大量变化的合成与真实图像上。这个定性的结果表明了UDVD在各种现存工作上的高效性,大量实验表明UDVD取得了良好和具有竞争性的表现在合成与真实的图片上。
结论:
我们更进一步介绍了动态卷积的两种类型去提升性能。在整个连续的动态卷积中,多级损失也被用于逐渐去完善图片。这个单一的网络UDVD高效的解决了一系列真实世界图片的退化变化,包括跨图片和空间图片(cross-image and spatial variations)。UDVD在合成和真实图像上进行评估,具有不同的退化变化影响。进行全面的实验,将 UDVD 与各种现有作品进行比较。通过定性结果,我们证实了动态卷积对各种现有作品的有效性。广泛的实验表明所提出的 UDVD 在合成图像和真实图像上均实现了良好或可比较的性能。
Introduction:
由于SISR是通过LR去重构HR,这样的逆属性性质使得它成为一个病态问题。深度卷积神经网络已经被广泛的采纳去解决SISR问题并且取得了显著性的成功。尽管如此,大多数方法都是假定了一个固定的组合方式,比如模糊和双三次下采样。这样的假定却限制了它们的能力,去处理带有多级退化的实际情况。
CNN基础方法
在具有多种退化的SISR背景下提出了几种CNN基础方法。这些方法通过非常多样化的设置和配方解决了这个问题。Shocher训练一个小图像特定的网络,用于处理特定图像的不同退化。在这种方法中,单个网络每当存在退化变化时,必须进行训练,例如,图像之间的不同退化效果。为了去解决变化的退化问题,zhang提出了SRMD并且训练一个单一网络去解决多种变化,包括模糊和噪声。其中,退化类型都是被预定义好的,也是熟知的非盲设置。据我们所知,SFTMD 是盲设置的最新作品之一,它提出了空间特征变换(SFT)和迭代核校正(IKC)来处理有限的盲区退化。本文采纳了同SRMD的相同的设置,其中单个统一网络被训练为了变化的退化。
为了处理退化效应的变化,一个统一的网络有望适应两种类型的变化,即跨图像变化(图像间)和空间变化(图像内)。图一:在BSD100中,将不同的降级效果应用于基准图像(bench-marking image)的不同区域中。相比较于用一个固定退化设置的方法,RCAN和ZSSR,所提出的方法实现了相似的质量(红色),同时有效地适应了其他变化(图1中的绿色、紫色和蓝色(模糊、噪声))。
另一方面,在RCAN和ZSSR中,由于不了解其变化,所以可以观察到令人并不满意的质量效果。第4节将讨论与广泛的现有作品进行进一步讨论和比较。

不同于最直接可比的方法SRMD,本文探索了动态卷积去更好的解决带有变化退化的非盲超分问题。动态卷积是远比标准方法更灵活。一个标准的卷积学习到的核可以最小化穿过的每个像素点产生的错误。动态卷积使用参数生成网络生成每个像素核。此外,标准卷积的内核与内容无关,在训练后是固定的。相反,动态卷积是内容自适应的,它容纳不同的输入即使在训练之后。本篇文章中,我们合并了动态卷积,并且提出了可变退化的统一动态卷积网络即UDVD
本文贡献:
- 提出了UDVD,用于解决具有可变退化的非盲SISR问题。
- 更进一步提出了两种动态卷积去提升性能,并且我们在整个连续的动态卷积中合并了多级损失去逐步修复图像。
- 我们对动态卷积的性能影响进行全面分析,并研究动态卷积的多种配置。
详细介绍UDVD、不同类型的动态卷积以及多级损失:
本篇文章专注于具有退化影响的SISR,包括模糊、噪声和下采样。这些退化影响在实际应用中能够同时发生。退化过程表达如下:
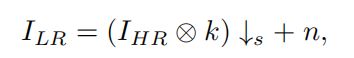
k:模糊核s:下采样范围n:噪声
我们利用各向同性的高斯模糊核,噪声利用带有协方差的加法白高斯噪声,双三次下采样。通过控制退化影响的参数,可以合成更加真实的退化用于SISR的训练。
非盲设置:假定是给定真实值的退化,非盲的结果给盲方法提供了上限,其中估计了退化。表1、2能观察结果。正如上述提到的,非盲设置的改进提高了盲方法的性能上限。任何退化估计的方法都能够被预置去扩展盲设置方法。
UDVD:

该架构由一个特征提取网络和一个优化网络(refinement network)组成。特征提取网络是设法提取输入图像的高级别特征(high-level features),诸如全局信息(global context),局部细节(local details)等等。然后,优化网络学习增强图像并将其与提取的高级特征一起进行上采样。
使用可变退化进行训练:
给定一个HR图像,退化过程如下:LR部分:应用各向同性高斯模糊核尺寸为p*p,双三次下采样图像,最后使用加法白高斯噪声,噪声级别为σ。生成的LR图像尺寸是C*H*W。退化映射图D我们同样通过使用PCA技术将模糊核投影到t(默认是15)维向量,然后将噪声级别为σ的额外维度连接到一个(1+t)维向量。比如向量被延伸以获得一个大小为(1+t)*H*W的退化映射图D。最后我们将LR图像I0同退化映射图D进行连接作为UDVD的输入。
特征提取网络:
在UDVD中,输入首先进入的是特征提取网络以提取高级别特征(high-level features),然后,高级别特征和输入的图像I0会被一起送入到修复网络中生成HR。特征提取网络有N个残差块,它们都是由卷积(3*3,通道128)和ReLU函数组成.
修复网络:
通过提取的特征图,修复网络进一步分配M个动态块进行特征转换。请注意,一个动态块可以有选择被扩展,以使用特定速率 r 执行上采样。动态卷积的实现细节将在 3.3 节中介绍。在动态块中m,输入图像Im−1被发送到3个3×3个卷积层,分别具有16、16和32个通道,然后与特征提取网络的高级特征图F连接。最后将生成的特征图转发到两条路径。
第一条通道是一个3*3的卷积层去预测每像素核,生成的每像素核被保存在一个有着k*k通道维度的张量中,其中 k 是每像素核的核大小。当上采样加倍时,通道维度是k*k*r*r,r是上采样速度。k默认是5,预测的每像素核会被用到在Im-1上去进行动态卷积操作生成输出Om.
第二条通道:包括两个3*3的卷积层,通道分别是16和3,用来生成残差图像Rm,以增强高频细节。
残差图像Rm然后被添加在动态卷积操作的输出Om,为了输出图像Im。子像素卷积层被用于对齐路径之间的分辨率。
动态卷积的类型
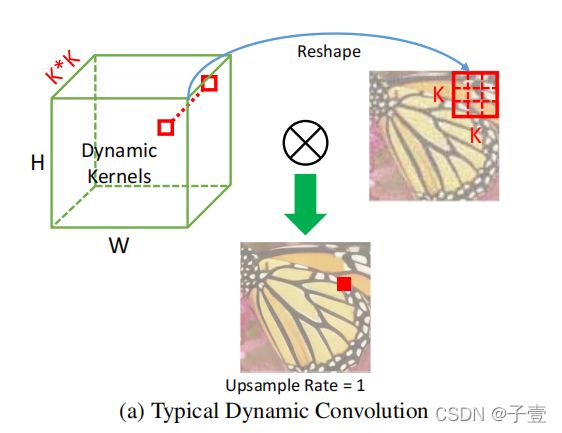
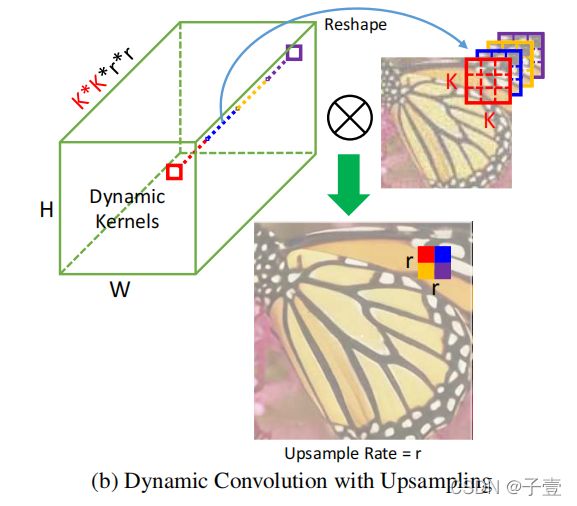
通常来说,当输入和输出分辨率相同时,会使用典型动态卷积(a),取决于使用的情况,上采样过程也会被整合到动态卷积当中(b).
动态卷积:
在一个典型的动态卷积中,卷积是通过使用内核大小 k × k 的每像素核 K 进行的。公式表示如下:
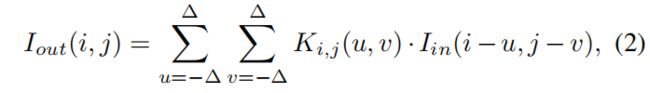
In、out是输入和输出图像,i,j是图像中的坐标,u,v是每一个Ki,j的坐标,Δ = k/2_x0005_(向下取整,不大于它的最大整数),这些像素内核对附近的像素执行加权和,并逐个像素地增强图像质量。默认设置:有 H × W大小的内核,相应的权重在通道之间共享。通过在方程 2 中引入额外的维度 C,动态卷积可以扩展到跨通道的独立权重。
集成上采样,在相同的patch上执行r平方的卷积以创建r*r的像素:
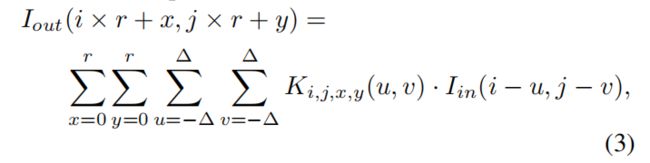
x和y是每一个r*r输出块的坐标。Iout的分辨率是Iin的r倍。我们利用r2HW核去生成rH*rW像素作为Iout。当集成上采样时,权重会在跨通道间被共享以避免维度的curse.
多级损失:
在每一个动态块中,会计算Ihr和中间图片的损失。
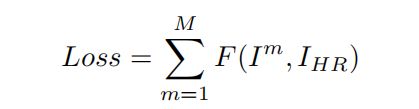
M是动态块的个数,F是L2损失和感知损失函数,为了去获得一个高质量结果图,我们会从每一个动态块中进行最小化总损失。
实验:
数据集和训练设置的细节:
使用高质2K图像(DIV2K、Filck2K).退化图像根据公式1合成。各向同性高斯模糊核的核宽度是[0.2,3],并且核尺寸被固定在15*15.对于噪声,使用AWGN噪声级别是在[0,75].统一的采样过程会被用于生成所有的参数。在训练时:退化的LR图像会被剪裁为48*48的patch,相应的HR图像会被剪裁为96*96、144*144以及192*192分别对应x2、x3和x4的倍数。这些patch会被随机的进行水平翻转、垂直翻转和90°翻转。我们设定最小的batch为32.Adam优化同多级L2损失被一起使用。学习率被初始化为10的-4,每经过2*10的-5步就减小一半。用NVIDIA RTX 2080 Ti GPU
在Set5,Set14和BSD100以及真实图像上进行验证,所有模型都在RGB通道上训练,在YCbCr的Y通道上用PSNR、SSIM评估。
UDVD的不同配置的比较:
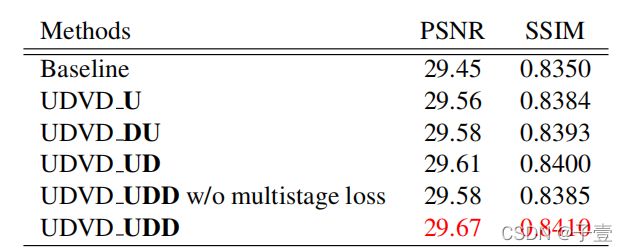
该表总结了不同的UDVD配置的定量对比
Baseline:只有一个特征提取网络包含15个残差块和一个子像素层。尽管如此,在修复网路中,比较了动态网络的不同配置。在这些配置中,D代表了包含一个典型动态卷积的块,U代表集成了上采样的动态卷积。动态块提升了在baseline配置上的表现,特别是UD配置实现了更好的表现。表中的消融实验也证明了多级损失的高效性。我们使用了UDVD_UDD进行x2和x3,而UDVD_UUDD(两个单独的上采样步骤)用于x4
动态核的学习:

UDVD生成动态核去适应图片内容和不同的退化。(a)表示为不同的内容生成的不同的核,同样,(b)表示生成核进一步适应到应用退化,(c)表示无论内容如何,适应行为在不同的退化中都是不同的。这些观察结果证明了UDVD是有能力通过生成动态核解决空间变化,这些动态核是考虑了内容和退化的空间差异。
通过使用合成图片用不同的应用设置评估UDVD:
我们用一系列的应用设置评估UDVD,涵盖了变化的和固定的退化。合成图片是针对这些设置生成的。我们将UDVD同一套全面的其他方法进行比较,仅仅是用非盲设置。
多重退化的变化:
用退化影响的不同变化评估UDVD,包括双三次下采样、各向同性高斯模糊核和AWGN.考虑2、3、4倍的双三次下采样。对于各向同性的高斯模糊,核的宽度时0.2、1.3和2.6.AWGN的噪声级别时15和50。
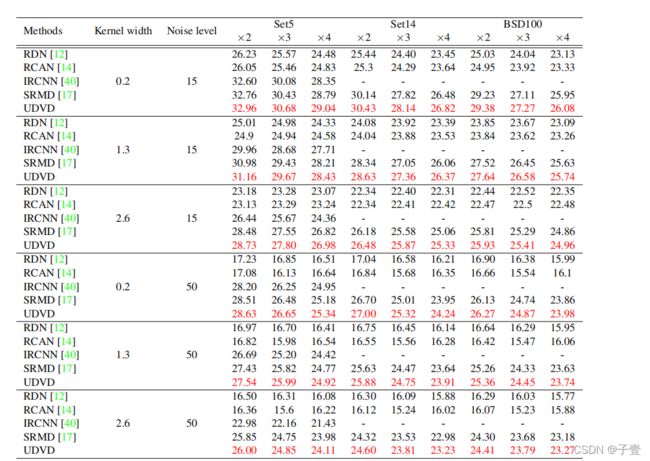
该表将UDVD同之前的方法进行比较。由于没有使用多重退化,RDN和RCAN的效果都不是很好。对于使用了多重退化的方法,将UDVD同两个熟知的方法IRCNN和SRMD。如表所示,UDVD持续取得了很好的PSNR,即使是最艰难的情况,核宽度2.6,噪声级别50.
退化的空间变化:
为了去验证动态卷积的优点,我们进一步进行了实验去考虑退化的空间变化。退化的LR图像是被合成的,其中核宽度相应的范围是以[0.2,2]从左至右逐渐增加,同理,噪声级别[5,50]从左至右逐渐增加。我们将UDVD同最相关的工作SRMD相比,即不用动态卷积的空间变化。
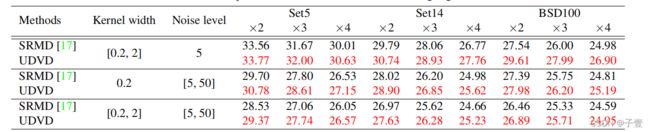
在表3中,所有的设置区间,UDVD都频繁的超过SRMD。总结来说,UDVD在PSNR上达到了一个十分惹人注目的效果。定性的对比也阐明在图5中。
不考虑空间变化,RCAN仅仅能够解决固定退化(红色代表轻度退化),但是却失败于其他情况(蓝色代表重度退化)。在空间变化上,UDVD能比SRMD实现更加清晰和锐化的图片效果。这个实验结果表明了UDVD不仅能够处理多重退化还能够解决空间变化。
Noise-Free degradation and variation:
在这个实验中,我们训练UDVD实现noise-free degradation(移除噪声退化)以便能同更多的实验进行比较。表4展现了UDVD无噪声退化同其它方法比较的结果。相比于SRMDNF和SFTMD,在更大倍数(x3、x4)的BSD100数据集上,UDVD实现了更有竞争力的结果。
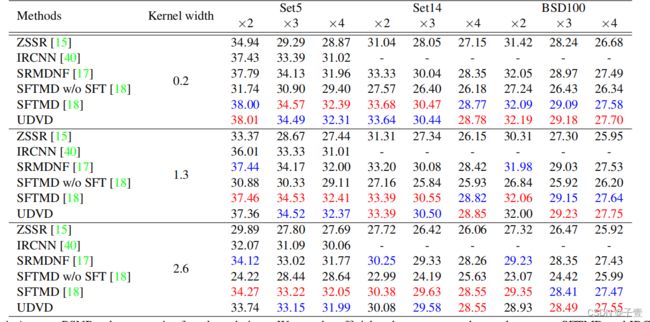
请注意,SFTMD主要受益于空间特征变换 (SFT),该变换对退化信息应用仿射变换,而不是将其与输入图像连接起来。在不失去普遍性的情况下,UDVD还可以扩展为采用SFT层以进行进一步改进。
固定退化:去和最先进的基于固定退化的方法去比较,我们将UDVD同两个使用最广泛的固定退化BI和DN进行比较。BI只包括了双三次下采样。而DN应用双三次下采样并且添加噪声级别为30的AWGN(加性高斯白噪声)。表5展现了BI和DN用x3的PSNR和SSIM的结果。只有SRMD和UDVD用了单一的模型去处理BI和DN退化,其他方法都是混着模型用的。UDVD可以产生更具竞争力的效果。这也证明UDVD能够适应各种退化并且实现好的结果。

使用真实图片的评估:
由于真实图片没有真实退化,因此,像[17]SRMD(噪声和模糊核同时作为网络的输入,并且提出了维度拉伸的方法)中那样对退化参数执行手动网格搜索,以获得视觉上令人满意的结果。图6阐明了对UDVD、RCAN、ZSSR、SRMD广泛使用真实图像“青蛙”、“芯片”的定性比较。

大多数的方法都产生了明显的伪影。RCAN产生了模糊的边界并且不能够解决噪声。ZSSR趋向于产生过于平滑的结果。虽然SRMD很成功的去除了伪影,但是没有能成功的实现锐化边界。比对下来,UDVD更成功的重构了更清晰的图像。图7表明了通过UDVD利用不同的退化(退化参数不同)估计重构图像。(蓝色和红色)不同的patch在不同的退化参数上有着良好的重构结果。这证明了在真实图像中可变退化的存在。总结下来,6、7都证明了对于真实图像,UDVD的有效性。
