知识图谱问答 | (3) 关系分类概述
本篇博客主要基于微软亚洲研究院段楠老师的《智能问答》第三章 关系分类 进行整理。
1. 简介
给定一段自然语言文本以及该文本中出现的若干实体 ( e 1 , . . . , e n ) (e_1,...,e_n) (e1,...,en), 关系分类(relation classification)任务的目的是识别这些实体 ( e 1 , . . . , e n ) (e_1,...,e_n) (e1,...,en)之间满足的语义关系(关系分类也叫 关系抽取、关系识别等)。由于全部可能的关系集合通常是预先指定好的(例如知识图谱中的全部谓词(边上的标注/关系)),因此该任务可以采用分类方法完成。最基本的关系分类任务是判断文本中同时出现的两个实体 e 1 , e 2 e_1,e_2 e1,e2间的关系。
1998年,MUC首次提出关系分类评测。该任务针对文本中出现的人名、机构名、产品名和地点名等实体,预测两两实体之间可能出现的三种关系:①机构名和地点名之间的Location_Of关系;②人名和机构名之间的 Employee_of关系;③产品名和机构名之间的Product_Of关系。
1999年,ACE为关系分类评测提供了更大规则的数据集,并支持不同语种的任务。2008年,ACE英文关系分类评测涉及了7个大类18个小类的关系集合,该任务极大地推动了实体分类研究的发展。
2009年,TAC的KBP任务基于无结构文本抽取知识,并将其用于知识图谱的构建和扩展,实体链接和关系分类是该任务中最重要的两个子任务。
SemEval 也提供关系分类评测任务。该会议在2010年发布了基于19种关系的关系分类评测数据集,将实体关系分类任务推向了一个新的高度。
2012年,Google 对外发布了基于知识图谱(freebase)的语义搜索和智能问答服务,并开放了该知识图谱供工业界和学术界使用。大规模知识图谱的出现极大地推动了智能问答研究的发展。基于此类知识图谱,斯坦福、Facebook 和微软等研究机构分别构建并开放了基于知识图谱的智能问答评测数据集,包括WebQuestions、SimpleQuestions、NLPCC-KBQA等,这些数据集涉及的问答任务需要问答系统能够针对输人问题进行准确的关系分类。由于知识图谱中包含的关系(即谓词)数目远超上述关系分类任务涉及的关系数目,因此近年来出现了很多新型的关系分类方法。主要包括模板匹配方法、监督学习方法和半监督学习方法。
2. 模版匹配方法
模板匹配方法是关系分类任务中最常见的方法。该类方法使用一个模板库对输入文本中两个给定实体进行上下文匹配,如果该上下文片段与模板库中某个模板匹配成功,那么可以将该匹配模板对应的关系作为这两个实体之间满足的关系。
本小节将介绍两种模板匹配方法:第一种方法是基于人工模板完成关系分类任务,第二种方法是基于统计模板完成关系分类任务。
基于人工模板的关系分类主要用于判断实体间是否存在上下位关系(Hyponymy).
Hearst 1992年提出Hearst Pattern 方法[1],用于判断文本中出现的两个实体之间是否满足上下位关系。下表给出 Hearst Pattern 包括的正则表达式模板。其中,每个 N P i ( i ≥ 1 ) NP_i(i\geq 1) NPi(i≥1)和 N P 0 NP_0 NP0之间都满足上下位关系。


上下位关系分类的主要目的是抽取满足上下位关系的实体对,这些实体对能够帮助问答系统对答案类型进行正确的判断。例如,对于which city does Bill Gates come from这个问题,如果答案候选包括 Redmond 和 United States这两个实体,那么基于这两个实体对应的上位词就可以将答案候选 Unitied States 过滤掉,因为该问题寻找的答案类型(即上位词)需要是一个 city,而 Unitied States 对应的上位词是 counry.
Hearst Pattern基于词汇和句法信息制定严格的人工模板,该方法能够很好地从文本中抽取出满足上下位关系的实体对。但由于模板数目有限,该方法同样无法覆盖该关系可能对应的全部情况。例如,对于 animals other than dogs such as cats 就无法基于上述人工模板判断animal和dog/cat 之间存在的上下位关系,这是因为该文本无法匹配任何模板。
上下位关系的自然语言表达方式相对有限,采用人工模板(hearst pattern)就可以很好地完成分类任务。但对其他类型的关系而言,由于其对应的自然语言表达方式非常多,因此无法采用上述方式进行处理,这就引出基于统计模板的关系分类方法。
基于人工模板的关系分类在给定关系列表的基础上,从大规模数据中自动抽取和总结模板,并将抽取出来的高质量模板用于关系分类任务。该过程无需过多人工干预。
Ravichandran 等人提出基于搜索引擎的统计模板抽取方法,抽取结果可以用于关系分类和答案抽取任务[2]. 首先,该方法从待分类的全部关系集合中选择一个关系,例如 Birthday,并找到满足该关系的一个实体对,例如 Mozart(对应问题实体)和1756(对应答案实体)。然后,将该实体对作为查询语句,例如 Mozart+1756,提交到搜索引擎,并抓取搜索引擎返回的前n个结果文档。接下来,保留返回结果文档中同时包含该实体对的句子集合,例如(a)The great composer Mozart(1756-1791)achieved fame at a young age、(b)Mozart(1756-91)was a genius和(c)The whole world would always be indebted to the great music of Mozart(1756-1791)
,并对每个句子进行分词。最后,从保留句子集合中寻找包含上述实体对的最长子串,例如 Mozart(1756-,并将实体替换为非终结符得到一个模板,例如(-。同一个关系使用不同实体对能够抽取得到不同模板。例如,关系 Birthday 抽取的模板候选包括:(a)(-、(b)born in ,和(c)was born on 等。
给定一个关系,该工作采用如下方式计算每个模板候选对应的置信度。首先,选择满足当前关系的一个实体对(例如 Mozart 和 1756),将该实体对中的问题实体(例如 Mozart)单独作为查询语句提交给搜索引擎,并保留返回结果文档中包含该问题实体的全部句子。然后,计算给定模板 p a t t e r n i pattern_i patterni在该句子集合上的对应得分 P ( p a t t e r n i ) P(pattern_i) P(patterni):

上式中, C a C_a Ca表示该集合中成功匹配模版 p a t t e r n i pattern_i patterni、并且对应部分正好是答案实体的句子数目, C o C_o Co表示该集合中成功匹配 p a t t e r n i pattern_i patterni的句子数目。注意,在 C o C_o Co的计数过程中可以对应任意单词或短语,而不限于答案实体。按照P(·)可以对同一关系的不同模板候选进行得分,并保留置信度较高的模板用于关系分类任务。
在实际使用中,如果输入文本中某两个实体所在的上下文恰好能够匹配某个模板,那么该匹配模板对应的关系就可以作为对这两个实体之间关系的预测结果。
3. 监督学习方法
监督学习(supervised learning)方法使用带有关系标注的数据训练分析分类模型。本节把该类方法分为三类进行介绍:基于特征的方法、基于核函数的方法和基于深度学习的方法。
3.1 基于特征的方法
给定两个实体,基于特征的关系分类方法从该实体对所在上下文中抽取特征,并基于这些特征完成关系分类任务。
在特征方面,该类工作常用的关系分类特征包括:①词汇特征,表示两个实体名字中包含的单词;②词汇特征,表示文本中两个实体之间出现的单词;③数值特征,表示文本中两个实体之间出现的单词的数目;④数值特征,表示文本中两个实体之间出现的其他实体的数目;⑤类型特征,表示两个实体对应的类型(例如 Person,Location 和 Organization 等);⑥指示特征,表示两个实体是否出现在同一个名词短语、动词短语或介词短语中;⑦依存特征,表示在句法依存树中两个实体所依附的单词和该单词对应的词性标注。
在模型方面,Kambhatla基于最大熵(maximum entropy)训练关系分类模型[3],Zhou等人基于支持向量机 (support vector machine)训练关系分类模型[4]。
3.2 基于核函数的方法
基于特征的方法从两个实体所在上下文中抽取不同特征,用于关系分类任务。由于文本中包含多种不同类型的信息(例如词汇、词性标注、依存关系等),因此整个特征空间包含的特征数量非常大,很难选择合理的特征子集用于分类任务。针对该问题,研究者提出基于核函数(kernel function)的关系分类方法。
给定一个对象空间X,核函数K: X × X → [ 0 , ∞ ) X\times X \rightarrow [0,\infty) X×X→[0,∞)表示一个二元函数,该函数可以将X中任意两个对象 x , y ∈ X x,y\in X x,y∈X作为输入,并返回二者之间的相似度得分K(x,y)。核函数的定义可以采用很多种不同的形式。如果为每个对象定义一个特征向量Φ(·),那么两个对象x和y对应特征向量的点积 K ( x , y ) = ϕ ( x ) T ⋅ ϕ ( y ) K(x,y) = \phi(x)^T \cdot \phi(y) K(x,y)=ϕ(x)T⋅ϕ(y)可以作为核函数的一种实现形式。
对应到关系分类任务,给定输入文本T中两个实体 e 1 , e 2 e_1,e_2 e1,e2核函数方法采用下述方式计算这两个实体间满足关系r的置信度。首先,从标注数据中找到文本T’,保证T’包含实体对 e 1 ′ , e 2 ′ e_1',e_2' e1′,e2′并且 e 1 ′ , e 2 ′ e_1',e_2' e1′,e2′之间满足关系r. 然后,基于核函数计算T和T’之间的相似度K(T,T’),作为 e 1 , e 2 e_1,e_2 e1,e2之间满足关系r的置信度。该做法背后体现的思想是:如果两个实体对同时满足某个关系r,这两个实体对分别所在的上下文也应该相似,该相似度通过核函数计算得到。计算上下文相似度的方法包括基于字符串核(string kernel)的方法和基于树核函数(tree kernel)的方法。
给定字符串 x = x 1 , . . . , x ∣ x ∣ x=x_1,...,x_{|x|} x=x1,...,x∣x∣,字符串核定义如下:
- |x| 表示字符串的长度
- i = ( i 1 , . . . , i ∣ u ∣ ) i=(i_1,...,i_{|u|}) i=(i1,...,i∣u∣),表示x中|u|个位置索引,且满足 i 1 ≤ i 2 ≤ . . . ≤ i ∣ u ∣ i_1\leq i_2\leq ... \leq i_{|u|} i1≤i2≤...≤i∣u∣
- u = x[i] ,表示x中位置索引 i = ( i 1 , . . . , i ∣ u ∣ ) i=(i_1,...,i_{|u|}) i=(i1,...,i∣u∣)对应的字符串子串
- l i = i ∣ u ∣ − i 1 + 1 l_i = i_{|u|}-i_1+1 li=i∣u∣−i1+1, 子串u在字符串x中的跨度
- ∑ n \sum\limits^{n} ∑n 长度为n的字符子串集合
- ∑ ∗ = ⋃ n = 0 ∞ ∑ n \sum\limits^{*} = \bigcup\limits_{n=0}^{\infty}\sum\limits^{n} ∑∗=n=0⋃∞∑n,表示全部可能的字符子串集合
- λ l ( i ) \lambda^{l(i)} λl(i)表示位置索引 i = ( i 1 , . . . , i ∣ u ∣ ) i=(i_1,...,i_{|u|}) i=(i1,...,i∣u∣)对应的字符子串 u = x [ i ] u=x[i] u=x[i]的权重, λ ∈ ( 0 , 1 ] \lambda\in (0,1] λ∈(0,1]是衰减因子,惩罚长度过长或不连续的字符子串。
- ϕ u ( x ) = ∑ i : u = x [ i ] λ l ( i ) \phi_u(x) = \sum\limits_{i:u=x[i]}\lambda^{l(i)} ϕu(x)=i:u=x[i]∑λl(i),表示字符子串基于x对应的特征函数。u在x中可能出现多次,该特征值等于不同位置的u对应的权重之和。
基于上述定义,字符串核定义两个字符串x和y之间的相似度为:
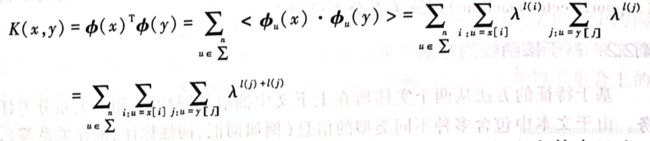
上式中, ϕ ( x ) , ϕ ( y ) \phi(x),\phi(y) ϕ(x),ϕ(y)分别表示x和y对应的特征向量。 为每个字符串显式生成特征向量具有指数级复杂度,针对这一问题,Lodhi等人提出基于动态规划的核函数计算方法[5].
例如,给定一个字符串x=cat,其对应的特征向量可以表示为:
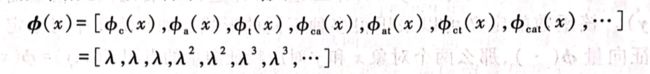
拿子串ct对应的权重 ϕ c t ( c a t ) \phi_{ct}(cat) ϕct(cat)和子串at对应的权重 ϕ a t ( c a t ) \phi_{at}(cat) ϕat(cat)相比,前者的权重是 λ 3 \lambda^3 λ3,后者的权重是 λ 2 \lambda^2 λ2,这是由于ct在cat中的跨度是3(3-1+1),at在cat中的跨度是2(3-2+1).
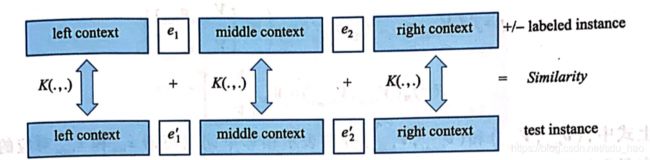
Bunescu和Mooney 将字符串核用于关系分类任务[6]。 给定带有关系标注的训练样本集合,该方法首先基于每个样本中出现的实体 e 1 , e 2 e_1,e_2 e1,e2将该样本切分为左端上下文 C l e f t C_{left} Cleft、中间上下文 C m i d d l e C_{middle} Cmiddle和右端上下文 C r i g h t C_{right} Cright三部分。然后,给定测试样本,根据其中出现的实体 e 1 ′ , e 2 ′ e_1',e_2' e1′,e2′对其进行同样的切分,生成 C l e f t ′ , C m i d d l e ′ , C r i g h t ′ C'_{left},C'_{middle},C'_{right} Cleft′,Cmiddle′,Cright′,并基于字符串核计算该样本与每个训练样本在上述三个上下文上的相似度 K ( C l e f t , C l e f t ′ ) , K ( C m i d d l e , C m i d d l e ′ ) , K ( C r i g h t , C r i g h t ′ ) , K(C_{left},C'_{left}),K(C_{middle},C'_{middle}),K(C_{right},C'_{right}), K(Cleft,Cleft′),K(Cmiddle,Cmiddle′),K(Cright,Cright′),。最后,对上述三个相似度得分进行加和,并用于训练多分类SVM模型完成关系分类任务。下图给出基于测试样本和一个训练样本进行相似度计算的示意图。
Zelenko等人将实体对所在句法树作为上下文[7] ,使用树核函数计算上下文之间的相似度。和字符串核相比,树核函数计算的是在两个句法树中共同出现的子树数目。给定两个子树 T 1 , T 2 T_1,T_2 T1,T2,树核函数检查 T 1 , T 2 T_1,T_2 T1,T2的根节点属性是否一致,如果一致,将1加到最终核函数返回结果中。对于根节点属性一致的两个子树。用children( T 1 T_1 T1)和children( T 2 T_2 T2)分别表示 T 1 , T 2 T_1,T_2 T1,T2中根节点对应的子树序列,并采用字符串核函数计算二者之间的相似度,并加到核函数返回结果中。不同于使用全部句法树信息,Bunescu 和 Mooney 仅使用两个实体在依存句法树之间的路径作为上下文[8].
和基于特征的方法相比,基于核函数的方法无需人工指定特征,但方法复杂度较高。
3.3 深度学习方法
基于特征的方法需要人工设计特征,用于关系分类任务。这类方法适用于标注数据量较少的情况。基于核函数的方法能够从字符串或句法树中自动抽取大量特征,用于关系分类任务。但这类方法始终是在衡量两段文本在子串或子树上的相似度,并没有从语义的层面对二者进行比较。此外,上述两类方法通常都依赖词性标注和句法分析的结果,用于特征抽取或核函数计算,这就导致词性标注和句法分析模块产生的错误会在整个关系分类流程中被不断传播和放大,并最终影响关系分类的效果。(级联模型,多个子模块)
近年来,随着深度学习技术的不断发展,端到端的关系分类方法开始占据主导地位。由于该类方法鲁棒性高并且无须人工指定特征,因此相关研究越来越多。
Socher等人提出基于循环神经网络(recursive neural network)的关系分类方法[9].
首先,该方法为输入句子中的每个单词x指定一个n维向量 v x ∈ R n v_x\in R^n vx∈Rn和一个矩阵 V x ∈ R n × n V_x\in R^{n\times n} Vx∈Rn×n. v x v_x vx使用该单词对应的(预训练)词向量进行初始化, V x V_x Vx使用高斯分布进行初始化。
然后,对于输入句子中待分类的实体 e 1 , e 2 e_1,e_2 e1,e2,在句法树中找到能够覆盖这两个实体的最小子树,并从该子树对应的叶子节点开始,通过自底向上的方式两两合并相邻两个单词或短语 x l e f t , x r i g h t x_{left},x_{right} xleft,xright对应的向量和矩阵,直到遍历至该子树对应的根节点时结束。
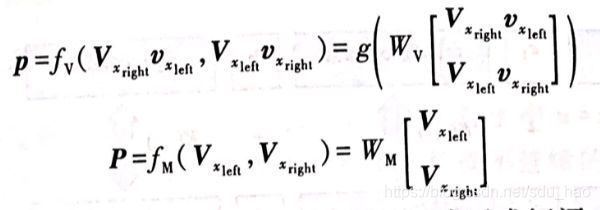
上式中, ( v x l e f t , V x l e f t ) , ( v x r i g h t , V x r i g h t ) (v_{x_{left}},V_{x_{left}}),(v_{x_{right}},V_{x_{right}}) (vxleft,Vxleft),(vxright,Vxright)分别表示相邻单词或短语 x l e f t , x r i g h t x_{left},x_{right} xleft,xright对应的向量和矩阵。 W V ∈ R n × 2 n , W M ∈ R n × 2 n W_V\in R^{n\times 2n},W_M\in R^{n\times 2n} WV∈Rn×2n,WM∈Rn×2n是合并操作对应的模型参数,g(·)表示一个非线性函数(例如 sigmoid 或tanh).上述合并操作确保了句法树每个中间节点对应的向量 p ∈ R n p\in R^n p∈Rn和矩阵 P ∈ R n × n P\in R^{n\times n} P∈Rn×n在维数上和叶子节点保持一致。
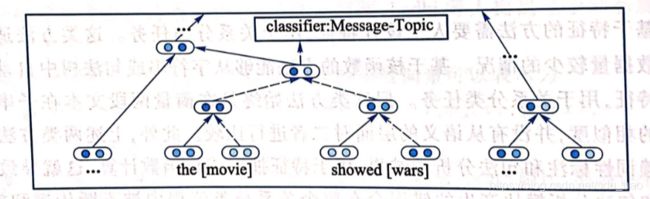
最后,基于根节点对应的向量p,使用 softmax 函数对关系集合中的关系候选进行打分和排序(基于关系集合,进行多分类),并选择得分最高的关系候选作为待分类实体 e 1 , e 2 e_1,e_2 e1,e2间满足的关系。该方法基于词向量和句法树本身的结构,将待分类的两个实体间的上下文转换为向量表示,有效地考虑了句法和语义信息,但并未特殊考虑实体本身在句子中的位置和语义信息。下图给出基于循环神经网络的关系分类方法。
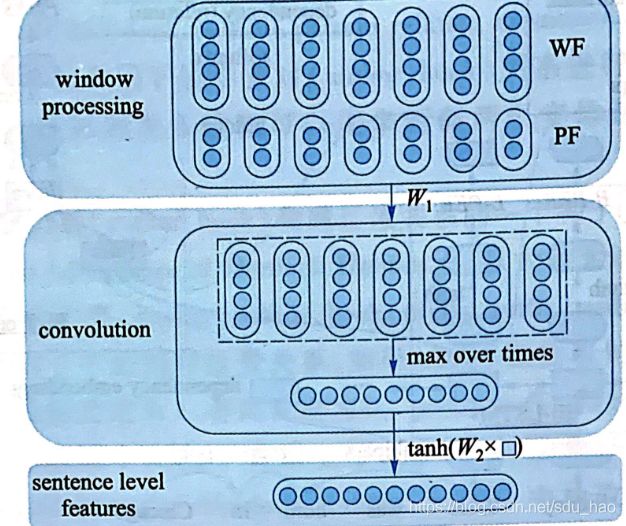
Zeng等人提出基于卷积神经网络(CNN)的关系分类方法[10]。首先,该方法为输入句子中每个单词w生成一个向量表示 v = [ v w ; ( v w p − v e 1 p ) ; ( v w p − v e 2 p ) ] v=[v_w;(v_w^p-v_{e_1}^p);(v_w^p-v_{e2}^p)] v=[vw;(vwp−ve1p);(vwp−ve2p)]。 v w v_w vw表示单词w对应的词向量, v w p v_w^p vwp表示单词w对应的位置向量,该向量随机初始化, ( v w p − v e 1 p ) , ( v w p − v e 2 p ) (v_w^p-v_{e_1}^p),(v_w^p-v_{e_2}^p) (vwp−ve1p),(vwp−ve2p)分别表示w和待分类实体 e 1 , e 2 e_1,e_2 e1,e2在向量空间上的距离。将位置向量引人关系分类任务是考虑到距离待分类实体越近的单词,对分类结果的影响可能越大。
然后,通过卷积操作将输入句子对应的向量表示序列转化为局部特征向量序列,并进一步通过最大池化生成全局特征向量。
最后,输出层将句子对应的全局特征向量转化为输出向量,并使用 softmax函数对关系集合中的关系候选进行打分和排序,选择得分最高的关系候选作为待分类实体 e 1 , e 2 e_1,e_2 e1,e2间所满足的关系。下图给出基于卷积神经网络的关系分类方法。
Miwa和Bansa提出基于递归神经网络(RNN)的关系分类方法[11]。
首先,该方法为输入句子中每个单词w生成一个向量表示,该向量表示由w对应的词向量 v ( w ) v^{(w)} v(w)。词性标注向量 v ( p ) v^{(p)} v(p)。依存句法类型向量 v ( d ) v^{(d)} v(d)。和实体标签向量 v ( e ) v^{(e)} v(e)连接组成。
然后,使用双向 LSTM将输入句子(单词序列/单词表示向量序列)转化为隐状态向量序列 { h 1 , . . . , h N } \{h_1,...,h_N\} {h1,...,hN}.每个隐状态向量 h t h_t ht,对应的输入是t-1时刻隐状态向量 h t − 1 h_{t-1} ht−1,以及t时刻单词 w t w_t wt对应的向量表示$$。在此基础上,该方法基于一个两层神经网络,通过自左向右的方式,预测每个单词对应的实体类型标注。

W ( e h ) , b ( e h ) , W ( e y ) , b ( e y ) W^{(e_h)},b^{(e_h),W^{(e_y)},b^{(e_y)}} W(eh),b(eh),W(ey),b(ey)表示待学习的模型参数,softmax操作从全部实体类型标注集合中选择最可能的标注作为单词 w t w_t wt的实体类型(基于实体类型标注集合做多分类/(命名)实体识别)。这里,实体标注准则采用常用的 BILOU(begin,inside,last,outside 和 unit)形式。B表示当前单词是某个实体的第一个词,I表示当前单词是某个实体的中间词,L表示当前单词是某个实体最后一个词,0表示当前单词不属于任何实体,U 表示当前单词是一个单词类型的实体。例如在下图的句子“In 1909,Sydney Yates was born in Chicago.”
中,单词Sydney和Yates 对应的实体类型预测结果分别是B-PER和L-PER,PER 表示该单词所在实体的类型是 PERSON.
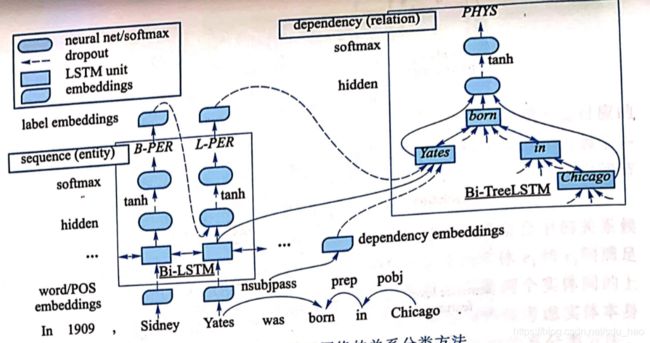
接下来,对于实体类型预测模块(实体识别)预测出来的两个实体 e 1 , e 2 e_1,e_2 e1,e2在当前句子对应的依存句法树中找到能够覆盖该实体对的最小依存句法子树,并采用TreeLSTM生成该子树对应的向量表示。
最后,基于子树根节点对应的 TreeLSTM 向量表示,使用 softmax 函数对关系集合中的关系候选进行打分和排序,并选择得分最高的关系候选作为待分类实体 e 1 , e 2 e_1,e_2 e1,e2间所满足的关系。
上述工作将实体识别和关系分类这两个任务融在同一个模型中完成。对于传统的关系分类任务,在给定实体对 e 1 , e 2 e_1,e_2 e1,e2情况下,可以基于 TreeLSTM 直接完成(关系)分类任务。
4. 半监督学习算法
4.1 基于自举的方法
基于自举(bootstrapping)的关系分类方法按照如下流程工作:首先,使用某个关系r对应的有限标注数据(即满足该关系的实体对集合),对无标注文本进行实体标注;然后,从标注结果中抽取出r对应的关系模板;接下来,将新抽取出来的模板应用到无标注文本上,获取更多满足关系r的实体对;上述过程不断迭代,直到达到预先指定的停止条件为止。该过程中抽取得到的关系模板可以用于后续的关系分类任务。通过上述描述可以看到,基于自举的关系分类方法需要满足两个条件:①对于给定关系r,需要少量满足该关系的实体对实例:②需要大量无标注文本,用于实体对扩展和关系模板抽取(一个关系r可以对应多个关系模版)。
Brin提出的 DIPRE(dual iterative pattern relation expansion)方法是自举法的典型代表[12]。该方法采用下述步骤对(author,book)关系进行实体对扩展和关系模板抽取,抽取得到的关系模板可以用来判断两个实体是否满足(author,book)关系。
- 首先,给定关系(author,book)和满足该关系的一个种子实体对集合(例如<Conan Doyle,The Adventures of Sherlock Holmes>),从大量无结构文档中抽取出具有如下格式的6元组:<order,author,book,prefix, suffix,middle>.其中,order 表示两个实体在句子中的相对位置关系,如果 author在抽取句子中的位置位于 book之前,order的值设定为1,否则设定为0.prefix、suffix 和 middle 分别表示这两个实体左端、右端和中间的字符串上下文。例如,从句子 Sir Arthur Conan Doyle wrote The Adventures of Sherlock Holmes in 1892中抽取出来的6元组是<1,Arthur Conan Doyle,The Adventures of Sherlock Holmes,Sir,in 1892,wrote>.
- 然后,按照order和middle 部分对抽取得到的6元组进行分组,并将同一组中的6元组整理成如下形式:<longest-common-suffix_of_prefix_strings,author,middle,book,longest-common-prefix_of_suffix_strings>.从上述6元组抽取出来<Sir,Conan Doyle,wrote,The Adventures of Sherlock Holmes,in 1892>.其中,Sir是wrote这个 middle 对应的模板中 prefix的最长公共后缀子串,in 1892是wrote这个middle 对应的模板中suffix的最长公共前缀子串。
- 接下来,对上一步得到的模板进行泛化,将author和book 替换成非终结符*,得到泛化模板<Sir,,wrote,,in 1892>.重复上述三步不断抽取新模板和新实体对,例如《Conan Doyle,The Speckled Band》。新的实体对可以用于扩展当前关系对应的知识库,新的关系模板可以用于进行关于当前关系的分类任务。
Agichtein和 Gravano提出 Snowball 方法[13]用于识别(organization,location)关系。和DIPRE方法类似,Snowball 方法抽取5元组<prefix,organization,middle,location,suffix>(DIPRE 中包括的 order 信息被 Snowball忽略);和 DIPRE 不同,Snowball 并不采用字符匹配的方进行元组分组,而是将 prefix、middle 和 suffix转化为向量后采用向量距离的方式进行分组。例如,对于《CMU,Pittsbugh》这个
实体对,抽取出来一个5元组是<go to,CMU,campus in,Pittsbugh,to meet>(prefix,middle 和 suffix 设置长度为2的约束条件)。对prefix、middle和 suffix每一个单词打分:

基于上述打分机制,进一步为两个元组之间的相似度打分: M a t c h ( p a t t e r n 1 , p a t t e r n 2 ) = V p r e f i x 1 ⋅ V p r e f i x 2 + V m i d d l e 1 ⋅ V m i d d l e 2 + V s u f f i x 1 ⋅ V s u f f i x 2 Match(pattern_1,pattern_2)=V_{prefix1}\cdot V_{prefix2}+V_{middle1}\cdot V_{middle2}+V_{suffix1}\cdot V_{suffix2} Match(pattern1,pattern2)=Vprefix1⋅Vprefix2+Vmiddle1⋅Vmiddle2+Vsuffix1⋅Vsuffix2,并按照上述得分对不同5元组进行聚类分组。
对于每个 pattern,Snowball采用如下方式进行置信度的计算:

P p o s i t i v e P_{positive} Ppositive表示新模板能够抽取先前已经被抽取并满足该关系的实体对的数目, P n e g t i v e P_{negtive} Pnegtive表示新抽取模板抽取出来的与之前抽取结果发生冲突的实体对数目。
和DIPRE相比,Snowball 通过定义打分函数的方式,对抽取获得的 pattern 进行置信度计算,这样可以在一定程度上保证抽取结果的质量。
4.2 基于远监督的方法
基于远监督(distant supervision)的方法按照如下步骤完成关系分类任务:①针对待分类关系集合中的每个关系r,获取满足该关系的实体对集合;②从文本集合中找到并保留同时包含某个实体对的句子;③从全部保留下来的句子集合中抽取特征,并与关系r建立对应关系。这样,如果保留下来的句子数目是|S|,从每个句子中抽取的特征数目是|F|,那么总共抽取的特征数就是|S|x |F|;④将抽取出来的《特征,关系》数据作为标注数据,用于训练多分类器完成关系分类任务。远监督关系分类方法基于的主要假设是:如果一个实体对满足某个给定关系,那么任何同时包含该实体对的句子都可能在阐述该关系。这样就可以基于满足某个关系的实体对从上述句子中抽取大量特征,用于关系分类任务。当然,通过上述方式构造的标注数据必然存在一定量的噪音,通过训练调整不同特征对应的权重,可以使噪音特征的权重变小、有效特征的权重变大。
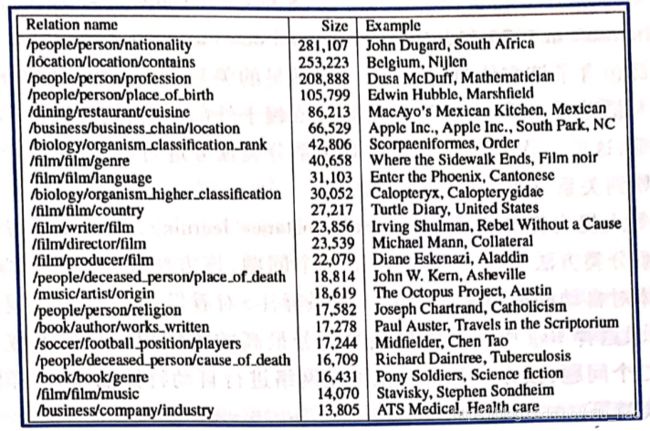
Mintz等人针对 Freebase 中选取的102个关系,提出基于远监督的关系分类方法[14]。该方法基于上述102个关系对应的 1800000个三元组,从维基百科中为每个关系抽取特征集合,用于多分类器的训练。下图给出Freebase 中排名最高的关系列表和对应实体对。
该方法使用的特征包括词汇化特征和语法特征两类。词汇化特征从两个实体对应的上下文中抽取五类信息,并将它们连接在一起构成一个独立特征:①两个实体之间的单词序列;②两个实体之间单词对应的词性序列;③指示特征,用来明哪个实体( e 1 e_1 e1表示首先出现的实体, e 2 e_2 e2表示后出现的实体)在句子中首先出现;④ e 1 e_1 e1左端的 k ∈ { 0 , 1 , 2 } k\in \{0,1,2\} k∈{0,1,2}个词及对应的词性:⑤ e 2 e_2 e2右端的 k ∈ { 0 , 1 , 2 } k\in \{0,1,2\} k∈{0,1,2}个词及对应的词性;语法特征从句子对应的依存句法树中抽取两类信息,并将它们连接在一起构成一个独立特征:①两个实体在依存句法树上的路径;② 每个实体对应的窗口节点(window node).窗口节点表示并不在两个实体之间的路径上、但与某个实体直接相连的节点。
下图给出 Astronomer Edwin Hubble was born in Marshfield,Missouri 对应的依存句法树以及从中抽取出来的特征。

除上述特征外,实体类型信息(person、location,organization 等)也可以作为特征。
上述介绍的远监督关系分类工作存在两个主要问题:第一,两个实体之间满足的关系可能有多个。例如,对于实体对
Zeng等人提出将多实例学习(multi-instance learning)和深度学习相结合的远监督关系分类方法[15].针对上述第一个问题,该方法使用多实例学习,将基于每个实体对自动抽取出来的<句子,关系标注>对看做一个Bag,在模型参数训练过程中,只选择 Bag 中使得模型预测得分最高的实例用于模型参数更新,针对上述第二个问题,该方法基于卷积神经网络进行自动特征抽取,这样做无须人工设计分类特征。
5. 总结
识别自然语言中出现的实体以及实体之间的关系,是自然语言理解的基础,也是智能问答最重要的组成部分。传统方法使用模板或特征完成关系分类任务。这类方法的优点是可以根据语言学和领域知识自主设计模板或特征。然而,并非所有对该任务有效的特征都是可解释的和具体的,因此这类特征无法通过端到端的训练自动总结出有效的特征子集。与之对比,基于深度学习的方法能够通过端到端的方式从训练数据中自动学习对该任务有效的特征表示,但由于表示学习获得的特征向量无法解释(黑盒子),因此该类方法很难进行问题追踪。如何将人工特征和表示学习特征相结合,是自然语言处理领域一个重要的研究方向。
6. 参考文献
[1]Marti A.Hearst.Automatic Acquisition of Hvponyms from Large Text Corpora[C].COLING,1992.
[2]Deepak Ravichandran,Eduard Hovy.Learning Surface Text Patterns for a Question Answering System[C].ACL,2002.
[31 Nanda Kambhatla.Combining Lexical,Svntactic and Semantic Features with Maximum Entropy Models for Extracting Relations[C].ACL,2004.
[4]GuoDong Zhou,Jian Su,Jie Zhang,etc.Exploring Various Knowledge in Relation Extraction[C].ACL,2005.
[5] Huma Lodhi,John Shawe-Taylor,Nello Cristianini,etc.Text Classification using String Kernels[J].Journal of Machine Learning Re-
search,2002,2(3):419-444.
[6]Razvan C.Bunescu,Raymond J.Mooney.Subsequence Kernels for Relation Extraction[C].NIPS,2005.
[7] Dmitry Zelenko,Chinatsu Aone,Anthony Richardella.Kernel Methods for Relation Extraction[J].Journal of Machine Learning Research,2003,3(3):1083-1106.
[8]Razvan C.Bunescu,Raymond J.Mooney.A Shortest Path Dependency Kernel for Relation Extraction[C].EMNLP,2005.
[9]Richard Socher,Brody Huval,Christopher D.Manning,etc.Semantic Compositionality through Recursive Matrix-Vector Spaces[C].
EMNLP,2012.
[10]Daojian Zeng,Kang Liu,Siwei Lai,etc.Relation Classification via Convolutional Deep Neural Network[C].COLING,2014.
[11]Makoto Miwa,Mohit Bansa.End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures[C].ACL,2016.
[12]Sergey Brin.Extracting Patterns and Relations from the World Wide Web[M].Berlin:springer,1999.
[13]Eugene Agichtein,Luis Gravano.Snowball:Extracting Relations from Large Plain-Text Collections[C].Acm Conference on Digital
Libraries,2000.
[14]Mike Mintz,Steven Bills,Rion Snow,etc.Distant supervision for relation extraction without labeled data.ACL,2009.
[15] Daojian Zeng,Kang Liu,Yubo Chen,etc.Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks[C].
EMNLP,2015.