PyTorch搭建AlexNet模型(在CIFAR10数据集上准确率达到了85%)
PyTorch搭建AlexNet模型
CIFAR10数据集
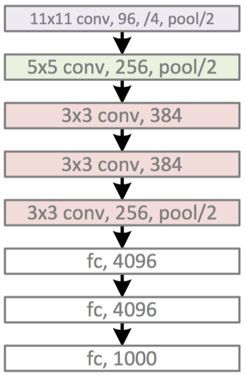
# import packages
import torch
import torchvision
# Device configuration.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
num_epochs = 40
num_classes = 10
batch_size = 100
learning_rate = 0.0006
数据增强:https://blog.csdn.net/weixin_40793406/article/details/84867143
# Transform configuration and Data Augmentation.
transform_train = torchvision.transforms.Compose([torchvision.transforms.Pad(2),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomCrop(32),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
transform_test = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
# Load downloaded dataset.(download=False)
train_dataset = torchvision.datasets.CIFAR10('data/CIFAR/', train=True, download=False, transform=transform_train)
test_dataset = torchvision.datasets.CIFAR10('data/CIFAR/', train=False, download=False, transform=transform_test)
# Data Loader.
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
(6 - 2 + 2 * 0) / 2 + 1
3.0
# AlexNet
class AlexNet(torch.nn.Module):
def __init__(self, num_classes, init_weights=False):
super(AlexNet, self).__init__()
self.layer1 = torch.nn.Sequential(torch.nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=2),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=0))
self.layer2 = torch.nn.Sequential(torch.nn.Conv2d(64, 192, kernel_size=4, stride=1, padding=1),
torch.nn.BatchNorm2d(192),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool2d(kernel_size=2, stride=1, padding=0))
self.layer3 = torch.nn.Sequential(torch.nn.Conv2d(192, 384, kernel_size=3, padding=1),
torch.nn.BatchNorm2d(384),
torch.nn.ReLU(inplace=True))
self.layer4 = torch.nn.Sequential(torch.nn.Conv2d(384, 256, kernel_size=3, padding=1),
torch.nn.BatchNorm2d(256),
torch.nn.ReLU(inplace=True))
self.layer5 = torch.nn.Sequential(torch.nn.Conv2d(256, 256, kernel_size=3, padding=1),
torch.nn.BatchNorm2d(256),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool2d(kernel_size=2, stride=2))
self.avgpool = torch.nn.Sequential(torch.nn.AdaptiveAvgPool2d(output_size=(3, 3)))
self.fc1 = torch.nn.Sequential(torch.nn.Dropout(p=0.5, inplace=False),
torch.nn.Linear(256 * 3 * 3, 1024),
torch.nn.ReLU(inplace=True))
self.fc2 = torch.nn.Sequential(torch.nn.Dropout(p=0.5, inplace=False),
torch.nn.Linear(1024, 1024),
torch.nn.ReLU(inplace=True))
self.fc3 = torch.nn.Sequential(torch.nn.Dropout(p=0.5, inplace=False),
torch.nn.Linear(1024, num_classes))
if init_weights:
self._initialize_weights()
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.layer5(out)
out = self.avgpool(out)
out = out.reshape(out.size(0), -1)
out = self.fc1(out)
out = self.fc2(out)
out = self.fc3(out)
return out
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
torch.nn.init.constant_(m.bias, 0)
elif isinstance(m, torch.nn.Linear):
torch.nn.init.normal_(m.weight, 0, 0.01)
torch.nn.init.constant_(m.bias, 0)
# Make model
model = AlexNet(num_classes, True).to(device)
# Loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# For updating learning rate.
def update_lr(optimizer, lr):
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# Train the model
import gc
total_step = len(train_loader)
curr_lr = learning_rate
for epoch in range(num_epochs):
gc.collect()
torch.cuda.empty_cache()
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optim
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
# Decay learning rate
if (epoch+1) % 20 == 0:
curr_lr /= 3
update_lr(optimizer, curr_lr)
Epoch [1/40], Step [100/500], Loss 1.6492
Epoch [1/40], Step [200/500], Loss 1.2890
Epoch [1/40], Step [300/500], Loss 1.2790
Epoch [1/40], Step [400/500], Loss 1.2066
Epoch [1/40], Step [500/500], Loss 1.3352
Epoch [2/40], Step [100/500], Loss 1.1206
Epoch [2/40], Step [200/500], Loss 1.1530
Epoch [2/40], Step [300/500], Loss 1.1221
Epoch [2/40], Step [400/500], Loss 1.1890
Epoch [2/40], Step [500/500], Loss 1.4721
Epoch [3/40], Step [100/500], Loss 1.3654
Epoch [3/40], Step [200/500], Loss 1.0169
Epoch [3/40], Step [300/500], Loss 1.0006
Epoch [3/40], Step [400/500], Loss 0.8630
Epoch [3/40], Step [500/500], Loss 1.1683
Epoch [4/40], Step [100/500], Loss 1.1562
Epoch [4/40], Step [200/500], Loss 0.9112
Epoch [4/40], Step [300/500], Loss 0.9316
Epoch [4/40], Step [400/500], Loss 0.6593
Epoch [4/40], Step [500/500], Loss 0.9656
Epoch [5/40], Step [100/500], Loss 0.7993
Epoch [5/40], Step [200/500], Loss 0.6588
Epoch [5/40], Step [300/500], Loss 0.8497
Epoch [5/40], Step [400/500], Loss 0.7340
Epoch [5/40], Step [500/500], Loss 0.7308
Epoch [6/40], Step [100/500], Loss 0.7257
Epoch [6/40], Step [200/500], Loss 0.8516
Epoch [6/40], Step [300/500], Loss 0.7521
Epoch [6/40], Step [400/500], Loss 0.5266
Epoch [6/40], Step [500/500], Loss 0.5341
Epoch [7/40], Step [100/500], Loss 0.7219
Epoch [7/40], Step [200/500], Loss 0.5938
Epoch [7/40], Step [300/500], Loss 0.8091
Epoch [7/40], Step [400/500], Loss 0.8100
Epoch [7/40], Step [500/500], Loss 0.6911
Epoch [8/40], Step [100/500], Loss 0.6521
Epoch [8/40], Step [200/500], Loss 0.6885
Epoch [8/40], Step [300/500], Loss 0.7028
Epoch [8/40], Step [400/500], Loss 0.7161
Epoch [8/40], Step [500/500], Loss 0.5278
Epoch [9/40], Step [100/500], Loss 0.5614
Epoch [9/40], Step [200/500], Loss 0.4875
Epoch [9/40], Step [300/500], Loss 0.7000
Epoch [9/40], Step [400/500], Loss 0.7558
Epoch [9/40], Step [500/500], Loss 0.5971
Epoch [10/40], Step [100/500], Loss 0.6826
Epoch [10/40], Step [200/500], Loss 0.6056
Epoch [10/40], Step [300/500], Loss 0.6060
Epoch [10/40], Step [400/500], Loss 0.7533
Epoch [10/40], Step [500/500], Loss 0.6184
Epoch [11/40], Step [100/500], Loss 0.5959
Epoch [11/40], Step [200/500], Loss 0.4700
Epoch [11/40], Step [300/500], Loss 0.5198
Epoch [11/40], Step [400/500], Loss 0.6824
Epoch [11/40], Step [500/500], Loss 0.6164
Epoch [12/40], Step [100/500], Loss 0.6629
Epoch [12/40], Step [200/500], Loss 0.4856
Epoch [12/40], Step [300/500], Loss 0.6373
Epoch [12/40], Step [400/500], Loss 0.4171
Epoch [12/40], Step [500/500], Loss 0.4365
Epoch [13/40], Step [100/500], Loss 0.4338
Epoch [13/40], Step [200/500], Loss 0.5385
Epoch [13/40], Step [300/500], Loss 0.5434
Epoch [13/40], Step [400/500], Loss 0.5540
Epoch [13/40], Step [500/500], Loss 0.3327
Epoch [14/40], Step [100/500], Loss 0.6186
Epoch [14/40], Step [200/500], Loss 0.7179
Epoch [14/40], Step [300/500], Loss 0.5663
Epoch [14/40], Step [400/500], Loss 0.4083
Epoch [14/40], Step [500/500], Loss 0.6008
Epoch [15/40], Step [100/500], Loss 0.4308
Epoch [15/40], Step [200/500], Loss 0.7846
Epoch [15/40], Step [300/500], Loss 0.5956
Epoch [15/40], Step [400/500], Loss 0.5231
Epoch [15/40], Step [500/500], Loss 0.5921
Epoch [16/40], Step [100/500], Loss 0.5951
Epoch [16/40], Step [200/500], Loss 0.4274
Epoch [16/40], Step [300/500], Loss 0.3845
Epoch [16/40], Step [400/500], Loss 0.4589
Epoch [16/40], Step [500/500], Loss 0.3062
Epoch [17/40], Step [100/500], Loss 0.6167
Epoch [17/40], Step [200/500], Loss 0.4326
Epoch [17/40], Step [300/500], Loss 0.4225
Epoch [17/40], Step [400/500], Loss 0.4847
Epoch [17/40], Step [500/500], Loss 0.3630
Epoch [18/40], Step [100/500], Loss 0.4661
Epoch [18/40], Step [200/500], Loss 0.4640
Epoch [18/40], Step [300/500], Loss 0.5456
Epoch [18/40], Step [400/500], Loss 0.3794
Epoch [18/40], Step [500/500], Loss 0.7142
Epoch [19/40], Step [100/500], Loss 0.5485
Epoch [19/40], Step [200/500], Loss 0.5388
Epoch [19/40], Step [300/500], Loss 0.4643
Epoch [19/40], Step [400/500], Loss 0.6234
Epoch [19/40], Step [500/500], Loss 0.3233
Epoch [20/40], Step [100/500], Loss 0.2865
Epoch [20/40], Step [200/500], Loss 0.4046
Epoch [20/40], Step [300/500], Loss 0.3092
Epoch [20/40], Step [400/500], Loss 0.2404
Epoch [20/40], Step [500/500], Loss 0.3287
Epoch [21/40], Step [100/500], Loss 0.3556
Epoch [21/40], Step [200/500], Loss 0.3981
Epoch [21/40], Step [300/500], Loss 0.3607
Epoch [21/40], Step [400/500], Loss 0.3528
Epoch [21/40], Step [500/500], Loss 0.3283
Epoch [22/40], Step [100/500], Loss 0.4040
Epoch [22/40], Step [200/500], Loss 0.2196
Epoch [22/40], Step [300/500], Loss 0.3122
Epoch [22/40], Step [400/500], Loss 0.2579
Epoch [22/40], Step [500/500], Loss 0.2784
Epoch [23/40], Step [100/500], Loss 0.2697
Epoch [23/40], Step [200/500], Loss 0.1861
Epoch [23/40], Step [300/500], Loss 0.2593
Epoch [23/40], Step [400/500], Loss 0.4506
Epoch [23/40], Step [500/500], Loss 0.2797
Epoch [24/40], Step [100/500], Loss 0.3377
Epoch [24/40], Step [200/500], Loss 0.2880
Epoch [24/40], Step [300/500], Loss 0.2630
Epoch [24/40], Step [400/500], Loss 0.3789
Epoch [24/40], Step [500/500], Loss 0.4665
Epoch [25/40], Step [100/500], Loss 0.3154
Epoch [25/40], Step [200/500], Loss 0.3462
Epoch [25/40], Step [300/500], Loss 0.3531
Epoch [25/40], Step [400/500], Loss 0.3515
Epoch [25/40], Step [500/500], Loss 0.4523
Epoch [26/40], Step [100/500], Loss 0.2112
Epoch [26/40], Step [200/500], Loss 0.2063
Epoch [26/40], Step [300/500], Loss 0.1692
Epoch [26/40], Step [400/500], Loss 0.1394
Epoch [26/40], Step [500/500], Loss 0.2829
Epoch [27/40], Step [100/500], Loss 0.2067
Epoch [27/40], Step [200/500], Loss 0.2599
Epoch [27/40], Step [300/500], Loss 0.1731
Epoch [27/40], Step [400/500], Loss 0.3413
Epoch [27/40], Step [500/500], Loss 0.1994
Epoch [28/40], Step [100/500], Loss 0.1494
Epoch [28/40], Step [200/500], Loss 0.1616
Epoch [28/40], Step [300/500], Loss 0.3061
Epoch [28/40], Step [400/500], Loss 0.2259
Epoch [28/40], Step [500/500], Loss 0.2186
Epoch [29/40], Step [100/500], Loss 0.2551
Epoch [29/40], Step [200/500], Loss 0.0851
Epoch [29/40], Step [300/500], Loss 0.3189
Epoch [29/40], Step [400/500], Loss 0.2318
Epoch [29/40], Step [500/500], Loss 0.2580
Epoch [30/40], Step [100/500], Loss 0.2642
Epoch [30/40], Step [200/500], Loss 0.1859
Epoch [30/40], Step [300/500], Loss 0.1255
Epoch [30/40], Step [400/500], Loss 0.2070
Epoch [30/40], Step [500/500], Loss 0.2719
Epoch [31/40], Step [100/500], Loss 0.3262
Epoch [31/40], Step [200/500], Loss 0.4126
Epoch [31/40], Step [300/500], Loss 0.2124
Epoch [31/40], Step [400/500], Loss 0.2548
Epoch [31/40], Step [500/500], Loss 0.2888
Epoch [32/40], Step [100/500], Loss 0.1411
Epoch [32/40], Step [200/500], Loss 0.1726
Epoch [32/40], Step [300/500], Loss 0.1584
Epoch [32/40], Step [400/500], Loss 0.1655
Epoch [32/40], Step [500/500], Loss 0.2147
Epoch [33/40], Step [100/500], Loss 0.0923
Epoch [33/40], Step [200/500], Loss 0.1368
Epoch [33/40], Step [300/500], Loss 0.2215
Epoch [33/40], Step [400/500], Loss 0.1883
Epoch [33/40], Step [500/500], Loss 0.1961
Epoch [34/40], Step [100/500], Loss 0.1833
Epoch [34/40], Step [200/500], Loss 0.2087
Epoch [34/40], Step [300/500], Loss 0.2253
Epoch [34/40], Step [400/500], Loss 0.1642
Epoch [34/40], Step [500/500], Loss 0.1339
Epoch [35/40], Step [100/500], Loss 0.1655
Epoch [35/40], Step [200/500], Loss 0.2250
Epoch [35/40], Step [300/500], Loss 0.1227
Epoch [35/40], Step [400/500], Loss 0.1273
Epoch [35/40], Step [500/500], Loss 0.2895
Epoch [36/40], Step [100/500], Loss 0.1342
Epoch [36/40], Step [200/500], Loss 0.0948
Epoch [36/40], Step [300/500], Loss 0.2571
Epoch [36/40], Step [400/500], Loss 0.1380
Epoch [36/40], Step [500/500], Loss 0.1755
Epoch [37/40], Step [100/500], Loss 0.1639
Epoch [37/40], Step [200/500], Loss 0.0683
Epoch [37/40], Step [300/500], Loss 0.2666
Epoch [37/40], Step [400/500], Loss 0.1279
Epoch [37/40], Step [500/500], Loss 0.1310
Epoch [38/40], Step [100/500], Loss 0.1961
Epoch [38/40], Step [200/500], Loss 0.1322
Epoch [38/40], Step [300/500], Loss 0.1165
Epoch [38/40], Step [400/500], Loss 0.1407
Epoch [38/40], Step [500/500], Loss 0.1610
Epoch [39/40], Step [100/500], Loss 0.0916
Epoch [39/40], Step [200/500], Loss 0.1604
Epoch [39/40], Step [300/500], Loss 0.2086
Epoch [39/40], Step [400/500], Loss 0.2270
Epoch [39/40], Step [500/500], Loss 0.1303
Epoch [40/40], Step [100/500], Loss 0.1133
Epoch [40/40], Step [200/500], Loss 0.1402
Epoch [40/40], Step [300/500], Loss 0.3124
Epoch [40/40], Step [400/500], Loss 0.2342
Epoch [40/40], Step [500/500], Loss 0.1773
# Test the model.
model.eval()
with torch.no_grad():
total = 0
correct = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print ('Test Accuracy of the model on the test images: {} %'.format(100 * correct / total))
Test Accuracy of the model on the test images: 85.74 %
# Save the model.
torch.save(model.state_dict(), 'AlexNet(CIFAR10).ckpt')