2022年几款前沿的文本语义检索/Sentence Embedding方法:Gradient Cache, SGPT,ART,DPTDR,RocketQAv2, ERNIE-Search等
最近研究了一些最新的关于搜索方向的论文,发现了几篇有代表性的论文,我这里分享出来,跟大家一起学习共同进步。目前的搜索架构都是召回和排序,召回采用的是BM25,dual-encoder, bi-encoder,(其实dual-encoder和bi-encoder是一个意思,他们的作用就是把query和passage变成向量的形式,这样就能够计算相似度,计算距离什么的了),有一些论文也叫dense passage retriever/retreiver,排序模型通常采用的是cross encoder(其实就是一个二分类模型,就是把query和passage拼接起来输入到模型里面,然后得到一个得分),论文里面叫做ranker或者reranker。基于向量的搜索架构架构图如下,可以看到Dual Encoder用在了召回环节的抽向量的部分,Cross Encoder用在了排序环节的重排序部分:

语义搜索架构
如果想快速体验搜索的技术,或者Sentence Embedding的应用,推荐PaddleNLP的开源实现Pipelines,内置了RocketQA系列的模型,能够在不用训练的情况下搭建一个检索系统,还包括了后台和前端。
另外如果想自己训练一个基于预训练语言模型的搜索的召回和排序模型,请参考Neural Search的实现,里面包含了RocketQA,In-Batch Negative, SimCSE等方法:
1.DPTDR 基于Prompt的检索方法
基于Prompt的检索方法还是很少见的,这里发现了一篇还不错的文章,论文提出了一个任务和模型无关的策略,叫做面向检索的预训练(retrieval-oriented intermediate pretraining)和统一负采样(unified negative mining)。具体是怎么做的呢?如下图
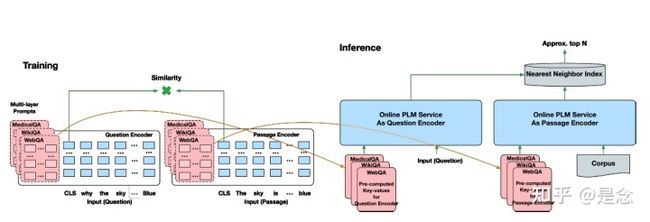
DPTDR框架
首先在基于PLM的dual encoder加入多层prompts,PLM的每一层都需要加pompts层,每层的prompts用一个前缀矩阵M来初始化,看上去是遵循了一般的初始化方式。另外对于这个RIP,它的目标是用对比学习要么预训练一个prompts要么是一个PLM。在训练的时候,比如有N篇文章,对于某一篇文章,把该文章分成k个句子,然后让模型区分这个句子是属于该文章还是其他的文章。知道了这个原理,对比学习的公式就出来:

然后预训练使用的是coCondenser的方式(本文作者移除了coCondenser修改模型结构的部分,取得了不错的效果,原论文是这样说的,就是为了使得任意的PLM模型使用他们自己的预训练权重啥的,然后都能使用DPT训练,所以就coCondenser修改模型的部分给去除了),做PLM的预训练,使用的是MLM的方式,其损失函数是:
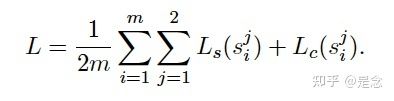
公式可以看出就是对比学习损失和MLM损失的结合版本。
UNM的原理比较好理解,第一步就是用BM25检索出来的样本当成负样本,训练完以后得到基于DPT的retreiever,然后用这个训练好的模型构造去噪的强负样本。最后使用这两种结合的方式做in-batch或者cross-batch训练,看上去是通过各种路子构造负样本,然后训练的时候一把梭。
除了这篇是把prompt应用到搜索领域的论文外,还有PromptBERT,请听后面详细的讲解。
代码地址:https://github.com/tangzhy/DPTDR
论文地址:https://arxiv.org/abs/2208.11503
2.Gradient Cache:超大batch size的对比学习训练
这篇文章提出了一个在有限的gpu显存的情况下,怎么增大batch_size的方法,in-batch negatives这种训练方式受到batch size影响很大,直接关系到每次训练样本的负样本的多少。它的思路就是把反向传播从对比学习损失和编码器之间分开,移除batch维度上编码器反向传播的数据以来。具体是怎么做的呢?第一步是得到S和T的向量表示(文中用的是S和T,S用f编码,T用g编码,S和T相近的话,我们让f和g距离相近,相反则越远),然后存起来;第二步是对梯度进行缓存,但是把Encoder除外。第三部是sub 批次的梯度累积,首先是让小batch经过编码器得到输出表示,然后把缓存的Gradient取出来然后累积在一起做反向传播,公式就拆成了两部分,梯度是从缓存里面得来的,输出

f函数的梯度计算

g函数的梯度计算
第四步就是进行优化,当所有的sub批次都按照第三步处理完以后,更新整个模型的参数,就相当于模型在一个非常大的batch上进行前向和反向计算了。
通过这样缓存中间过程计算的梯度的做法就节省了很多内存了。
代码地址:https://github.com/luyug/GradCache
论文地址:https://arxiv.org/abs/2101.06983
3.ART:一个只需要学习问句构造的检索模型
这篇论文借鉴了AutoEncoder的思想,第一步就是通过问题来检索一些evidence文档(从wiki百科里面得来的),第二步就是利用这些evidence文档来计算重构原始问题的概率。怎么做的呢?请看下面的那张图

首先是第一步对于问题Question Q,通过retriever encoder抽取向量,然后通过向量来检索documents(这些documents是通过一个初始化的retriever来得到的,然后就跟query embedding计算相似度就找到了topk的文档了),第二步,retriever的似然计算这是为了对检索出来的文档做规范化,本质上就是一个softmax的计算公式,把这个当成student distribution。
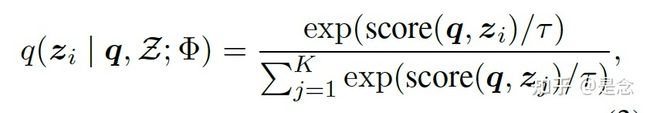
第三步是相关得分估计,使用一个large PLM来估计question(question通过PLM构造,因为要计算得分,论文里面的cross Attention Scorer,用了贝叶斯定理和teacher forcing方法近似)和文档的得分,当成teacher distribution。


第四步用KL散度来估计teacher和student的分布。第五步来优化question的编码器和document的编码器。由于编码器对question进行了编码,然后PLM(论文用了T5-XL,有Decoder)在计算相关度的分的时候通过文档又对问题进行了重新估计,因此可以看成是在训练一个Atutoencoder。
论文地址:https://arxiv.org/abs/2206.10658
代码地址:https://github.com/DevSinghSachan/art
4.SGPT:一个把GPT大模型用于搜索的架构
把GPT应用到搜索方向上,还是挺少见的,这篇论文论文我读了一下,还挺不错的,GPT的搜索该怎么做呢?我们来看下面的一张图,这张图为我们展示了基于GPT的Bi-Encoder(SGPT-BE)和Cross Encoder(SGPT-CE)的结构。
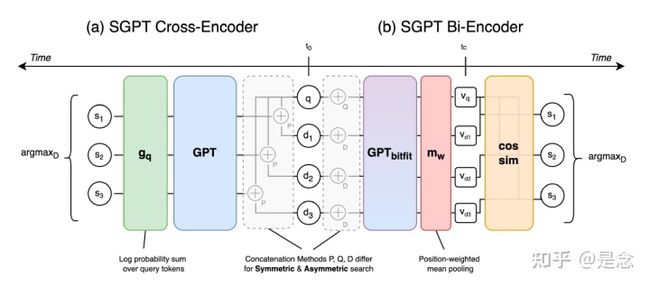
对于SGPT-CE结构,由于GPT是Transformer的Decoder结构,所以在用法上使用了prompts,即在query和document拼接输入模型的时候,加入prompts(具体加的prompts,可以参考github的源代码),然后输出结果对每个token的概率求和并求log对数,注意SGPT-CE模型是直接使用,没有进行微调,这个还挺奇特的,这点对于很多人都很有益处。对于SGPT-BE模型,抽取向量的时候,由于输出的token又很多个,采用了带权的求和方法,从下面公式可以看出,gpt自回归预测出来越是靠后的token,权重越高,说明越靠后的句子包含的信息越多,由于GPT参数量很大,在训练的时候还是用了我们前面所说的Gradient Cache的技术,并且只微调GPT里面的偏置,其他参数则是固定住。

论文地址:https://arxiv.org/abs/2202.08904
代码地址:https://github.com/Muennighoff/sgpt
5.RocketQAv2:一个在中文领域精度超高的模型
今年我把RocketQA模型应用在了问答和搜索两个场景,发现效果惊人,相比于ERNIE 1.0,不用训练都有接近20个点的提升,所以特地推荐大家在中文场景下可以使用一下,不管是做分类,问答还是搜索。我这里介绍一下RocketQAV2模型,论文提出了一个同时训练Retrieval模型和Re-ranking模型的方法,同时做了混合数据增强,怎么做的呢?我们看一下下面的这张图:
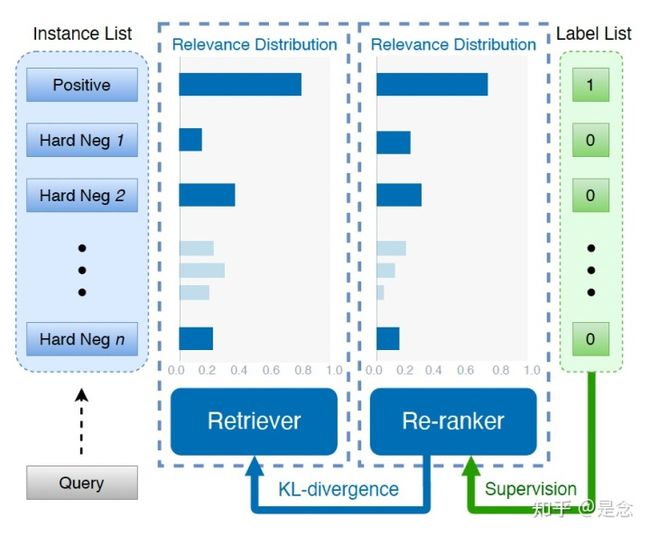
dynamic listwise distillation
对于给定的query(用q表示)和一系列的候选的相关文档p,Retriever然后进行listwise(就是q和p进行相似度计算)的规范化(类似于softmax的规范化),规范化后来获得query与这些文档p的相关度得分。Re-ranker也会得到query与候选文章的得分,然后两个得分来计算KL散度(知识蒸馏的常用做法),让Retriever和Re-ranker的输出分布变得相近,出了Re-rankder用了KL散度外,还用了label信息,因此求了一个交叉熵的损失。总结起来就是下面三个公式,都是一些基础公式的变形。



混合数据增强的方法其实就是使用了RocketQA来从数据集中抽取top-n的文章,对于未去噪的样本,其实就是从检索出来的样本中随机采样得来的。对于去噪的样本,就是使用RocketQA来打分,把置信度比较低的负样本去除,这样来构造的,同时也会保留得分比较高的样本当成正样本。
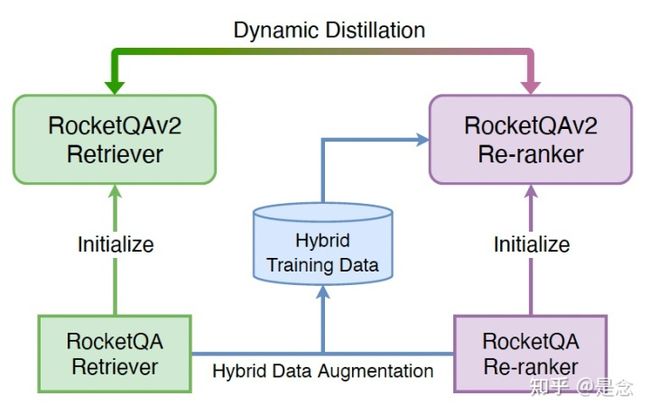
代码地址为:https://github.com/PaddlePaddle/RocketQA/tree/main/research/RocketQAv2_EMNLP2021
论文地址为:https://arxiv.org/abs/2110.07367
6.ERNIE-Search:一个在搜索领域中新的知识蒸馏的方法
这篇论文我看了好几遍,开始看的时候有点晕,主要集中在那几个蒸馏方式上,anyway,我来讲解一下这篇论文到底干了些啥?论文提出了2个蒸馏方式,第一个是交互式蒸馏(interaction distillation)和第二个是级联蒸馏(Cascade Distillation),怎么做的呢?我们看下面的图,
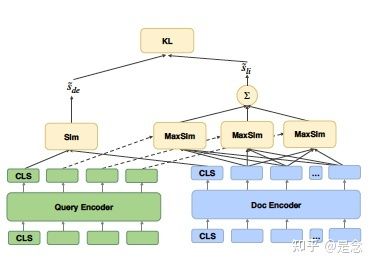
首先是Query Encoder和Doc Encoder的CLS位输出计算得到相关度得分 SdeS_{de} ,然后使用ColBERT的方式计算Query Encoder和Doc Encoder的得分 SliS_{li} , SdeS_{de} 在论文里面叫做指标交互(metric interaction),其实就是计算一个点积, SliS_{li} 论文里面叫做延迟交互(late interaction),然后使用KL散度来做这两个分布的交互式蒸馏。出了蒸馏的损失,模型还使用query和passage的正负pair对来训练搜索模型,因此,loss损失就有3个了,把上面的流程用公式表示如下:

metric interaction和late interaction

KL散度,用来做蒸馏

使用query和passage对训练
把上面的3个损失拼接在一起就可以得到下面的总的损失了:
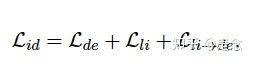
可以看到就是既做搜索的训练又做蒸馏的训练,所以损失就变成了3个的总和。另一个蒸馏策略是级联蒸馏,级联蒸馏的策略可以看如下的图:

级联蒸馏做了什么呢?其实就是把cross encoder的知识蒸馏给dual encoder,因为cross encoder模型比较复杂,其token级别的交互信息比dual encoder更多,怎么做呢?第一步是把cross的交互传给延迟交互,就是把cross encoder的信息传递给ColBERT,公式表示就如下所示:


论文说token级别的交互对延迟交互模型很重要,所以又加了一个loss,来蒸馏出token级别的注意力,看来什么东西都能给蒸馏出来,注意 AceA_{ce} 表示的是cross encoder最后一层的注意力图(attention map), Ali,iA_{li,i} 表示的是ColBERT的延迟交互,i表示的是transformer(BERT及BERT的变体是有Transformer的层来堆起来的,Transformer的实现其实就是多头注意力)的第i个head,:
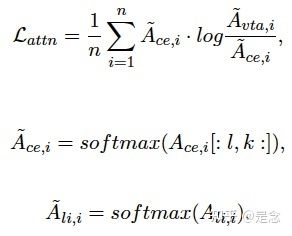
第二步是把延迟交互传传递给指标交互(metric interaction),其实就是把ColBERT的信息/知识传递给dual-encoder.然后就结束了。这么多蒸馏,该怎么训练呢?论文最后把这些loss全部加起来,也就是整个蒸馏(级联蒸馏+交互蒸馏)过程进行联合训练:
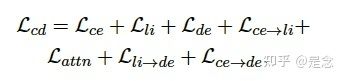
另外,论文还提出了一个dual Regularization,其实就是用dropout,对passage encoder做两次前向,然后用KL散度求loss,让两次输出的distribution相近,这个论文也没有细讲,我就不展开了,估计是实现太简单了,码不出多少字。
总结
上面的一些工作都是最近调研的比较有代表性的工作,其中包含了百度的一些工作,因为百度在搜索领域有着得天独厚的优势,我也使用了一些RocketQA等系列的模型,在学术和工业落地场景上都有着不错的效果,除了这些工作外还有SimLM,ColBERTv2等工作。更多关于语义检索方向的内容讲解,请参考本栏目后续的文章,如果有不懂的内容,请留言,我随即为大家安排上哈。