个性化推荐算法系统(1):基于邻域的个性化召回算法LFM(MovieLens数据集电影推荐)
目录
一、LFM理论
二、LFM实战
2.1 数据处理:read.py
1、得到电影信息
2、得到每部电影平均得分
3、准备LFM数据
2.2 LFM主体函数编写:LFM.py
1、初始化向量
2、计算模型预测出用户向量和电影向量之前的距离,欧氏距离
3、得到lfm模型的用户向量和电影向量
4、使用lfm得到的推荐结果,和得分
5、启动函数
6、分析推荐结果的好坏(只是打印出来)
7、go
代码、数据集下载:https://download.csdn.net/download/qq_35883464/11225488
LFM(latent factor model)隐语义模型核心思想是通过隐含特征联系用户兴趣和物品。
相比USerCF算法(基于类似用户进行推荐)和ItemCF(基于类似物品进行推荐)算法;
我们还可以直接对物品和用户的兴趣分类。对应某个用户先得到他的兴趣分类,确定他喜欢哪一类的物品,再在这个类里挑选他可能喜欢的物品。
对于LFM(latent factor model)的数学原理网络上很多博客都有提及,这里不再细讲,只是和代码一起讲解
一、LFM理论
建模公式:

公式解释:如果user(用户)点击了item(物品)![]() 则为1,反之则为0.模型的最终输出为user的向量(pu)、item向量(qi) 相乘是一个数字,通过梯度下降迭代。
则为1,反之则为0.模型的最终输出为user的向量(pu)、item向量(qi) 相乘是一个数字,通过梯度下降迭代。
loss function:

上面的公式中前面项是真实值,后面一项为预测值
loss function加入正则项:
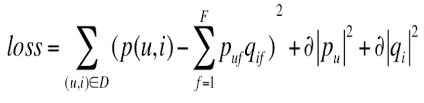
就可以,求得:
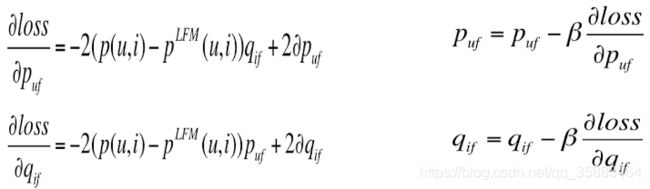
具体用代码讲解
二、LFM实战
电影推荐实战
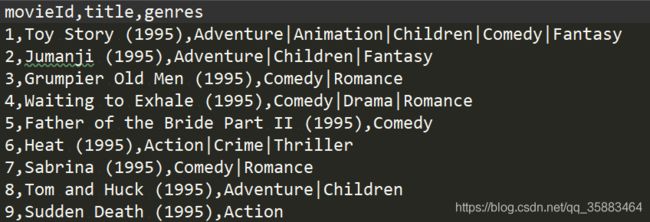
先看看数据集movies:(电影ID、电影名、类型)
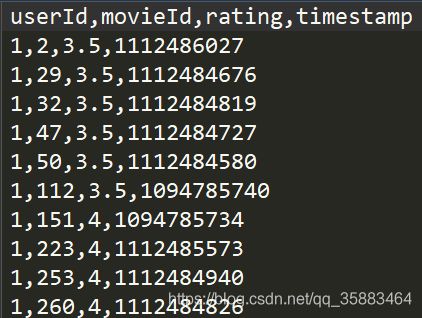
数据集movies:(用户ID、用户打分的电影ID、分数、时间戳)
2.1 数据处理:read.py
-
1、得到电影信息
def get_item_info(input_file):
'''
get item info :[title, gemre]
:param item
:return: a dict: key item_id, value:[title, genre]
'''
if not os.path.exists(input_file):
return {}
linenum = 0
item_info = {}
fp = open(input_file, encoding='UTF-8')
for line in fp:
if linenum == 0: # 第一行数据不需要
linenum += 1
continue
item = line.strip().split(',')
if len(item) < 3:
continue
elif len(item) == 3:
itemid, title, genre = item[0], item[1], item[2]
elif len(item) > 3:
itemid = item[0]
genre = item[-1]
title = ','.join(item[1:-1])
item_info[itemid] = [title, genre]
fp.close()
return item_info
-
2、得到每部电影平均得分
def get_ave_score(input_file):
'''
get item ave roting score
:param input_file: user rating file
:return: dict,key:itemid,value:sve_score
'''
if not os.path.exists(input_file):
return {}
linenum = 0
record_dict = {}
score_dict = {}
tp = open(input_file, encoding='UTF-8')
for line in tp:
if linenum == 0:
linenum += 1
continue
item = line.strip().split(',')
if len(item) < 4:
continue
userid,itemid,rating = item[0],item[1],float(item[2])
if itemid not in record_dict:
record_dict[itemid] = [0,0]
record_dict[itemid][0] += 1
record_dict[itemid][1] += rating
tp.close()
for itemid in record_dict:
score_dict[itemid] = round(record_dict[itemid][1]/record_dict[itemid][0],3)
return score_dict
-
3、准备LFM数据
def get_train_data(input_file):
'''
get train data for LFM model train
:param input_file:user item rating file
:return:a list: [(userid,itemid,label),(userid1,itemid,label)]
'''
if not os.path.exists(input_file):
return {}
score_dict = get_ave_score(input_file)
neg_dic = {}
pos_dic = {}
train_data = []
linenum = 0
with open(input_file, encoding='UTF-8') as fp:
for line in fp:
if linenum == 0:
linenum += 1
continue
item = line.strip().split(',')
if len(item) < 4:
continue
userid,item,rating = item[0],item[1],float(item[2])
if userid not in pos_dic:
pos_dic[userid] = []
if userid not in neg_dic:
neg_dic[userid] = []
if rating >= 4.0:
pos_dic[userid].append((item, 1))
else:
score = score_dict.get(item, 0)
neg_dic[userid].append((item,score))
for userid in pos_dic:
data_num = min(len(pos_dic[userid]), len(neg_dic.get(userid,[])))
if data_num > 0:
train_data += [(userid,zuhe[0],zuhe[1]) for zuhe in pos_dic[userid]][:data_num]
else:
continue
sorted_neg_list = sorted(neg_dic[userid], key=lambda element : element[1], reverse=True)
train_data += [(userid,zuhe[0],0) for zuhe in sorted_neg_list]
return train_data
2.2 LFM主体函数编写:LFM.py
-
1、初始化向量
def init_model(vector_len):
'''
:param vector_len: the len of vector
:return: ndarray
'''
return np.random.randn(vector_len)
-
2、计算模型预测出用户向量和电影向量之前的距离,欧氏距离
def model_predict(user_vector, item_vector):
'''
:param user_vector: model produce user distance
:param item_vector: model produce item distance
:return: a num
'''
res = np.dot(user_vector,item_vector)/(np.linalg.norm(user_vector)*np.linalg.norm(item_vector))
return res
-
3、得到lfm模型的用户向量和电影向量
ef lfm_train(train_data,F,alpha,beta,step):
'''
得到lfm模型的用户向量和电影向量
train_data:train_data for lfm
F:user_vector len,item_vector len
alpha: regularization factor
beta:learning rate
step:iteration num
:return:
dic:key itemid,value:ndarray
dic:key userid,value:ndarray
'''
user_vec ={}
item_vec ={}
for step_index in range(step):
for data_instance in train_data:
userid,itemid,label = data_instance
if userid not in user_vec:
user_vec[userid] = init_model(F)
if itemid not in item_vec:
item_vec[userid] = init_model(F)
delta = label - model_predict(user_vec[userid], item_vec[itemid])
for index in range(F): # 在这里和公式不一样,是实际工程的应用,没有2倍
user_vec[userid][index] = user_vec[userid][index] - beta*(-delta*item_vec[itemid][index] + alpha*user_vec[userid][index])
item_vec[itemid][index] = item_vec[itemid][index] - beta*(-delta*user_vec[userid][index] + alpha*item_vec[itemid][index])
beta = beta*0.9
return user_vec, item_vec
-
4、使用lfm得到的推荐结果,和得分
def give_recom_result(user_vec, item_vec, userid):
'''
user lfm model result give fix userid recom result
:param user_vec: lfm model result
:param item_vec: lfm model result
:param userid: fix userid
:return:list : [(itemid,score), (itemid1,score1)]
'''
if userid not in user_vec:
return []
record = {}
recom_list = []
fix_num = 5
user_vecor = user_vec[userid]
for itemid in item_vec:
item_vector = item_vec[itemid]
res = np.dot(user_vecor,item_vector)/(np.linalg.norm((user_vecor)*np.linalg.norm(item_vector)))
record[itemid] = res # record={'itemid':'res'}
record_list = list(record.items()) # record.items()=[(itemid,res),(itemid,res)] 在此用list转换格式是Python3的不兼容问题
for zuhe in sorted(record.items(), key=lambda rec: record_list[1], reverse=True)[:fix_num]:
itemid = zuhe[0]
score = round(zuhe[1],3)
recom_list.append((itemid,score))
return recom_list
-
5、启动函数
def model_train_process():
'''
test lfm model train
:return:
'''
train_data = read.get_train_data('ratings.csv')
user_vec,item_vec = lfm_train(train_data,50,0.01,0.1,50)
recom_result = give_recom_result(user_vec, item_vec, '11')
ana_recom_result(train_data, '11', recom_result)
这里lfm的参数是随便设置的,大家可以cv来调参。最后2行是显示例子
-
6、分析推荐结果的好坏(只是打印出来)
def ana_recom_result(train_data,userid,recom_list):
'''
:param train_data: 之前用户对哪些电影打分高
:param userid: 分析的用户
:param recom_list:模型给出的推荐结果
'''
item_info = read.get_item_info('movies.csv')
for data_instance in train_data:
userid1,itemid,label = data_instance
if userid1 == userid and label == 1:
print(item_info[itemid])
print('返回结果:')
for zuhe in recom_list:
print(item_info[zuhe[0]])
-
7、go
if __name__ == '__main__':
model_train_process()