LFM算法详解和实战
文章目录
-
- 1、LFM算法概述:
- 2、举例看看:
- 3、LFM公式推导
- 4、实战:
-
- 4.1 准备训练数据集
- 4.2 模型训练:
1、LFM算法概述:
LFM是在用户和物品的共现矩阵上,引入隐向量,用隐向量表示用户和物品,进而增强了模型表征稀疏数据的能力!
LFM算法本质上还是属于矩阵分解算法:
其将 m × n 的共现矩阵(m个用户;n个物品) 分解为:
- m × k 的用户向量矩阵
- k × n 的物品向量矩阵
上述中:k 表示隐向量的长度;
- k 的大小决定了隐向量的表征能力:
- k 越小,隐向量越短,其包含的信息越少,模型的泛化能力越强;
- k 越大, 隐向量越长,其包含的信息越多,模型的泛化能力越弱;
- k 的取值,还是要考量计算复杂度(长度约长,复杂度越大)以及实际场景中模型的效果
2、举例看看:
下图是用户和物品的共现矩阵,以视频网站场景为例,其表示用户对某视频(物品)是否点击(点击为1,未点为0)的记录;

若将用户和物品表示为向量(随机初始化向量),向量长度 k 取 5;以用户1 和 物品1 为例,表示如下图:

将用户1的向量转置,并和物品1的向量做点积,就可以得到:用户1和物品1的喜爱程度。具体如下图所示:

继续以用户1和物品1为例,当上面两个向量的点积值(0.845)和共现矩阵中对应的值(1)无限接近时,用户1的向量和物品1的向量对自身的刻画就越准确,模型的效果就越好!
3、LFM公式推导
对上面例子进行抽象:
- Pu:表示用户向量
- qi:表示物品向量
- F:隐向量的长度,即认为有多少特征会影响user对item的喜爱程度
- pLFM(u, i):是user对item的喜爱程度,即user vector 和 item vector 的乘积;

LFM损失函数:
采用平方误差损失函数,当p(u,i) (实际label) 和 pLFM(u,i)(用户对物品的喜爱程度)越接近时,损失函数越小!具体如下式:
- p(u, i):是共现矩阵中的值,即训练样本中的label,点击为1,为点击为0;
- pLFM(u, i):是user对item的喜爱程度,即user vector 和 item vector 的乘积;
- D:是所有的样本

为了防止模型过拟合,对模型参数进行限制,加入正则化;那么新的损失函数如下:

梯度下降法:
采用梯度下降法,不断更新pu(user vector)和qi (item vector),使得损失函数越小,即预测值和实际值越接近!
根据损失函数对pu求偏导:λ是正则化系数
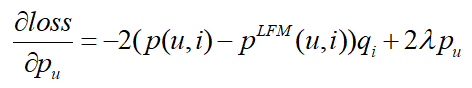
对qi求偏导:

那么 pu 和 qi 可以沿着梯度的负方向不断更新: γ是学习率


经过很多轮次的训练,用户和物品的vector会不断的更新,当效果不错时便可以停止!
4、实战:
以影评数据集MovieLens为数据,进行模型训练;数据集可以在网上下载;也可以使用这里下载好的数据集,在百度网盘中:
链接:https://pan.baidu.com/s/1HM0m0bnHSjrm45ZfST60oA
提取码:xt10
复制这段内容后打开百度网盘手机App,操作更方便哦
4.1 准备训练数据集
对于影评数据集,用户点击的物品(正样本)相对于未点击的物品(负样本)来说很少很少,因此需要对负样本采样,这里对所有的物品计算其平均得分,然后做排序(从大到小);对于某用户来说,正样本n个,那么就从排序后的物品集中,取前n个该用户未点击的物品!(即大多数人认为该物品不错,但是该用户没有点击,那么便认为该用户真的不喜欢该物品)
data_process.py
import pandas as pd
import os
import csv
def get_item_info(input_file):
"""
得到Item的信息
input_file: Item的文件地址
return:
dict: {itemID:[item_info]}
"""
item_info = {}
if not os.path.exists(input_file):
return {}
with open(input_file, "r", encoding='utf-8') as file:
lines = csv.reader(file)
i = 0
for line in lines: # 遍历每一条信息
if i == 0: # 跳过表头
i += 1
continue
else:
item_info[line[0]] = line[1:]
return item_info
def get_average_score(input_file):
"""
得到Item的平均得分
input_file: Item的打分文件 ratings.csv
return:
dict {ItemID:average_score}
"""
score_dict = {}
if not os.path.exists(input_file):
return {}
ratings_data = pd.read_csv(input_file)
ratings_mean_score = ratings_data[["movieId", "rating"]].groupby("movieId").agg("mean") # 对item分组求均值
movieID = ratings_mean_score.index.values.astype("str") # 将itemID 转化为str型
mean_score = ratings_mean_score["rating"].values.round(3) # 将均值保留三位小数
movieID_mean_score_zip = zip(movieID, mean_score)
for movieID, score in movieID_mean_score_zip:
score_dict[movieID] = score
return score_dict
def get_train_data(input_file):
"""
得到LFM的训练数据
input_file: user、item rating 文件
return:
list [(userID, itemID, label), (userID, itemID, label)]
"""
if not os.path.exists(input_file):
return []
score_dict = get_average_score(input_file) # item的平均得分
pos_dict, neg_dict = {}, {} # 正样本, 负样本
train_data = [] # 训练集
threshold = 4.0 # 阈值 (大于该值,为正样本;否则为负样本)
with open(input_file, "r", encoding='utf-8') as file:
lines = csv.reader(file)
i = 0
for line in lines:
if i == 0: # 跳过表头
i += 1
continue
userID, itemID, rating = line[0], line[1], float(line[2])
if userID not in pos_dict:
pos_dict[userID] = []
if userID not in neg_dict:
neg_dict[userID] = []
if rating > threshold: # rating 大于 4.0,正样本;添加到正样本中的
pos_dict[userID].append((itemID, 1))
else:
score = score_dict.get(itemID, 0) # 否则,获取该item 对应的平均得分;添加到负样本中
neg_dict[userID].append((itemID, score))
# 均衡正负样本
for userID in pos_dict:
data_num = min(len(pos_dict[userID]), len(neg_dict.get(userID, []))) # 对于某用户,取其正负样本最小的数量为最终正负样本的数量
if data_num > 0:
train_data += [(userID, pos_data[0], pos_data[1]) for pos_data in pos_dict[userID]][: data_num] # 正样本取data_num个
else:
continue
sorted_neg_list = sorted(neg_dict[userID], key=lambda x: x[1], reverse=True)[: data_num] # 根据评分对负样本排序,取前data_num个为负样本!
train_data += [(userID, neg_data[0], 0) for neg_data in sorted_neg_list]
return train_data
if __name__ == '__main__':
input_file = "../data/ratings.csv" # 评分表
train_data = get_train_data(input_file)
print(train_data[:10])
4.2 模型训练:
lfm.py
import numpy as np
import util.data_process as data_process # 导入数据处理脚本,注意位置
import operator
from tqdm import *
def init_vector(train_data, vector_len):
"""
初始化user和item的向量
train_data: 训练数据
vector_len: 向量的长度
return:
user vector and item vector
"""
init_user_vec = {}
init_item_vec = {}
for data_instance in train_data:
userID, itemID, _ = data_instance
init_user_vec[userID] = np.random.randn(vector_len)
init_item_vec[itemID] = np.random.randn(vector_len)
return init_user_vec, init_item_vec
def lfm_train(train_data, F, alpha, learning_rate, step):
"""
采用梯度下降,不断更新迭代 user_vector and item_vector
train_data: 训练数据集
F: 隐特征数
alpha: 正则化系数
learning_rate: 学习率
step: 迭代轮次
return:
dict {userID: [user_vector]}
dict {itemID: [user_vector]}
"""
user_vec, item_vec = init_vector(train_data, F) # 随机初始化user and item vector
for _ in tqdm(range(step), desc="训练进度: "): # 训练轮次
for data_instance in (train_data):
userID, itemID, label = data_instance
user_vector, item_vector = user_vec[userID], item_vec[itemID] # user vector, item vector
vector_dot = np.dot(user_vector, item_vector) / (np.linalg.norm(user_vector) * np.linalg.norm(item_vector)) # 向量点积(用户对物品的喜爱程度)
loss = label - vector_dot # loss
user_vector += np.multiply(learning_rate, (loss * item_vector - alpha * user_vector)) # user_vector 不断更新(根据梯度下降公式)
item_vector += np.multiply(learning_rate, (loss * user_vector - alpha * item_vector)) # item_vector 不断更新(根据梯度下降公式)
learning_rate = learning_rate * 0.95 # 学习率衰减
return user_vec, item_vec
def top_n_item(user_vec, item_vec, userid):
"""
计算某用户最喜爱的top_n个物品
user_vec: 用户向量
item_vec: 物品向量
userid: 用户ID
return:
a list: [(item, score), (item1, score1),,,]
"""
top_n = 10
if userid not in user_vec:
return []
item_score = {} # 存放用户对某物品的喜爱程度
top_list = [] # top_n喜欢的物品
user_vector = user_vec[userid] # 获取指定user对应的vector
for itemID in item_vec: # 遍历所有的item
item_vector = item_vec[itemID] # 拿到item对应的vector
vector_dot = np.dot(user_vector, item_vector) / (np.linalg.norm(user_vector) * np.linalg.norm(item_vector)) # 计算user和item1的相似度(喜爱程度)
item_score[itemID] = vector_dot # 将该用户对所有的物品喜爱程度写入字典中
# 以喜爱程度排序,取前top_n个用户最喜欢的item,返回
for item_i in sorted(item_score.items(), key=operator.itemgetter(1), reverse=True)[:top_n]:
itemID, score= item_i[0], round(item_i[1], 3)
top_list.append((itemID, score)) # 添加到最终的列表
return top_list
def print_top_result(train_data, userid, top_n):
"""
打印某用户以前看过的物品和算法推荐的物品
:param train_data: 用户之前喜欢的item
:param userid: 用户id
:param recom_list: 推荐的item
:return:
"""
item_info = data_process.get_item_info("F:/py_object/personal_recommend/LFM/data/movies.csv") # item的信息
print("----------------------------User clicked item----------------------------")
for data_instance in train_data: # 遍历数据集
userID_tem, itemID, label = data_instance
if userID_tem == userid and label == 1: # 若打印某user喜爱的物品(正样本)
print(f"[User clicked items] itemID : {itemID} ; item_info : {item_info[itemID]} ")
print("----------------------------Recommendation result of LFM algorithm----------------------------")
for item_i in top_n:
print(f"[Recommended items] itemID : {item_i[0]} ; item_info : {item_info[item_i[0]]} ; 喜爱程度: {item_i[1]}")
if __name__ == '__main__':
train_data = data_process.get_train_data("../data/ratings.csv")
user_vec, item_vec = lfm_train(train_data, 32, 0.01, 0.1, 1) # 训练
userID = '2' # 以用户ID‘2’为例,查看其推荐结果
top_result = top_n_item(user_vec, item_vec, userID)
print_top_result(train_data, userID, top_result)
上述中,再得到用户和物品的向量后,有多种推荐的形式:
- 计算用户的top_like: 对于没有给用户展示的item,计算该用户和未展示物品的相似度,进行推荐
- 计算物品的top_sim:对于用户点击过的物品,计算其和其他物品的相似度,进行推荐