TOOD: Task-aligned One-stage Object Detection(阅读笔记)
目标检测的两个子任务:
分类和定位
研究现状
最近的单阶段目标检测器试图通过关注目标的中心来预测两个独立任务的一致输出。
例:FCOS 和 ATSS 都使用 centerness 分支。以提高从对象中心附近的锚点预测的分类分数,并为相应锚点的定位损失分配更大的权重。
目前存在的问题:
(1) 分类和定位的独立性。即,并行使用两个独立的分支执行对象分类和定位。
(2) 与任务无关的样本分配。即,样本分配方案与是分类任务还是定位任务无关,因此可能难以对这两个任务做出准确而一致的预测,因此,在非极大值抑制 (NMS) 期间,精度较低的边界框可能会抑制精确的边界框。
anchor-free检测器使用基于几何的分配方案来选择目标中心附近的锚点进行分类和定位
anchor-based的检测器通常通过计算anchor boxs和ground truth之间的 IoU 来分配锚框

提出的方案 - TOOD
task-aligned One-stage Object Detection (TOOD)

1. 任务对齐头-Task-aligned head.
它计算任务的交互特征,并通过 任务对齐预测器 Task-Aligned Predictor(TAP) 进行预测。 然后它根据任务对齐学习Task alignment learning(TAL)提供的学习信号对齐两个预测的空间分布。
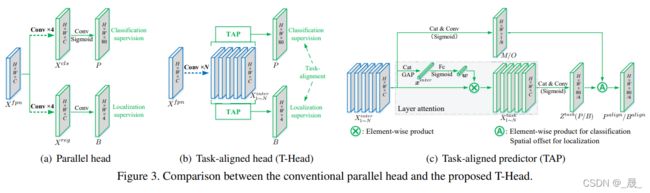
上图,3(a)为常规设计,3(b)为T-Head 结构,他拥有一个简单的特征提取器和两个任务对齐预测器 (TAP)。TAP的结构如 3(c)所示。
![]() 表示 FPN 特征,其中 H、W 和 C 分别表示高度、宽度和通道数。
表示 FPN 特征,其中 H、W 和 C 分别表示高度、宽度和通道数。
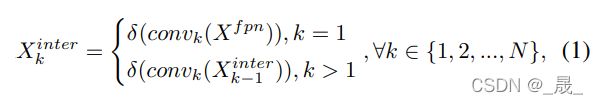
![]() 和 δ 分别指第 k 个 conv 层和一个 relu 函数。 因此,我们使用头部中的单个分支从 FPN 特征中提取丰富的多尺度特征。 然后,计算出的任务交互特征将被输入到两个 TAP 中,用于对齐分类和定位。
和 δ 分别指第 k 个 conv 层和一个 relu 函数。 因此,我们使用头部中的单个分支从 FPN 特征中提取丰富的多尺度特征。 然后,计算出的任务交互特征将被输入到两个 TAP 中,用于对齐分类和定位。
1.1 任务对齐预测器 (TAP)

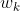 是学习的注意力层
是学习的注意力层![]() 的第 k 个元素。
的第 k 个元素。  是从跨层任务交互特征计算出来的,并且能够捕获层之间的依赖关系。
是从跨层任务交互特征计算出来的,并且能够捕获层之间的依赖关系。

其中![]() 和
和 ![]() 指的是两个全连接层。
指的是两个全连接层。  是一个 sigmoid 函数,并且
是一个 sigmoid 函数,并且 ![]() 是通过对
是通过对 ![]() 应用平均池化来获得的,
应用平均池化来获得的,![]() 是
是 ![]() 的连接特征。最后,分类或定位结果从每个
的连接特征。最后,分类或定位结果从每个![]() 预测:
预测:

然后使用 sigmoid 函数将![]() 转换为密集分类分数
转换为密集分类分数![]() ,或使用 [27、31] 中应用的距离到 bbox 转换的对象边界框
,或使用 [27、31] 中应用的距离到 bbox 转换的对象边界框![]() 。
。
使用空间概率图![]() ,来调整分类预测:
,来调整分类预测:
使用空间偏移图 ![]() ,用于调整每个位置的预测边界框,(M和O利用TAL学习)
,用于调整每个位置的预测边界框,(M和O利用TAL学习)
![]()

对于B 值得注意的是,每个通道的偏移量都是独立学习的,这意味着对象的每个边界都有自己的学习偏移量。这允许对四个边界进行更准确的预测,因为它们中的每一个都可以单独从其附近最精确的锚点学习。因此,不仅协调了这两个任务,而且通过为每边确定一个精确的锚点来提高定位精度。
T-Head是一个独立的模块,可以在没有TAL的情况下正常工作。它可以方便地以即插即用的方式应用于各种一级物体检测器,以提高检测性能。
对齐图 M 和 O 是从交互式特征中自动学习的:

2. 任务对齐学习-Task alignment learning.
用途:拉近分类和定位任务的两个最佳锚点
方法:(1)样本分配方案,通过计算每个锚点的任务对齐程度来收集正负样本
(2)任务对齐损失,逐渐统一最佳锚点,用于在训练期间预测分类和定位。
2.1 样本分配方案-Task-aligned Sample Assignment
(1)锚点对齐指标:对齐良好的anchor应该能够预测高分类分数和精确定位;
新的锚对齐指标 t

其中 s 和 u 分别表示分类分数和 IoU 值。 α 和 β 用于控制两个任务在锚对齐度量中的影响。
(2)训练样本分配:未对齐的anchor应该有一个低分类分数并随后被抑制。
对于每个实例,我们选择m个t值最大的anchor作为正样本,而使用剩余的 锚定为负样本。
2.2 任务对齐损失-Task-aligned Loss
为了显式增加对齐锚的分类分数,同时降低未对齐锚的分数(即具有较小的 t),我们在训练期间使用 t 替换正锚的二进制标签(即是否包含物体的软标签)。
又发现当 t 随着 α 和 β 的增加而变小时,网络无法收敛。因此,使用归一化的 t,即 ![]() ,来代替正锚的二进制标签。
,来代替正锚的二进制标签。 ![]() 的最大值等于每个实例内的最大 IoU 值 (u)。
的最大值等于每个实例内的最大 IoU 值 (u)。
分类任务的loss:
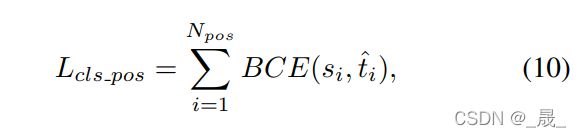
引入focal loss 减轻正负样本不平衡。
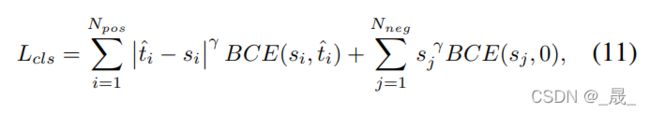
加权![]() ,边界框回归损失 loss:
,边界框回归损失 loss:
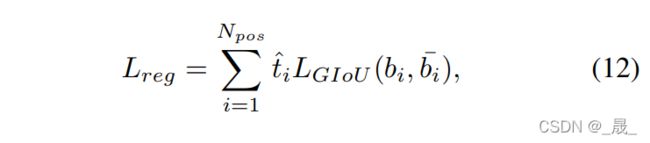
![]()