【PyTorch】PyTorch神经网络实战入门
Google Colab
- 我们使用由谷歌提供的Colab免费服务,在谷歌的服务器上运行代码。登录谷歌账号之后,通过访问 https://colab.research.google.com 来激活谷歌Colab服务。


- 神经网络的输出由链接权重计算得出。输出依赖于权重,就像y依赖于x。


- 假设,一个简单网络的输出是z,正确的输出是t。那么,误差E即是 ( z − t ) (z-t) (z−t),或者 ( z − t ) 2 (z-t)^2 (z−t)2。误差E只是网络的一个节点,该网络以 ( z − t ) 2 (z-t)^2 (z−t)2,从z计算E的值。现在,有效的输出节点是E,而不是z。PyTorch 可以计算出新的E对于输入的梯度。
获取MNIST数据集
训练数据:https://pjreddie.com/media/files/mnist_train.csv
测试数据:https://pjreddie.com/media/files/mnist_test.csv
- 我们要确保上传的数据能够被Python代码访问。这需要我们加载Google Drive,使它作为一个文件夹出现。
# 加载数据文件
from google.colab import drive
drive.mount('./mount')
- 我们使用pandas库来加载和查看数据。

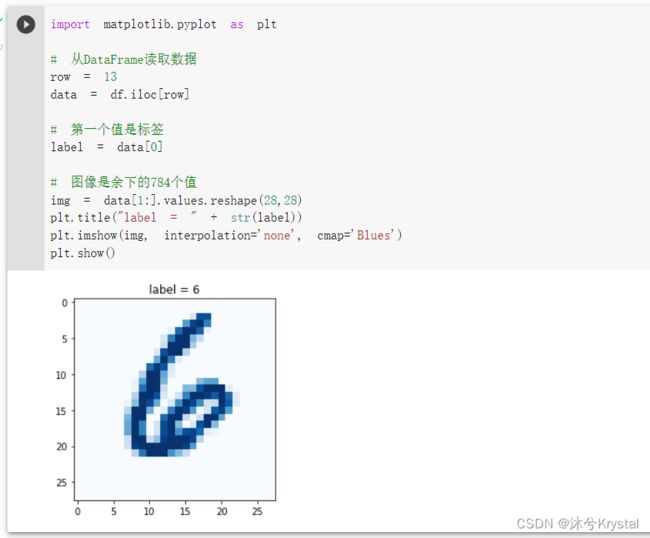
- 我们将一行像素值转换成实际图像来直观地查看一下。
简单的神经网络

- 构建神经网络类,以下为一个名为Classifier的类,它继承了nn.Module。PyTorch.nn模块会为我们设置分类器。
- 定义神经网络的模块,以及正向的信息传导
- 定义如何计算误差,以及用误差更新网络的可学习参数。
class Classifier(nn.Module):
def __init__(self):
# 初始化PyTorch父类
super().__init__()
# 定义神经网络层
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.Sigmoid(),
nn.Linear(200, 10),
nn.Sigmoid()
)
# 创建损失函数
self.loss_function = nn.MSELoss()
# 创建优化器,使用简单的梯度下降
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
def forward(self, inputs):
# 直接运行模型
return self.model(inputs)
- PyTorch假定通过一个forward()方法向网络传递信息。这里,我们将输入传递给self.model(),它由nn.Sequential() 定义。模型的输出直接返回给 forward() 的主调函数。
- PyTorch允许我们按自己的想法构建网络的训练代码。train() 函数首先要做的是,使用forward()函数传递输入值给网络,并获得输出值。
def train(self, inputs, targets):
# 计算网络的输出值
outputs = self.forward(inputs)
# 计算损失值
loss = self.loss_function(outputs, targets)
- 使用损失来更新网络的链接权重。
- 首先,optimiser.zero_grad() 将计算图中的梯度全部归零。
- 其次,loss.backward() 从loss函数中计算网络中的梯度。
- 最后,optimiser.step() 使用这些梯度来更新网络的可学习参数。
# 梯度归零,反向传播,并更新权重
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
- 在每次训练网络之前,我们需要将梯度归零。否则,每次 loss.backward() 计算出来的梯度会累积。
- 我们可以把计算图的最终节点看作损失函数,该函数对每个进入损失的节点计算梯度,这些梯度是损失随着每个可学习参数的变化。
可视化训练
- 在神经网络类的构造函数中,创建一个初始值为0的计数器(counter)以及一个名为 progress 的空列表
# 记录训练进展的计数器和列表
self.counter = 0
self.progress = []
- 在train()函数中,我们可以每隔10个训练样本增加一次计数器的值,并将损失值添加进列表的末尾
# 增加一次计数器的值,每隔10个训练样本将损失值添加进列表的末尾
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
- 要将损失绘制成图,可以在神经网络类中添加一个新函数 plot_progress()。
MNIST数据集类
- 尝试以PyTorch的方式加载和使用数据。
class MnistDataset(Dataset):
def __init__(self, csv_file):
self.data_df = pandas.read_csv(csv_file, header=None)
pass
def __len__(self):
return len(self.data_df)
def __getitem__(self, index):
# 目标图像(标签)
label = self.data_df.iloc[index, 0]
target = torch.zeros((10)) # 创建一个维度为10的张量变量,神经网络的预期输出
target[label] = 1.0 # 与标签相对应的张量是1,其他都是0
# 图像数据,取值范围是0~255,标准化为0~1
image_values = torch.FloatTensor(self.data_df.iloc
[index, 1:].values) / 255.0
# 返回标签、图像数据张量以及目标张量
return label, image_values, target
pass
- 我们也可以为MnistDataset类添加一个制图方法,以方便查看我们正在处理的数据
def plot_image(self, index):
arr = self.data_df.iloc[index,1:].values.reshape(28,28)
plt.title("label = " + str(self.data_df.iloc[index,0]))
plt.imshow(arr, interpolation='none', cmap='Blues')
pass

训练分类器
%%time
# 创建神经网络
C = Classifier()
# 在MNIST数据集训练神经网络
epochs = 3
for i in range(epochs):
print('training epoch', i+1, "of", epochs)
for label, image_data_tensor, target_tensor in mnist_dataset:
C.train(image_data_tensor, target_tensor)
pass
pass
- 绘制收集到的损失值,以了解训练的进展。

查询神经网络
- 用一个新的Dataset对象来加载数据集

- 看看训练过的神经网络是如何判断这副图像的。使用 forward() 函数将图像传递并通过神经网络。

改良方法
激活函数
- S型逻辑函数具有一些缺点,最主要的一个缺点是,在输入值变大时,梯度会变得非常小甚至消失。这意味着,在训练神经网络时,如果发生这种饱和,我们无法通过梯度来更新链接权重。
- 带泄漏线性整流函数(Leaky ReLU),在函数的左半边增加一个小梯度。
# 定义神经网络层
self.model = nn.Sequential(
nn.Linear(784, 200),
# nn.Sigmoid(),
nn.LeakyReLU(0.02), # 0.02是函数左半边的梯度
nn.Linear(200, 10),
# nn.Sigmoid()
nn.LeakyReLU(0.02)
)
- 随机梯度下降法的缺点之一是,它会陷入损失函数的局部最小值(local minima)。另一个缺点是,它对所有可学习的参数都使用单一的学习率。最常见的替代方案是Adam,它利用动量的概念,减少陷入局部最小值的可能性,同时,它对每个可学习的参数使用单独的学习率,这些学习率随着每个参数在训练期间的变化而改变。