paddle2.3和torch1.8在SentenceBert上的性能对比
写在前面。。。对比了个寂寞,paddle框架目前有bug——或者我代码有bug。。。torch完胜
目录
一、背景介绍
二、paddle和torch实现SentenceBert
1、SentenceBert
2、torch实现
3、paddle实现
三、效果对比
一、背景介绍
为什么要写这样的一篇对比paddle和torch的博客呢?
百度的paddle开源的一些模型和权重非常好,为了后续工作能更好的利用百度开源的一些模型权重和方法,因此学习好paddle也是有必要的;另外paddle的生态也是越发完善,对标huggingface的transformer和它的模型下载中心,百度也出品了paddlenlp.transformer和paddlehub,同时paddle框架本身也做的越来越好,越来越成熟,它的API和torch也是大同小异,学习成本也比较低,所有更有必要好好学习一下paddle这个框架。
习惯使用了torch做深度学习,再使用paddle必然也会有一点点不顺手,毕竟API还是有一些差异的,但是这个真的要比torch和tensorflow的差距要小很多。为了能顺利的使用paddle来完成一个文本分类的例子,强迫自己输出一篇博客,把实现SentenceBert文本分类过程中一些问题和经验积累下来,也是作为学习paddle的一个开始。
总体来说,百度出品的paddle可以用起来了,做的越来越好了,开源的一些模型也是有中文领域的,和torch的差距正在变小,好的东西都是要掌握的。
SentenceBert做文本分类和匹配是很经典的了,到现在我都认为还是比较能打的,效果确实比较好,实现起来比较容易,当然现在的提示学习呀还有苏神的consenBert在效果上确实要比SentenceBert要好,不过这里重点在于使用paddle实现文本分类的任务,以及对比一下torch,它们在效果和效率上的差异。
二、paddle和torch实现SentenceBert
1、SentenceBert
具体的模型细节就不多说了,放个图做个简介吧
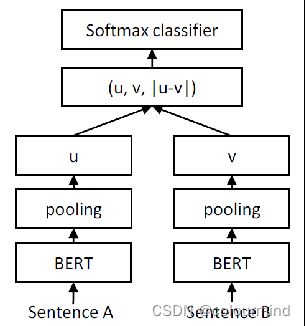
Bert模型共享参数,把v、u和|u-v|拼接起来,得到分类特征;pooling这里也比较有特色,采用mean_pooling并且把padding部分的0都考虑进来了,消除这部分数据对结果的影响。
2、torch实现
模型代码sentence_bert.py
import torch.nn as nn
from transformers import BertModel
from transformers import BertPreTrainedModel
import torch
class SentenceBert(BertPreTrainedModel):
def __init__(self,config):
super(SentenceBert,self).__init__(config)
self.bert = BertModel(config=config)
self.classifier = nn.Linear(3*config.hidden_size,config.num_labels)
def forward(self,inputs):
input_a = inputs[0]
input_b = inputs[1]
output_a = self.bert(**input_a,return_dict=True, output_hidden_states=True)
output_b = self.bert(**input_b,return_dict=True, output_hidden_states=True)
#采用最后一层
embedding_a = output_a.hidden_states[-1]
embedding_b = output_b.hidden_states[-1]
embedding_a = self.pooling(embedding_a,input_a)
embedding_b = self.pooling(embedding_b, input_b)
embedding_abs = torch.abs(embedding_a - embedding_b)
vectors_concat = []
vectors_concat.append(embedding_a)
vectors_concat.append(embedding_b)
vectors_concat.append(embedding_abs)
# 列拼接3个768————>3*768
features = torch.cat(vectors_concat, 1)
output = self.classifier(features)
return output
def pooling(self,token_embeddings,input):
output_vectors = []
#attention_mask
attention_mask = input['attention_mask']
#[B,L]------>[B,L,1]------>[B,L,768],矩阵的值是0或者1
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
#这里做矩阵点积,就是对元素相乘(序列中padding字符,通过乘以0给去掉了)[B,L,768]
t = token_embeddings * input_mask_expanded
#[B,768]
sum_embeddings = torch.sum(t, 1)
# [B,768],最大值为seq_len
sum_mask = input_mask_expanded.sum(1)
#限定每个元素的最小值是1e-9,保证分母不为0
sum_mask = torch.clamp(sum_mask, min=1e-9)
#得到最后的具体embedding的每一个维度的值——元素相除
output_vectors.append(sum_embeddings / sum_mask)
#列拼接
output_vector = torch.cat(output_vectors, 1)
return output_vector数据读取dataReader_tsv.py
from tqdm import tqdm
import torch
import pandas as pd
class DataReader(object):
def __init__(self,tokenizer,filepath,max_len):
self.tokenizer = tokenizer
self.filepath = filepath
self.max_len = max_len
self.dataList = self.datas_to_torachTensor()
self.allLength = len(self.dataList)
def convert_text2ids(self,text):
text = text[0:self.max_len-2]
inputs = self.tokenizer(text)
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
paddings = [0] * (self.max_len - len(input_ids))
input_ids += paddings
attention_mask += paddings
token_type_id = [0] * self.max_len
return input_ids, attention_mask, token_type_id
def datas_to_torachTensor(self):
# with open(self.filepath,'r',encoding='utf-8') as f:
# lines = f.readlines()
df = pd.read_csv(self.filepath,sep='\t')
df.dropna(inplace=True)
lines_a = df['sentence1'].values.tolist()
lines_b = df['sentence2'].values.tolist()
labels = df['label'].values.tolist()
res = []
for line_a,line_b,label in tqdm(zip(lines_a,lines_b,labels),desc='tokenization',ncols=50):
temp = []
try:
if line_a != '' and len(line_a) > 0 and line_b != '' and len(line_b) > 0:
input_ids_a, attention_mask_a, token_type_id_a = self.convert_text2ids(text=line_a)
input_ids_a = torch.as_tensor(input_ids_a, dtype=torch.long)
attention_mask_a = torch.as_tensor(attention_mask_a, dtype=torch.long)
token_type_id_a = torch.as_tensor(token_type_id_a, dtype=torch.long)
temp.append(input_ids_a)
temp.append(attention_mask_a)
temp.append(token_type_id_a)
input_ids_b, attention_mask_b, token_type_id_b = self.convert_text2ids(text=line_b)
input_ids_b = torch.as_tensor(input_ids_b, dtype=torch.long)
attention_mask_b = torch.as_tensor(attention_mask_b, dtype=torch.long)
token_type_id_b = torch.as_tensor(token_type_id_b, dtype=torch.long)
temp.append(input_ids_b)
temp.append(attention_mask_b)
temp.append(token_type_id_b)
label = torch.as_tensor(label,dtype=torch.long)
temp.append(label)
res.append(temp)
except Exception as e:
print(e)
return res
def __getitem__(self, item):
input_ids_a = self.dataList[item][0]
attention_mask_a = self.dataList[item][1]
token_type_id_a = self.dataList[item][2]
input_ids_b = self.dataList[item][3]
attention_mask_b = self.dataList[item][4]
token_type_id_b = self.dataList[item][5]
label = self.dataList[item][6]
return input_ids_a, attention_mask_a, token_type_id_a, input_ids_b, attention_mask_b, token_type_id_b, label
def __len__(self):
return self.allLength模型训练train_sentence_bert.py
import torch
import argparse
from data_reader.dataReader_tsv import DataReader
from model.sentence_bert_copy import SentenceBert
from torch.utils.data import DataLoader
import torch.nn.functional as F
from torch.optim import AdamW
from torch.optim.lr_scheduler import ReduceLROnPlateau
from transformers import BertTokenizer,BertConfig
import os
from tools.progressbar import ProgressBar
from tools.log import Logger
from datetime import datetime
from torch.nn.utils.rnn import pad_sequence
logger = Logger('sbert_loger',log_level=10,log_file = "./log_output/sbert_pawsx_torch.log").logger
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
def parse_args():
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("--max_len",type=int,default=64)
parser.add_argument("--train_file", type=str,default='./data/paws_x/translated_train.tsv', help="train text file")
parser.add_argument("--val_file", type=str, default='./data/paws_x/dev_2k.tsv',help="val text file")
parser.add_argument("--pretrained", type=str, default="./pretrained_models/torch/chinese-bert-wwm-ext", help="huggingface pretrained model")
parser.add_argument("--model_out", type=str, default="./output/pawsx", help="model output path")
parser.add_argument("--batch_size", type=int, default=128, help="batch size")
parser.add_argument("--epochs", type=int, default=10, help="epochs")
parser.add_argument("--lr", type=float, default=1e-5, help="epochs")
parser.add_argument("--task_type",type=str,default='classification')
args = parser.parse_args()
return args
def collate_fn(batch):
input_ids_a, attention_mask_a, token_type_id_a, input_ids_b, attention_mask_b, token_type_id_b, label = zip(*batch)
input_ids_a = pad_sequence(input_ids_a,batch_first=True,padding_value=0)
attention_mask_a = pad_sequence(attention_mask_a, batch_first=True, padding_value=0)
token_type_id_a = pad_sequence(token_type_id_a, batch_first=True, padding_value=0)
input_ids_b = pad_sequence(input_ids_b, batch_first=True, padding_value=0)
attention_mask_b = attention_mask_b(attention_mask_b, batch_first=True, padding_value=0)
token_type_id_b = pad_sequence(token_type_id_b, batch_first=True, padding_value=0)
label = torch.stack(label)
return input_ids_a, attention_mask_a, token_type_id_a, input_ids_b, attention_mask_b, token_type_id_b, label
def train(args):
logger.info("args: %s",args)
tokenizer = BertTokenizer.from_pretrained(args.pretrained)
config = BertConfig.from_pretrained(args.pretrained)
device = "cuda" if torch.cuda.is_available() else "cpu"
task_type = args.task_type
model = SentenceBert.from_pretrained(config=config, pretrained_model_name_or_path=args.pretrained)
model.to(device)
train_dataset = DataReader(tokenizer=tokenizer,filepath=args.train_file,max_len=args.max_len)
train_dataloader = DataLoader(train_dataset,batch_size=args.batch_size,shuffle=True, collate_fn = collate_fn)
val_dataset = DataReader(tokenizer=tokenizer,filepath=args.val_file,max_len=args.max_len)
val_dataloader = DataLoader(val_dataset, batch_size=args.batch_size, shuffle=False,collate_fn=collate_fn)
optimizer = AdamW(model.parameters(),lr=args.lr)
scheduler = ReduceLROnPlateau(optimizer=optimizer,mode='max',factor=0.5, patience=5)
model.train()
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataloader))
logger.info(" Num Epochs = %d", args.epochs)
time_srt = datetime.now().strftime('%Y-%m-%d')
save_path = os.path.join(args.model_out, "paddle_" + time_srt)
patience = 5
no_best_epoch = 0
best_acc = 0.0
for epoch in range(args.epochs):
pbar = ProgressBar(n_total=len(train_dataloader), desc='Training')
for step,batch in enumerate(train_dataloader):
batch = [t.to(device) for t in batch]
inputs_a = {'input_ids':batch[0],'attention_mask':batch[1],'token_type_ids':batch[2]}
inputs_b = {'input_ids': batch[3], 'attention_mask': batch[4], 'token_type_ids': batch[5]}
labels = batch[6]
inputs = []
inputs.append(inputs_a)
inputs.append(inputs_b)
output = model(inputs)
loss = F.cross_entropy(output,labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
pbar(step, {'loss':loss.item()})
val_acc = valdation(model, val_dataloader, device, task_type)
scheduler.step(val_acc)
if val_acc > best_acc:
best_acc = val_acc
if not os.path.exists(save_path):
os.makedirs(save_path)
logger.info("save model")
model.save_pretrained(save_path)
tokenizer.save_vocabulary(save_path)
no_best_epoch = 0
else:
no_best_epoch += 1
logger.info("val_acc:%.4f------best_acc:%.4f" % (val_acc, best_acc))
if no_best_epoch >= patience:
logger.info("taining finished because of no improving" )
break
def valdation(model,val_dataloader,device):
total = 0
total_correct = 0
model.eval()
with torch.no_grad():
pbar = ProgressBar(n_total=len(val_dataloader), desc='evaldation')
for step, batch in enumerate(val_dataloader):
batch = [t.to(device) for t in batch]
inputs_a = {'input_ids': batch[0], 'attention_mask': batch[1], 'token_type_ids': batch[2]}
inputs_b = {'input_ids': batch[3], 'attention_mask': batch[4], 'token_type_ids': batch[5]}
labels = batch[6]
inputs = []
inputs.append(inputs_a)
inputs.append(inputs_b)
output = model(inputs)
pred = torch.argmax(output, dim=1)
correct = (labels == pred).sum()
total_correct += correct
total += labels.size()[0]
loss = F.cross_entropy(output, labels)
pbar(step, {'loss': loss.item()})
acc = total_correct / total
return acc
def main():
torch.manual_seed(1)
torch.cuda.manual_seed(1)
args =parse_args()
train(args)
if __name__ == '__main__':
main()torch的代码比较简单,就不做多的解释和说明了,有一个需要注意的地方就是记得要设置随机种子。
torch.manual_seed(1) torch.cuda.manual_seed(1)
下面来看paddle的实现
3、paddle实现
模型组网代码
模型实现,模型计算逻辑使用的API和torch基本相同,只需要修改如下:
torch.cat()------------------paddle.concat()
torch.clamp()------------------paddle.clip()
......
其他的基本只需要把torch修改为paddle就可以了,主要的不同用法:
transformer中的bert输出是一个字典
bert(**input_a,return_dict=True, output_hidden_states=True).hidden_states[-1]
paddlenlp.transformer中的bert输出是一个list 第一个元素是每一层的hidden_states;第二个元素就是pooled_output也就是cls向量;所以一般采用如下代码:
bert(**input_a, output_hidden_states=True)[0][-1]最后一层的hidden_states
关于模型权重和配置文件的加载也不一样
paddle在指定模型名称的时候会采取自动下载模型和权重,然后再加载的方式
SentenceBert.from_pretrained('bert-wwm-ext-chinese')
会把模型权重和配置文件保存在/root/.paddlenlp/models/bert-wwm-ext-chinese路径下:
内容如上图所示
如果要像torch一样加载本地的bert等预训练模型,需要先使用paddlenlp.transformers把模型权重下载后,然后使用model.save_pretrained(local_path)保存模型权重和模型配置文件(自动下载的时候是没有模型配置文件的),tokenizer.save_pretrained(local_path)保存词表。上述保存的文件名和自动下载的是不一样的:
注意模型权重文件model_state.pdparams;模型配置文件model_config.json,并且model_config.json和torch下的bert模型配置文件格式不同:
{
"init_args":[
{
"vocab_size":21128,
"hidden_size":768,
"num_hidden_layers":12,
"num_attention_heads":12,
"intermediate_size":3072,
"hidden_act":"gelu",
"hidden_dropout_prob":0.1,
"attention_probs_dropout_prob":0.1,
"max_position_embeddings":512,
"type_vocab_size":2,
"initializer_range":0.02,
"pad_token_id":0,
"init_class":"BertModel"
}
],
"init_class":"SentenceBert"
}
模型组网如下sentence_bert.py:
from paddlenlp.transformers import BertPretrainedModel,BertModel
import paddle.nn as nn
import paddle
class SentenceBert(BertPretrainedModel):
"""
__init__(self,bert) 一定要带一个参数,外层from_pretrained()才能成功
bert会在from_pretrained()的时候初始化成功然后传入
"""
# base_model_prefix = "bert"
def __init__(self, bert):
super(SentenceBert,self).__init__()
self.bert = bert
self.classifier = nn.Linear(3*768,2)
def forward(self, inputs, **kwargs):
input_a = inputs[0]
input_b = inputs[1]
output_a = self.bert(**input_a, output_hidden_states=True)
output_b = self.bert(**input_b, output_hidden_states=True)
# 采用最后一层
embedding_a = output_a[0][-1]
embedding_b = output_b[0][-1]
embedding_a = self.pooling(embedding_a, input_a)
embedding_b = self.pooling(embedding_b, input_b)
embedding_abs = paddle.abs(embedding_a - embedding_b)
vectors_concat = []
vectors_concat.append(embedding_a)
vectors_concat.append(embedding_b)
vectors_concat.append(embedding_abs)
# 列拼接3个768————>3*768
features = paddle.concat(vectors_concat,axis=-1)
output = self.classifier(features)
return output
def pooling(self, token_embeddings, input):
output_vectors = []
# attention_mask
attention_mask = input['attention_mask']
# [B,L]------>[B,L,1]------>[B,L,768],矩阵的值是0或者1
# input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
input_mask_expanded = paddle.unsqueeze(attention_mask,-1)
input_mask_expanded = paddle.expand(input_mask_expanded,shape=[input_mask_expanded.shape[0],input_mask_expanded.shape[1],token_embeddings.shape[-1]])
# 这里做矩阵点积,就是对元素相乘(序列中padding字符,通过乘以0给去掉了)[B,L,768]
t = token_embeddings * input_mask_expanded
# [B,768]
sum_embeddings = paddle.sum(t, 1)
# [B,768],最大值为seq_len
sum_mask = input_mask_expanded.sum(1)
# 限定每个元素的最小值是1e-9,保证分母不为0
sum_mask = paddle.clip(sum_mask, min=1e-9)
# 得到最后的具体embedding的每一个维度的值——元素相除
output_vectors.append(sum_embeddings / sum_mask)
# 列拼接
output_vector = paddle.concat(output_vectors, 1)
return output_vector上述组网的方式,加载权重的时候要注意这个init中的bert不是我们传入的参数,而是
SentenceBert.from_pretrained(pretrained_model_name_or_path=args.pretrained)自动传入的参数
但是在模型结构定义的时候一定的传入一个参数才不会报错。
数据加载dataReader.py
from paddle.io import Dataset
import pandas as pd
from tqdm import tqdm
import paddle
class DataReader(Dataset):
def __init__(self, tokenizer, filepath, max_len):
self.tokenizer = tokenizer
self.filepath = filepath
self.max_len = max_len
self.dataList = self.datas_to_torachTensor()
self.allLength = len(self.dataList)
def convert_text2ids(self, text):
text = text[0:self.max_len - 2]
inputs = self.tokenizer(text)
input_ids = inputs['input_ids']
attention_mask = [1]*len(input_ids)
token_type_id = inputs["token_type_ids"]
return input_ids, attention_mask, token_type_id
def datas_to_torachTensor(self):
df = pd.read_csv(self.filepath, sep='\t')
df.dropna(inplace=True)
lines_a = df['sentence1'].values.tolist()
lines_b = df['sentence2'].values.tolist()
labels = df['label'].values.tolist()
res = []
for line_a, line_b, label in tqdm(zip(lines_a[0:], lines_b[0:], labels[0:]), desc='tokenization', ncols=50):
temp = []
try:
if line_a != '' and len(line_a) > 0 and line_b != '' and len(line_b) > 0:
input_ids_a, attention_mask_a, token_type_id_a = self.convert_text2ids(text=line_a)
input_ids_a = paddle.to_tensor(input_ids_a,dtype='int64')
attention_mask_a = paddle.to_tensor(attention_mask_a, dtype='int64')
token_type_id_a = paddle.to_tensor(token_type_id_a, dtype='int64')
temp.append(input_ids_a)
temp.append(attention_mask_a)
temp.append(token_type_id_a)
input_ids_b, attention_mask_b, token_type_id_b = self.convert_text2ids(text=line_b)
input_ids_b = paddle.to_tensor(input_ids_b, dtype='int64')
attention_mask_b = paddle.to_tensor(attention_mask_b, dtype='int64')
token_type_id_b = paddle.to_tensor(token_type_id_b, dtype='int64')
temp.append(input_ids_b)
temp.append(attention_mask_b)
temp.append(token_type_id_b)
label = paddle.to_tensor(label, dtype='int64')
temp.append(label)
res.append(temp)
except Exception as e:
print(e)
return res
def __getitem__(self, item):
input_ids_a = self.dataList[item][0]
attention_mask_a = self.dataList[item][1]
token_type_id_a = self.dataList[item][2]
input_ids_b = self.dataList[item][3]
attention_mask_b = self.dataList[item][4]
token_type_id_b = self.dataList[item][5]
label = self.dataList[item][6]
return input_ids_a, attention_mask_a, token_type_id_a, input_ids_b, attention_mask_b, token_type_id_b, label
def __len__(self):
return self.allLength模型训练train_sentence_bert.py
注意的是这里是随机种子的设置比较严格仅仅一个paddle.seed()并不能保证训练的可复现和一致。还需要其他的设置:
paddle.seed(1) random.seed(1) np.random.seed(1)
这样设置比较靠谱,有可能不知道的地方隐式的调用了上面的random和numpy库,保险起见最好设置一下比较好。paddle的
DataLoader(train_dataset,batch_size=args.batch_size,shuffle=True, collate_fn=collate_fn)
这句代码中的 shuffle 应该是引用了random包 所以每次batch出来的数据不一样,所以random也要设置seed
from data_reader.dataReader import DataReader
from model.sentence_bert import SentenceBert
import argparse
from tools.progressbar import ProgressBar
from tools.log import Logger
from datetime import datetime
import os
from paddlenlp.transformers import BertTokenizer
from paddle.io import DataLoader
from paddle.optimizer import AdamW
from paddle.optimizer.lr import ReduceOnPlateau
import paddle
import paddle.nn.functional as F
import numpy as np
import random
paddle.seed(1)
random.seed(1)
np.random.seed(1)
logger = Logger('paddle_sbert_loger',log_level=10,log_file='./log_output/pawsx_sbert_paddle.log').logger
paddle.set_device('gpu:0')
def parse_args():
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("--max_len",type=int,default=64)
parser.add_argument("--train_file", type=str,default='./data/paws_x/translated_train.tsv', help="train text file")
parser.add_argument("--val_file", type=str, default='./data/paws_x/dev_2k.tsv',help="val text file")
parser.add_argument("--pretrained", type=str, default="pretrained_models/paddle/bert-wwm-ext-chinese", help="huggingface pretrained model")
parser.add_argument("--model_out", type=str, default="./output", help="model output path")
parser.add_argument("--batch_size", type=int, default=64, help="batch size")
parser.add_argument("--epochs", type=int, default=10, help="epochs")
parser.add_argument("--lr", type=float, default=1e-5, help="epochs")
parser.add_argument("--task_type",type=str,default='classification')
args = parser.parse_args()
return args
def collate_fn(batch):
input_ids_a, attention_mask_a, token_type_id_a, input_ids_b, attention_mask_b, token_type_id_b, label = zip(*batch)
print(input_ids_a)
exit()
bz = len(input_ids_a)
max_a = 0
for i in range(len(input_ids_a)):
if input_ids_a[i].shape[0] > max_a:
max_a = input_ids_a[i].shape[0]
input_ids_a_pad = paddle.zeros(shape=[bz,max_a],dtype="int64")
for i in range(len(input_ids_a)):
l = input_ids_a[i].shape[0]
input_ids_a_pad[i,0:l] = input_ids_a[i]
attention_mask_a_pad = paddle.zeros(shape=[bz, max_a],dtype="int64")
for i in range(len(input_ids_a)):
l = attention_mask_a[i].shape[0]
attention_mask_a_pad[i, 0:l] = attention_mask_a[i]
token_type_id_a_pad = paddle.zeros(shape=[bz, max_a],dtype="int64")
for i in range(len(input_ids_a)):
l = token_type_id_a[i].shape[0]
token_type_id_a_pad[i, 0:l] = token_type_id_a[i]
max_b = 0
for i in range(len(input_ids_b)):
if input_ids_b[i].shape[0] > max_b:
max_b = input_ids_b[i].shape[0]
input_ids_b_pad = paddle.zeros(shape=[bz, max_b],dtype="int64")
for i in range(len(input_ids_b)):
l = input_ids_b[i].shape[0]
input_ids_b_pad[i, 0:l] = input_ids_b[i]
attention_mask_b_pad = paddle.zeros(shape=[bz, max_b],dtype="int64")
for i in range(len(input_ids_b)):
l = attention_mask_b[i].shape[0]
attention_mask_b_pad[i, 0:l] = attention_mask_b[i]
token_type_id_b_pad = paddle.zeros(shape=[bz, max_b],dtype="int64")
for i in range(len(input_ids_b)):
l = token_type_id_b[i].shape[0]
token_type_id_b_pad[i, 0:l] = token_type_id_b[i]
label = paddle.stack(label,axis=0)
return input_ids_a_pad, attention_mask_a_pad, token_type_id_a_pad, input_ids_b_pad, attention_mask_b_pad, token_type_id_b_pad, label
def train(args):
logger.info("args: %s",args)
##会自动下载相应的权重和配置文件
#tokenizer = BertTokenizer.from_pretrained('bert-wwm-ext-chinese')
#model = SentenceBert.from_pretrained('bert-wwm-ext-chinese')
tokenizer = BertTokenizer.from_pretrained(pretrained_model_name_or_path=args.pretrained)
model = SentenceBert.from_pretrained(pretrained_model_name_or_path=args.pretrained)
train_dataset = DataReader(tokenizer=tokenizer,filepath=args.train_file,max_len=args.max_len)
train_dataloader = DataLoader(train_dataset,batch_size=args.batch_size,shuffle=True, collate_fn=collate_fn)
val_dataset = DataReader(tokenizer=tokenizer,filepath=args.val_file,max_len=args.max_len)
val_dataloader = DataLoader(val_dataset, batch_size=args.batch_size, shuffle=False, collate_fn=collate_fn)
optimizer = AdamW(parameters = model.parameters(),learning_rate = args.lr)
scheduler = ReduceOnPlateau(learning_rate= args.lr,mode='max',factor=0.5, patience=5)
model.train()
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataloader))
logger.info(" Num Epochs = %d", args.epochs)
time_srt = datetime.now().strftime('%Y-%m-%d')
save_path = os.path.join(args.model_out,"paddle_" + time_srt)
best_acc = 0.0
patience = 5
no_best_epoch = 0
model.train()
for epoch in range(args.epochs):
pbar = ProgressBar(n_total=len(train_dataloader), desc='Training')
for step,batch in enumerate(train_dataloader):
inputs_a = {'input_ids':batch[0],'attention_mask':batch[1],'token_type_ids':batch[2]}
inputs_b = {'input_ids': batch[3], 'attention_mask': batch[4], 'token_type_ids': batch[5]}
labels = batch[6]
inputs = []
inputs.append(inputs_a)
inputs.append(inputs_b)
output = model(inputs)
loss = F.cross_entropy(output,labels)
loss.backward()
optimizer.step()
optimizer.clear_grad()
pbar(step, {'loss':loss.item()})
val_acc = valdation(model, val_dataloader)
scheduler.step(val_acc)
if val_acc > best_acc:
best_acc = val_acc
if not os.path.exists(save_path):
os.makedirs(save_path)
logger.info("save model")
model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
no_best_epoch = 0
else:
no_best_epoch += 1
logger.info("val_acc:%.4f------best_acc:%.4f" % ( val_acc, best_acc))
if no_best_epoch >= patience:
logger.info("taining finished because of no improving" )
exit()
def valdation(model,val_dataloader):
total = 0
total_correct = 0
model.eval()
with paddle.no_grad():
pbar = ProgressBar(n_total=len(val_dataloader), desc='evaldation')
for step, batch in enumerate(val_dataloader):
inputs_a = {'input_ids': batch[0], 'attention_mask': batch[1], 'token_type_ids': batch[2]}
inputs_b = {'input_ids': batch[3], 'attention_mask': batch[4], 'token_type_ids': batch[5]}
labels = paddle.squeeze(batch[6])
inputs = []
inputs.append(inputs_a)
inputs.append(inputs_b)
output = model(inputs)
pred = paddle.argmax(output, axis=1)
correct = (labels == pred).sum()
total_correct += correct
total += labels.shape[0]
loss = F.cross_entropy(output, labels)
pbar(step, {'loss': loss.item()})
acc = total_correct / total
return acc
def main():
args =parse_args()
train(args)
if __name__ == '__main__':
main()
三、效果对比
直接看看模型训练的时间和准确率(更科学一点的应该是采用F1值召回率等等)
torch结果
torch的训练时间和准确率如下图
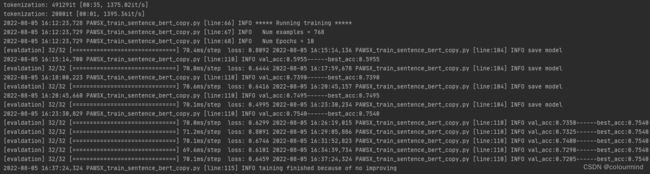
paddle目前框架有问题,设置随机种子不生效,导致结果不可复现,每次训练结果乱飞(0.65-0.68之间),尝试如下设置后,均没有效果
paddle.seed(100) random.seed(100) np.random.seed(100)FLAGS_cudnn_deterministic = True python train....
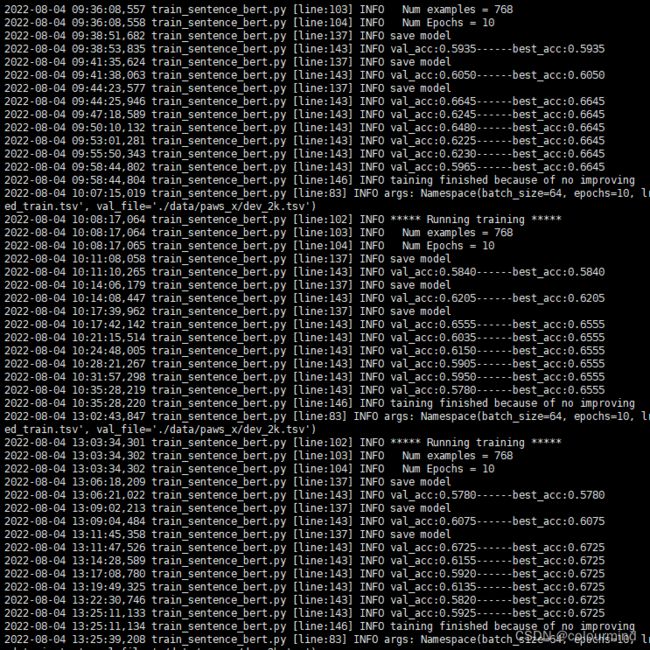
需要等官方提供解决办法,看来paddle还是有很多bug呀,白开心一场呀。。。至于后续的对比就没有啥意义了;后面再来修改这篇博客吧
和paddle官方沟通情况