目标检测论文阶段性总结——one-stage系列
目录
SSD
主要思想
要点
1. default box (anchor)
2. Multiple Feature Maps
缺陷
YOLO
主要思想
要点
1. one-stage object detection(首个)
2. grid cell
3. 损失函数
缺陷
YOLO V2
改进(针对YOLO V1)
1. Batch Normalization
2. High Resolution Classifier
3. Anchor Boxes
4. Dimension Clusters
5. Direct location prediction
6. Passthrough Layer
7. Multi-Scale Training
8. Simplify the Network
YOLO V3
改进(针对YOLO V2)
1. 损失函数
2. FPN + Residual
缺陷
SSD
主要思想
将bounding boxes的输出空间,离散为不同尺度特征图各个位置上一组不同尺度和宽高比的default boxes(anchors)。
要点
1. default box (anchor)
针对每个default box,预测目标类别,并输出offset调整预测框。
SSD给每个预测特征层上各位置都分配了default boxes,输出的预测框offset是针对default box而言的。假设某特征层上的各位置有k个default boxes,每个box输出 c(包含背景类别c0)个class score,以及4个定位offset,则每个位置共需要 (c+4)k 个filters。
【注】R-CNN系列的回归器是 class-specific 的;而SSD的回归器不关注default box所属的类别。
2. Multiple Feature Maps
SSD 结合不同尺度的feature map的预测结果。
大feature map预测小目标;小feature map预测大目标。
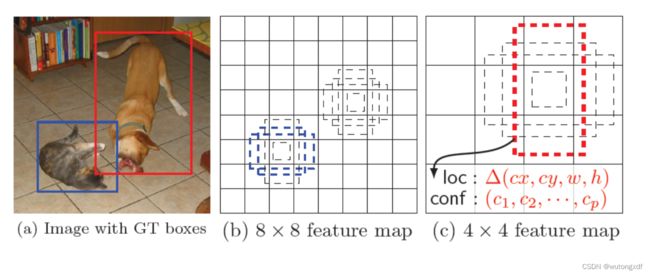
缺陷
1. 需要手动设置default box的尺度和宽高比。
2. 对小目标的检测性能不佳。
YOLO
主要思想
将目标检测当做回归任务,将整张图像直接输入网络,进行端到端的优化。
把原始图片resize成固定尺寸(448×448)→ 将图像输入CNN进行预测 → 进行NMS后处理
要点
1. one-stage object detection(首个)
YOLO将整张图像直接输入网络,使用图像的全局信息做预测,学习到的特征更加通用。
2. grid cell

YOLO将输入图片分割成 S×S 个grid cell,目标的中心落在哪个cell,就由该cell负责预测那个目标。每个grid cell 预测 B 个bounding boxes,以及 C 个条件类别概率 Pr(Classi | object)(已知是目标的条件下,是第i个类别的概率);每个bounding box 输出 (x,y,w,h)4个坐标 以及 1个confidence(置信度) score :Pr(object)*IOU。
测试时,Pr(Classi | object)*Pr(object)*IOU = Pr(Classi)*IOU,得到第i个类别的confidence score,可以用于过滤bounding box。
YOLO 输出 S×S×(B*5+C)的tensor。
【注】confidence score包含两部分内容:判断为目标的自信程度(不分类别)+ bounding box定位的准确程度。预测时,YOLO并不会分别给出Pr(object)和IOU,而是直接给出confidence score。
3. 损失函数
采用 sum-squared error(误差平方和)损失。

缺陷
召回率低,定位性能不佳,尤其对于小目标和密集目标,原因包括:
1. 最多只能生成 7×7×2=98个 boudning box,每一个cell 给出的2个bounding box只能属于同一个类别,且只选其中IOU最大的一个来预测目标(因此漏检多,误检少);
2. 只在一个尺度的feature map上进行预测,丢失底层特征;
3. 没有使用anchor,而是让模型直接预测bounding box的坐标,难度较大。
YOLO V2
改进(针对YOLO V1)
1. Batch Normalization
BN将神经元输出压缩到激活函数的非饱和区,加快收敛。
2. High Resolution Classifier
进行分类预训练时就使用448×448的图像提升分辨率(YOLO V1用224×224分辨率的图像在分类器上预训练,训练检测任务时将分辨率提升至448×448)。
3. Anchor Boxes
YOLO V1直接预测bounding box的坐标,V2借鉴Faster R-CNN 的anchor机制,在anchor(先验框)的基础上输出offset,使得网络更易学习。
4. Dimension Clusters
改进Faster R-CNN、SSD人工提取anchor box的做法,采用k-means聚类的方法,自动选择更好的先验框。
5. Direct location prediction
Faster R-CNN、SSD中回归器预测的目标中心点offset是相对于anchor而言的,且取值不受任何约束,因此预测框中心可能出现在图像的任意位置;YOLO V2预测的offset是相对于grid cell 左上角位置而言的,经过sigmoid激活,将预测边界框的中心限制在当前cell中。
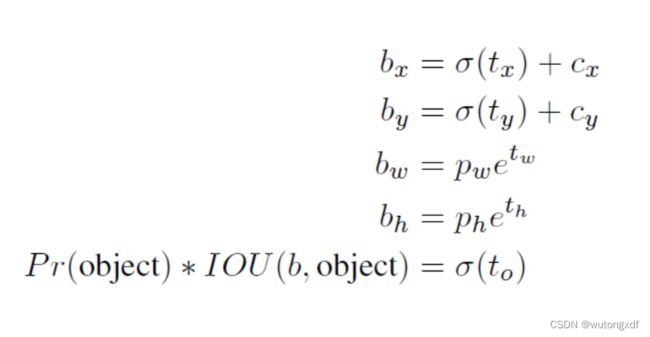

【注】V1直接预测 confidence score;V2则是预测 t0,再计算 σ(t0) 作为confidence score。
6. Passthrough Layer
引入passthrough layer,结合更底层的特征信息。
7. Multi-Scale Training
训练时,每10个batch就随机更新输入图像的像素值大小,增强网络对于不同像素图像的鲁棒性,并产生某种程度上的数据增强效果。
8. Simplify the Network
采用 Darknet-19作为骨干网络,共用19个卷积层,只需计算19层参数,使得模型更加简洁。并且加入了全局平均池化层,使得YOLO V2可以输入任意尺度的图像。
YOLO V3
改进(针对YOLO V2)
1. 损失函数
1)样本选择
只有正样本对分类和定位损失产生贡献;负样本只影响置信度损失。
正例:与GT的IOU最大的先验框,每个GT只分配一个prior(不同于Faster R-CNN),即有几个GT就有几个正例;
负例:与GT的IOU<0.5的先验框;
忽略:与GT的IOU>0.5且非最大的先验框。
2)定位
采用sum of squared error loss,即 ∑(标签值-预测值)²。
3)置信度
采用logistic regression计算置信度(BCE)。与ground truth(GT)中心点对齐后IOU最大的anchor负责拟合该GT,且置信度为1(在V1/V2中,正样本bounding box的置信度为与GT的IOU)。
4)分类
将多分类任务当做多个二分类任务,彼此之间非互斥。每个预测框对各个类别逐一使用logistic regression(BCE)输出概率,允许多个类别输出高概率。
2. FPN + Residual
YOLO V3 引入 FPN 和 Residual blocks, 融合不同尺度的特征,在三个尺度的feature map上分别进行预测。
针对COCO数据集(80个类别),YOLO V3 的每个预测特征层输出 N×N×[3*(4+1+80)] 的tensor,其中 N 为特征层尺度,每个位置有3个不同尺度的先验框,4 代表bounding box offset,1 代表 objectness/confidence。
缺陷
定位性能依然不佳,其中小目标定位性能增强,中、大尺寸目标定位性能下降。