【读论文】TCPMFNet
【读论文】TCPMFNet
- 简单介绍
- 网络结构
-
- 编码器
- 图像融合网络
-
- Vision Transformer
- 特征融合网络
- 网格连接解码器
- 损失函数
- 总结
- 参考
论文:https://www.sciencedirect.com/science/article/pii/S1350449522003863
如有侵权请联系博主
简单介绍
今天要介绍的是TCPMFNet,这篇论文中提出的红外图像融合方法结合了vision transformer,这也是我第一次接触到这个知识,接下来,我们一起看看这篇论文吧。
网络结构
老样子,咱们先看下整个网络的架构

看到这个结构,是不是觉得有点眼熟,和RFN-Nest有点相似,那样的话就和RFN-Nest对比来看吧。
整个架构简单来说,就是由三个部分组成,分别是编码器,特征融合器和解码器。其中编码器提取四个尺度的红外图像和可视图像特征,然后每个尺度的特征输入到对应的特征融合器中,然后输出的融合特征输入到解码器中生成最终的融合图像。接下来我们拆开整个网络架构,一部分一部分去讲。
编码器
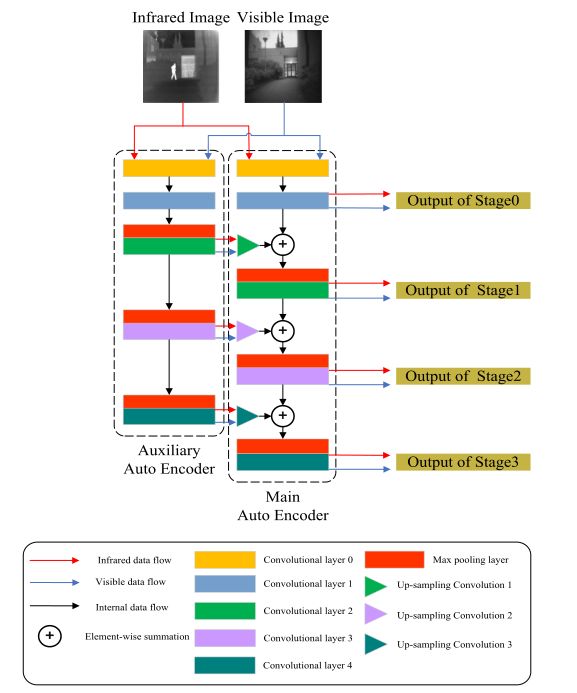
编码器的架构如上图所示,可以看到很有趣的是这里有两个编码器,并且两个编码器之间还存在数据的传输,作者将这两个编码器命名为主自动编码器(图右)和辅助自动编码器(图左),两个编码器共享相同的网络结构和参数配置。
观察下上图中解码器的结构,你会发现每个解码器有五层,从第二层开始,分别为stage0,stage1,stage2,stage3,并且除了stage0以外,主编码器的每一个stage的输入都包含辅助编码器的输出,即stage1的输入为主编码器stage0的输出和辅助编码器的stage1的输出进行上采样(在经过了最大池化和卷积之后特征矩阵的大小发生了变化,因此需要将辅助编码器的stage1的输出上采样至与主编码器中的stage0的输出相同的大小)之后的结果相加所得。
那么为什么要介绍这个东西呢?
这就是为了理解下面这个公式更方便
![]()
MSFIN是主编码器stagei+1的输入,MSFO是主编码器stagei的输出,ASFO是stagei+1的输出,其中UP是上采样操作,Conv是卷积操作,结合上面的内容,再去理解这个就很简单了。
那么为什么要设计这样的网络结构呢?相比于单个解码器这样的优势在哪里?
看下作者的解释
将来自辅助自动编码器的特征图与来自主自动编码器的特性图融合,可以使提取的源图像特征分布到更多的通道中,从而提高特征提取的性能。
如下图,可以明显看出紫色圆圈标注的特征图中的特征信息,更多一些,仔细看我们又会发现,主编码器中的通道24的红外特征和可视特征都比较差,但是通道56中的两种特征都保留的很好,再看辅助编码器,你会发现恰恰相反,这就直接互补了,二者相加可以更好的保留特征信息,这就是为什么要采用这个结构的原因。

图像融合网络
Vision Transformer
博主认为整个架构最重要的一个部分,也是让我收获最大的一部分内容,接下来我们一起来看看吧。
要看这个部分的话,首先我们需要了解下什么是vision transformer
来看下图,这是vision transformer原论文中的给出的网络结构,看着好像不是很复杂,抛开事实不谈的话,确实是这样的。
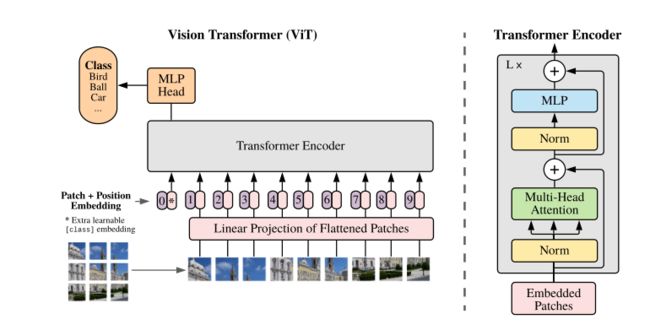
首先我们先看左半部分,这是整个vision transformer的总体架构。回忆下transformer,最原始的transformer是用于自然语言处理,每个词都作为一个向量作为整个网络的输入,但是这里我们输入的是一个3维的数据(三通道数据),这就很难在采用之前使用的输入方式,否则会导致参数量过大。
这时就有大佬提出了VIT,那么他是怎么做的呢,来继续往下看。
第一步就是将图片分成多个patch,然后再将这多个patch经过一系列操作转换为多个一维的数据,然后才输入到transformer中进行处理,也就是下图红框部分中执行的操作,这个操作应该怎么做呢?

我们来仔细说下这个过程,第一件事我们需要将整个图像划分为多个块,上图就是直接划分成了9个块,然后这9个块进入到linear Projection of Flattened Patches(就是一个全连接层)然后又得到了9个输出,这9个输出已经是一维的向量,然后再与位置编码相加即可,就得到了transformer所需要的输入。
那么这个过程可以怎么实现呢?
我们可以直接使用卷积操作来实现上面这一个复杂的过程,这里拿一个尺寸比较小的图片来举例,我们有一个9x9x3的图像数据(只是举例,一般不会这么小),此时我们只需要设置卷积核大小为3,步长为3,卷积核数量为9,在整个图像中进行卷积即可,卷积之后就会得到3x3x9的数据,这时再将3x3平铺为维数为9的向量即可,这样我们就得到了长度为9,维数也为9的一组token,就成功的将2D的图像数据转换位1D的数据。此时在进行transformer的正常操作即可,即每一个token再加上位置编码(1D的位置编码),之后的操作就与transformer一致了,可以注意到这里还多一个位置编码0的toekn,可以使用这个token对应的输出来实现分类操作。
同理,当我们对一个224x224大小的图片进行操作时,设置每一个patch为16时,我们只需要将卷积核大小设置为16,步长设置为16,卷积核数量设置为196即可。
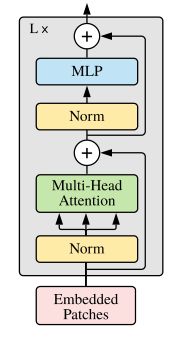
在了解了怎么将图像数据转换为transformer可以接收的数据,这里我们再讲一下transformer encoder中都进行了哪些工作。
如下图所示,可以看到整个架构其实很简单,我们重点讲一下这里的Multi-Head Attention,也就是多头注意力机制。
首先我们先了解下transformer的注意力机制是什么?来看下这个公式

单看的话,特别的抽象,我们来一个个拆分一下。简单来看的话,整个公式就是由三部分组成,分别是Q,K和V,那么可以怎么理解这三个东西呢?
以现在大火的选秀为例,我们可以认为Q是一个评价标准(评价唱跳能力等等),K是你个人的唱跳能力,V是你的基础得分,当你的唱跳能力K符合评价标准Q,你的最终得分就会越高。
具体计算起来又会是怎样的一个过程呢?我们继续看一下
如下图,这里的q和k都是向量,这样我们就得到了Q和K的转置计算后的结果,这个矩阵的意义是什么呢?

观察上面的矩阵,以第一行为例,每一个数据都是q1与k进行计算的结果,是不是就代表第一行的数据其实就是q1与所有k的匹配程度,同理其他行也是如此,接下来在进行一步计算(这里没有进行softmax处理,大家自行带入下),如下图

观察最终结果,你会发现v1,v2和v3的值已经不再是由它本身决定了,而是由v1,v2和v3三个的值共同决定,而每个值所占的权重就与q与k的相关程度有关。
每一个值在经过注意力之后都会受到所有值的影响,这一点在图像里有什么用途呢?稍后我们就会与论文内容相结合一起说说这个点。
那么多头又是什么意思呢?
简单来说就是将原来的Q,K和V在维度上分成了多分,例如三者都是24维的,采用4头注意力,此时每一个部分的输入数据就是6维的,在计算得到最终结果之后再将这多个结果连接起来就是最终的结果了。
那么为什么要用多头呢?
回顾一下,你会发现,整个计算过程中都是固定,当要做不同的工作时,怎么让网络去学习呢?这个的答案就是为什么要使用多头注意力
先看下transformer原论文中多头注意力的公式

可以很清晰的看到QKV都是乘了一个W,这个W是可以学习的,也就可以应对不同的工作。
讲了这么多接下来我们就可以开始看论文的内容了。

特征融合网络

整个网络比较简单,从下而上,首先是一个卷积层,这个卷积层的作用应该和我们之前提到的将图片数据转换为一维数据的卷积层的功能是相同的,即使用卷积对整个图片进行卷积,然后将得到的结果的前两维铺平。
之后就是将卷积层的输出复制为三份,分别作为QKV,输入到multi-head attention(多头注意力)中,其中进行的操作可参考前文内容,multi-head attention的输出再与multi-head attention的输入进行相加,在输入到最后一层(mlp)中,然后最后一个mlp的输出再与其输入相加,就是最终的融合特征结果。
这部分的公式如下,Res就是进行一个残差连接,ATT代表multi-head attention的输出,TFO为最终的输出。
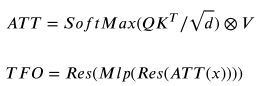
了解完结构之后,你可能会有个疑问,为什么要使用VIT,而不是继续使用CNN?
这时我们再回忆下,前文中提到了,经过transformer之后的输出的每个token中包含了所有的token的信息,代入到VIT这边,每一个token包含图片中一个patch的信息,在经过处理之后,是不是就代表每个处理后的token就有了整张图片的信息, 而CNN获取的信息范围一般是局限在卷积核大小,二者就有很明显的区别了,即CNN适用获取局部信息,而VIT可以获取全局信息,二者各有优势,例如在本文中,虽然说VIT可以很好的获取全局信息,但是在局部的一些处理不如CNN,因此作者采用二者相结合的方式,这就是最终的融合网络架构,如下图

网络中有三条融合路径,分别是卷积融合路径,transformer 融合路径和混合路径。
来看下公式

很清晰,Conv是卷积操作,TFO是Transformer,CFPO是卷积路径的结果,TFPO是transformer路径的结果,MPO是混合路径的结果,FM是最终的结果。
这里我有个疑问,在我的认知里,VIT输出的token如果直接与卷积的结果进行相加,是不是还需要将token的维数转换下?
网格连接解码器

解码器相对来说就比较简单了,四个尺度的融合特征作为输入,然后再网络进行上采样,下采样,同时作为不同卷积节点的输入,然后最终汇总到一个C2,0,在经过一个Final_conv也就是最终的结果。
具体的配置可以看下原文,这里就不做多余的描述了。
损失函数
整体的损失函数如下,Ld为细节损失函数,Lf为特征损失函数。![]()
细节损失函数相对简单,还是我们的老朋友SSIM。
![]()
看一下特征损失函数,这里Ff是融合特征,m是第几个尺度的特征,Fvi是可视特征,Fir是红外特征
来看Lf,作者将β1设置为0.6,β2设置为0.4,这样设置的原因我认为和RFN中应该大致相似,因为Ld已经倾向于保留可是图像的特征,Lf要同时保证红外特征和可视特征尽可能的保留,但鉴于Ld已经有益于可视特征的保留,因此这里将参数设置偏向于保留红外特征。最终的Lf是多个尺度的特征损失相加而得,这也是挺有趣的一个地方。
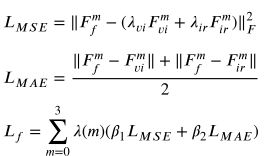
总结
之后的训练和消融实验就不整理,这篇论文真的帮我打开了一个新世界的大门,第一次接触到VIT相关的知识,以上关于VIT的总结多是看完沐神的transformer之后的体会,有错误的地方希望大佬们指点。
其他融合图像论文解读
读论文专栏,快来点我呀
【读论文】DIVFusion: Darkness-free infrared and visible image fusion
【读论文】RFN-Nest: An end-to-end residual fusion network for infrared and visible images
【读论文】DDcGAN
【读论文】Self-supervised feature adaption for infrared and visible image fusion
【读论文】FusionGAN: A generative adversarial network for infrared and visible image fusion
【读论文】DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
【读论文】DenseFuse: A Fusion Approach to Infrared and Visible Images
参考
[1] TCPMFNet: An infrared and visible image fusion network with composite auto encoder and transformer–convolutional parallel mixed fusion strategy
[2] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
[3] Attention Is All Y ou Need