LESSON 11.1&11.2&11.3 Boosting的基本思想与基本元素&AdaBoost的参数:弱评估器与学习率&AdaBoost的参数(下):实践算法与损失函数
目录
一 Boosting方法的基本思想
1 Bagging pk Boosting
2 Boosting算法的基本元素与基本流程
3 sklearn中的boosting算法
二 AdaBoost
1 AdaBoost的基本参数与损失函数
1.1 n_estimators
1.2 learning_rate
1.3 algorithm与loss
2 原理进阶:Adaboost回归的求解流程
一 Boosting方法的基本思想
在集成学习的“弱分类器集成”领域,除了降低方差来降低整体泛化误差的装袋法Bagging,还有专注于降低整体偏差来降低泛化误差的提升法Boosting(损失函数越来越小、准确率越来越高,模型效果越来越好)。相比起操作简单、大道至简的Bagging算法,Boosting算法在操作和原理上的难度都更大,但由于专注于偏差降低,Boosting算法们在模型效果方面的突出表现制霸整个弱分类器集成的领域。当代知名的Boosting算法当中,Xgboost,LightGBM与Catboost都是机器学习领域最强大的强学习器,Boosting毫无疑问是当代机器学习领域最具统治力的算法领域。
- Boosting PK Bagging
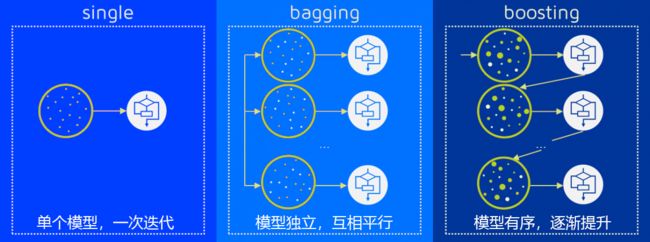
在以随机森林为代表的Bagging算法中,我们一次性建立多个平行独立的弱评估器,并让所有评估器并行运算。在Boosting集成算法当中,我们逐一建立多个弱评估器(基本是决策树),并且下一个弱评估器的建立方式依赖于上一个弱评估器的评估结果,最终综合多个弱评估器的结果进行输出,因此Boosting算法中的弱评估器之间不仅不是相互独立的、反而是强相关的,同时Boosting算法也不依赖于弱分类器之间的独立性来提升结果,这是Boosting与Bagging的一大差别。如果说Bagging不同算法之间的核心区别在于靠以不同方式实现“独立性”(随机性),那Boosting的不同算法之间的核心区别就在于上一个弱评估器的评估结果具体如何影响下一个弱评估器的建立过程。
与Bagging算法中统一的回归求平均、分类少数服从多数的输出不同,Boosting算法在结果输出方面表现得十分多样。早期的Boosting算法的输出一般是最后一个弱评估器的输出,当代Boosting算法的输出都会考虑整个集成模型中全部的弱评估器。一般来说,每个Boosting算法会其以独特的规则自定义集成输出的具体形式,但对大部分算法而言,集成算法的输出结果往往是关于弱评估器的某种结果的加权平均,其中权重的求解是boosting领域中非常关键的步骤。
- Boosting算法的基本元素与基本流程
基于上面所明确的“降低偏差”、“逐一建树”、以及“以独特规则输出结果”的三大特色,我们可以确立任意boosting算法的三大基本元素以及boosting算法自适应建模的基本流程:
- 损失函数(,):用以衡量模型预测结果与真实结果的差异
- 弱评估器() :(一般为)决策树,不同的boosting算法使用不同的建树过程
- 综合集成结果():即集成算法具体如何输出集成结果
这三大元素将会贯穿所有我们即将学习的boosting算法,我们会发现几乎所有boosting算法的原理都围绕这三大元素构建。在此三大要素基础上,所有boosting算法都遵循以下流程进行建模:

正如之前所言,Boosting算法之间的不同之处就在于使用不同的方式来影响后续评估器的构建。无论boosting算法表现出复杂或简单的流程,其核心思想一定是围绕上面这个流程不变的。
- sklearn中的boosting算法
在sklearn当中,我们可以接触到数个Boosting集成算法,包括Boosting入门算法AdaBoost,性能最稳定、奠定了整个Boosting效果基础的梯度提升树GBDT(Gradient Boosting Decision Tree),以及近几年才逐渐被验证有效的直方提升树(Hist Gradient Boosting Tree)。
在过去5年之间,除了sklearn,研究者们还创造了大量基于GBDT进行改造的提升类算法,这些算法大多需要从第三方库进行调用,例如极限提升树XGBoost(Extreme Gradient Boosting Tree),轻量梯度提升树LightGBM(Light Gradiant Boosting Machine),以及离散提升树CatBoost(Categorial Boosting Tree)。
在课程当中,我们会一一介绍以上所有算法的原理与用法。另外需要注意的是,周志华老师于2017年提出的深度森林算法既不是boosting也不是bagging,而是以深度学习的思路重新集成决策树之后得到的独特算法,可以算是模型融合的一部分。
二 AdaBoost
AdaBoost(Adaptive Boosting,自适应提升法)是当代boosting领域的开山鼻祖,它虽然不是首个实践boosting思想算法,却是首个成功将boosting思想发扬光大的算法。它的主要贡献在于实现了两个变化:
1、首次实现根据之前弱评估器的结果自适应地影响后续建模过程
2、在Boosting算法中,首次实现考虑全部弱评估器结果的输出方式
作为开山算法,AdaBoost的构筑过程非常简单:首先,在全样本上建立一棵决策树,根据该决策树预测的结果和损失函数值,增加被预测错误的样本在数据集中的样本权重,并让加权后的数据集被用于训练下一棵决策树。这个过程相当于有意地加重“难以被分类正确的样本”的权重,同时降低“容易被分类正确的样本”的权重,而将后续要建立的弱评估器的注意力引导到难以被分类正确的样本上。

在该过程中,上一棵决策树的的结果通过影响样本权重、即影响数据分布来影响下一棵决策树的建立,整个过程是自适应的。当全部弱评估器都被建立后,集成算法的输出()等于所有弱评估器输出值的加权平均,加权所用的权重也是在建树过程中被自适应地计算出来的。
需要注意的是,虽然最初的原理较为简单,但近年来AdaBoost在已经发展出多个升级的版本(比如,在建立每棵树之前,允许随机抽样特征,这使得Boosting中的决策树行为更加接近Bagging中的决策树),而sklearn中使用了这些升级后的版本进行实现。幸运的是,这些实现并不影响我们对sklearn中的类的使用,对这些实现的具体过程感兴趣的小伙伴,可以在章节《2 原理进阶:AdaBoost的求解流程》中查看具体原理。
在sklearn中,AdaBoost既可以实现分类也可以实现回归,我们使用如下两个类来调用它们:
class sklearn.ensemble.AdaBoostClassifier(base_estimator=None, *, n_estimators=50, learning_rate=1.0, algorithm=‘SAMME.R’, random_state=None)
class sklearn.ensemble.AdaBoostRegressor(base_estimator=None, *, n_estimators=50, learning_rate=1.0, loss=‘linear’, random_state=None)
不难发现,AdaBoost的参数非常非常少,在调用AdaBoost时我们甚至无需理解AdaBoost的具体求解过程。同时,ADB分类器与ADB回归器的参数也高度一致。在课程当中,我们将重点Boosting算法独有的参数,以及ADB分类与ADB回归中表现不一致的参数。
1 AdaBoost的基本参数与损失函数
from sklearn.ensemble import AdaBoostClassifier as ABC
from sklearn.ensemble import AdaBoostRegressor as ABR
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.tree import DecisionTreeRegressor as DTR
from sklearn.datasets import load_digits
#用于分类的数据
data_c = load_digits()
X_c = data_c.data
y_c = data_c.target
X_c.shape
#(1797, 64)
X_c
#array([[ 0., 0., 5., ..., 0., 0., 0.],
# [ 0., 0., 0., ..., 10., 0., 0.],
# [ 0., 0., 0., ..., 16., 9., 0.],
# ...,
# [ 0., 0., 1., ..., 6., 0., 0.],
# [ 0., 0., 2., ..., 12., 0., 0.],
# [ 0., 0., 10., ..., 12., 1., 0.]])
np.unique(y_c) #手写数字数据集,10分类
#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
#用于回归的数据
data_r = pd.read_csv(r"D:\Pythonwork\2021ML\PART 2 Ensembles\datasets\House Price\train_encode.csv",index_col=0)
X_g = data_r.iloc[:,:-1]
y_g = data_r.iloc[:,-1]
X_g.shape
#(1460, 80)
X_g.head()

- 参数base_estimator,属性base_estimator_与estimators_
base_estimator是规定AdaBoost中使用弱评估器的参数。与对弱评估器有严格要求的Bagging算法不同,boosting算法通过降低偏差来降低整体泛化误差,因此可以使用任意弱评估器,且这些弱评估器往往被假设成非常弱小的评估器。当然了,默认的弱评估器还是决策树。在sklearn中,ADB分类器的默认弱评估器是最大深度为1的“树桩”,ADB回归器的默认评估器是最大深度为3的“树苗”,弱评估器本身基本不具备判断能力。而回归器中树深更深是因为boosting算法中回归任务往往更加复杂。在传统ADB理论当中,一般认为AdaBoost中的弱分类器为最大深度为1的树桩,但现在我们也可以自定义某种弱评估器来进行输入。
当模型建好之后,我们可以使用属性base_estimator_来查看当前弱评估器,同时也可以使用estimators_来查看当前集成模型中所有弱评估器的情况:
- 建立集成算法,调用其中的弱评估器
#建立ADB回归器和分类器
clf = ABC(n_estimators=3).fit(X_c,y_c)
reg = ABR(n_estimators=3).fit(X_g,y_g)
clf.base_estimator_
#DecisionTreeClassifier(max_depth=1)
reg.base_estimator_
#DecisionTreeRegressor(max_depth=3)
reg.estimators_
#[DecisionTreeRegressor(max_depth=3, random_state=765348147),
# DecisionTreeRegressor(max_depth=3, random_state=850911835),
# DecisionTreeRegressor(max_depth=3, random_state=1434155639)]
当AdaBoost完成分类任务时,弱评估器是分类树,当AdaBoost完成回归任务时,弱评估器是回归树,这一点与之后的Boosting算法们有较大的区别。
- 自建弱评估器
base_estimator = DTC(max_depth=10,max_features=30)
clf = ABC(base_estimator = base_estimator, n_estimators=3).fit(X_c,y_c)
clf.base_estimator_
#DecisionTreeClassifier(max_depth=10, max_features=30)
clf.estimators_
#[DecisionTreeClassifier(max_depth=10, max_features=30, random_state=814836020),
# DecisionTreeClassifier(max_depth=10, max_features=30, random_state=880262373),
# DecisionTreeClassifier(max_depth=10, max_features=30, random_state=925249775)]
注意,为了保证集成算法中的树不一致,AdaBoost会默认消除我们填写在弱评估器中的random_state:
base_estimator = DTC(max_depth=10,max_features=30,random_state=1412)
clf = ABC(base_estimator = base_estimator, n_estimators=3).fit(X_c,y_c)
clf.estimators_
#[DecisionTreeClassifier(max_depth=10, max_features=30, random_state=677195652),
# DecisionTreeClassifier(max_depth=10, max_features=30, random_state=1650391099),
# DecisionTreeClassifier(max_depth=10, max_features=30, random_state=672741048)]
- 参数learning_rate
在Boosting集成方法中,集成算法的输出 H ( x ) H(x) H(x)往往都是多个弱评估器的输出结果的加权平均结果。但 H ( x ) H(x) H(x)并不是在所有树建好之后才统一加权求解的,而是在算法逐渐建树的过程当中就随着迭代不断计算出来的。例如,对于样本 x i x_i xi,集成算法当中一共有 T T T棵树(也就是参数n_estimators的取值),现在正在建立第 t t t个弱评估器,则第 t t t个弱评估器上 x i x_i xi的结果可以表示为 f t ( x i ) f_t(x_i) ft(xi)。假设整个Boosting算法对样本 x i x_i xi输出的结果为 H ( x i ) H(x_i) H(xi),则该结果一般可以被表示为t=1~t=T过程当中,所有弱评估器结果的加权求和:
H ( x i ) = ∑ t = 1 T ϕ t f t ( x i ) H(x_i) = \sum_{t=1}^T\phi_tf_t(x_i) H(xi)=t=1∑Tϕtft(xi)
其中, ϕ t \phi_t ϕt为第t棵树的权重。对于第 t t t次迭代来说,则有:
H t ( x i ) = H t − 1 ( x i ) + ϕ t f t ( x i ) H_t(x_i) = H_{t-1}(x_i) + \phi_tf_t(x_i) Ht(xi)=Ht−1(xi)+ϕtft(xi)
在这个一般过程中,每次将本轮建好的决策树加入之前的建树结果时,可以在权重 ϕ \phi ϕ前面增加参数 η \color{red}\eta η,表示为第t棵树加入整体集成算法时的学习率,对标参数learning_rate。
H t ( x i ) = H t − 1 ( x i ) + η ϕ t f t ( x i ) H_t(x_i) = H_{t-1}(x_i) + \boldsymbol{\color{red}\eta} \phi_tf_t(x_i) Ht(xi)=Ht−1(xi)+ηϕtft(xi)
该学习率参数控制Boosting集成过程中 H ( x i ) H(x_i) H(xi)的增长速度,是相当关键的参数。当学习率很大时, H ( x i ) H(x_i) H(xi)增长得更快,我们所需的n_estimators更少,当学习率较小时, H ( x i ) H(x_i) H(xi)增长较慢,我们所需的n_estimators就更多,因此boosting算法往往会需要在n_estimators与learning_rate当中做出权衡(以XGBoost算法为例)。
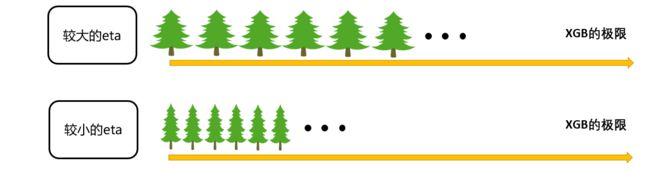
需要注意的是,以上式子为boosting算法中计算方式的一般规则,并不是具体到AdaBoost或任意Boosting集成算法的具体公式。
- 参数
algorithm与loss
参数algorithm与loss是boosting算法中非常常见的,分类器与回归器展示出不同参数的情况。正如之前提到的,虽然AdaBoost算法的原理简单,但是在近几年已经发展出了多种不同的算法实践手段,而参数algorithm与loss正是用来控制算法实践手段的关键参数,其中algorithm控制具体的实践算法,loss控制该实践算法中所使用的具体损失函数。
algorithm
首先,参数algorithm是针对分类器设置的参数,其中备选项有"SAMME"与"SAMME.R"两个字符串。这两个字符串分别代表了两种不同的、实现AdaBoost分类的手段:AdaBoost-SAMME与AdaBoost-SAMME.R。两者在数学流程上的区别并不大,只不过SAMME是基于算法输出的具体分类结果(例如-1,1,2)进行计算,而SAMME.R则是在SAMME基础上改进过后、基于弱分配器输出的概率值进行计算,两种方法都支持在AdaBoost上完成多分类任务,但SAMME.R往往能够得到更好的结果,因此sklearn中的默认值是SAMME.R,因此**sklearn中默认可以输入的base_estimators也需要是能够输出预测概率的弱评估器。实际在预测时,AdaBoost输出的 H ( x ) H(x) H(x)也针对于某一类别的概率**。
需要注意的是,在分类器中,我们虽然被允许选择算法,却不被允许选择算法所使用的损失函数,这是因为SAMME与SAMME.R使用了相同的损失函数:二分类指数损失(Exponential Loss Function)与多分类指数损失(Multi-class Exponential loss function)。
二分类指数损失——
L ( H ( x ) , y ) = e − y H ∗ ( x ) L(H(x),y) = e^{-yH^*(x)} L(H(x),y)=e−yH∗(x)其中y为真实分类, H ∗ ( x ) H^*(x) H∗(x)则是从集成算法输出的概率结果 H ( x ) H(x) H(x)转换来的向量。转换规则如下:
H ∗ ( x ) = { 1 i f H ( x ) > 0.5 − 1 i f H ( x ) < 0.5 H^*(x)= \begin{cases} 1& if \ H(x)>0.5 \\ -1& if\ H(x) < 0.5 \end{cases} H∗(x)={1−1if H(x)>0.5if H(x)<0.5
在sklearn当中,由于 H ( x ) H(x) H(x)是概率值,因此需要转换为 H ∗ ( x ) H^*(x) H∗(x),如果在其他实现AdaBoost的算法库中, H ( x ) H(x) H(x)输出直接为预测类别,则可以不执行转换流程。
根据指数损失的特殊性质,二分类状况下的类别取值只能为-1或1,因此 y y y的取值只能为-1或1。当算法预测正确时, y H ∗ ( x ) yH^*(x) yH∗(x)的符号为正,则在函数 e − x e^{-x} e−x上损失很小。当算法预测错误时, y H ∗ ( x ) yH^*(x) yH∗(x)的符号为负,则在函数 e − x e^{-x} e−x上损失较大。二分类指数损失是AdaBoost最经典的损失函数,它在数学推导上的有效性以及在实践过程中很强的指导性让其沿用至今。

多分类指数损失——
L ( H ( x ) , y ) = e x p ( − 1 K y ∗ ⋅ H ∗ ( x ) ) = e x p ( − 1 K ( y ∗ 1 H ∗ 1 ( x ) + y ∗ 2 H ∗ 2 ( x ) + . . . + y ∗ k H ∗ k ( x ) ) ) \begin{aligned} L(H(x),y) &=exp \left( -\frac{1}{K}\boldsymbol{y^* · H^*(x)} \right) \\ & = exp \left( -\frac{1}{K}(y^{*1}H^{*1}(x)+y^{*2}H^{*2}(x) \ + \ ... + y^{*k}H^{*k}(x)) \right) \end{aligned} L(H(x),y)=exp(−K1y∗⋅H∗(x))=exp(−K1(y∗1H∗1(x)+y∗2H∗2(x) + ...+y∗kH∗k(x)))
其中, K K K为总类别数,如四分类[0,1,2,3]的情况时, K = 4 K=4 K=4, y ∗ \boldsymbol{y^*} y∗与 H ∗ ( x ) \boldsymbol{H^*(x)} H∗(x)都是根据多分类具体情况、以及集成算法实际输出 H ( x ) H(x) H(x)转化出的向量,其中 y ∗ 1 y^{*1} y∗1与 H ∗ 1 ( x ) H^{*1}(x) H∗1(x)的上标1都表示当前类别。
在二分类算法中,算法会直接针对二分类中的其中一个类别输出概率,因为在二分类中 P ( Y = 1 ) = 1 − P ( Y = − 1 ) P(Y=1) = 1 - P(Y=-1) P(Y=1)=1−P(Y=−1),所以只计算出一类的概率即可判断预测的标签。但在多分类算法中,算法必须针对所有可能的取值类型都输出概率,才能够从中找出最大概率所对应的预测标签。因此在集成算法中,我们对进行多分类预测时,会得到如下的表格:
#多分类预测
clf = DTC(max_depth=2).fit(X_c,y_c)
#多分类预测输出的概率结果,取前5个样本
pd.DataFrame(clf.predict_proba(X_c)).iloc[:5,:]
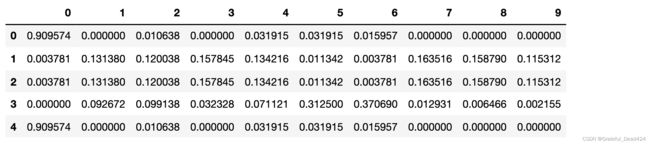
每一行对应一个样本,每一列则对应该样本的预测标签为某一类别的概率,以上表格就是5个样本在10分类情况下得出的概率表格,而每一个样本的10个概率中,最大概率所对应的类别就是预测类别。而这一转换可以由函数argmax完成。argmax会取出最大值所对应的索引,刚好也就是最大概率所对应的预测标签。
np.argmax(pd.DataFrame(clf.predict_proba(X_c)).iloc[0,:])
#0
np.argmax(pd.DataFrame(clf.predict_proba(X_c)).iloc[1,:])
#7
np.argmax(pd.DataFrame(clf.predict_proba(X_c)).iloc[3,:])
#6
对一棵决策树我们会输出k个概率,对于boosting集成中的每一棵树,在任意样本上都会得到 f c = 0 ( x ) f^{c=0}(x) fc=0(x)、 f c = 1 ( x ) f^{c=1}(x) fc=1(x)、 f c = 2 ( x ) f^{c=2}(x) fc=2(x)……数个不同的结果。在集成算法当中,每个样本在第t次建树过程中,都会生成针对于不同类别的结果:
H t 0 ( x i ) = H t − 1 0 ( x i ) + ϕ t f t 0 ( x i ) H_{t}^0(x_i) = H_{t-1}^0(x_i) + \phi_tf_t^0(x_i) Ht0(xi)=Ht−10(xi)+ϕtft0(xi) H t 1 ( x i ) = H t − 1 1 ( x i ) + ϕ t f t 1 ( x i ) H_{t}^1(x_i) = H_{t-1}^1(x_i) + \phi_tf_t^1(x_i) Ht1(xi)=Ht−11(xi)+ϕtft1(xi) H t 2 ( x i ) = H t − 1 2 ( x i ) + ϕ t f t 2 ( x i ) H_{t}^2(x_i) = H_{t-1}^2(x_i) + \phi_tf_t^2(x_i) Ht2(xi)=Ht−12(xi)+ϕtft2(xi) … … …… …… H t k ( x i ) = H t − 1 k ( x i ) + ϕ t f t k ( x i ) H_{t}^k(x_i) = H_{t-1}^k(x_i) + \phi_tf_t^k(x_i) Htk(xi)=Ht−1k(xi)+ϕtftk(xi)
因此,我们可以得到向量 [ H 0 ( x ) , H 1 ( x ) , H 2 ( x ) , . . . , H k ( x ) ] [H^0(x),H^1(x),H^2(x),...,H^k(x)] [H0(x),H1(x),H2(x),...,Hk(x)],表示当前集成算法计算出的、针对多个类别的概率(也是对全部弱分类器输出的、针对多个类别的概率进行的加权求和)。针对该向量,一定可以得到向量中的一个最大值,该最大值所对应的标签类别就是多分类算法中的预测标签类别。**根据该向量,以及指数损失的特性,我们规定:
H ∗ ( x ) = { 1 i f k = a r g m a x H ( x ) − 1 K − 1 i f k ≠ a r g m a x H ( x ) H^*(x)= \begin{cases} 1& if \ k = argmaxH(x) \\ -\frac{1}{K-1}& if\ k \neq argmaxH(x) \end{cases} H∗(x)={1−K−11if k=argmaxH(x)if k=argmaxH(x)
其中, a r g m a x H ( x ) argmaxH(x) argmaxH(x)对应的是预测标签, k k k为所有预选标签类别。因此,假设在4分类情况下,集成算法针对样本 i i i的各个分类输出的概率如下所示,则向量 H ∗ ( x ) \boldsymbol{H^*(x)} H∗(x)的取值如下所示:
| 0 0 0 | 1 1 1 | 2 2 2 | 3 3 3 | |
|---|---|---|---|---|
| H t k ( x i ) H_t^k(x_i) Htk(xi) | 0.1 0.1 0.1 | 0.2 0.2 0.2 | 0.2 0.2 0.2 | 0.5 0.5 0.5 |
| H ∗ ( x ) H^*(x) H∗(x) | − 1 3 -\frac{1}{3} −31 | − 1 3 -\frac{1}{3} −31 | − 1 3 -\frac{1}{3} −31 | 1 1 1 |
其中3就是当前集成算法针对样本 i i i预测的标签。
另外一方面, y ∗ \boldsymbol{y^*} y∗一般来说都是真实标签经过上述处理后的结果。同样是4分类器情况下,假设样本 i i i的真实标签为2,则向量 y ∗ \boldsymbol{y^*} y∗的构成如下所示:
| 0 0 0 | 1 1 1 | 2 2 2 | 3 3 3 | |
|---|---|---|---|---|
| y ∗ \boldsymbol{y^*} y∗ | − 1 3 -\frac{1}{3} −31 | − 1 3 -\frac{1}{3} −31 | 1 1 1 | − 1 3 -\frac{1}{3} −31 |
用公式表示则有:
y ∗ = { 1 i f k = y i − 1 K − 1 i f k ≠ y i y^*= \begin{cases} 1& if \ k=y_i \\ -\frac{1}{K-1}& if\ k\neq y_i \end{cases} y∗={1−K−11if k=yiif k=yi
其中 y i y_i yi为样本的真实标签, k k k为所有预选标签类别。不难发现,在此规则下,此时向量 y ∗ \boldsymbol{y^*} y∗以及向量 H ∗ ( x ) \boldsymbol{H^*(x)} H∗(x)的和永远是0,因为向量内部总是1与(K-1)个 − 1 K − 1 -\frac{1}{K-1} −K−11相加。
K = 4
y = [1,(-1/(K-1)),(-1/(K-1)),(-1/(K-1))]
int(sum(y))
#0
在多分类算法当中,我们常常求解类似于 y ∗ \boldsymbol{y^*} y∗或 H ∗ ( x ) \boldsymbol{H^*(x)} H∗(x)的向量,比如在softmax函数中,当预测值或真实值不等于 k k k时,我们赋予的向量值为0,而不是 − 1 K − 1 -\frac{1}{K-1} −K−11。
softmax的一般规则:
| 0 0 0 | 1 1 1 | 2 2 2 | 3 3 3 | |
|---|---|---|---|---|
| H t k ( x i ) H_t^k(x_i) Htk(xi) | 0.1 0.1 0.1 | 0.2 0.2 0.2 | 0.2 0.2 0.2 | 0.5 0.5 0.5 |
| H ∗ ( x ) H^*(x) H∗(x) | 0 0 0 | 0 0 0 | 0 0 0 | 1 1 1 |
同时,当K=2时,多分类指数损失的值与二分类指数损失完全一致:
多分类指数损失:
假设K=2,
L = e x p ( − 1 K ( y ∗ 1 H ∗ 1 ( x ) + y ∗ 2 H ∗ 2 ( x ) ) ) \begin{aligned} L = exp \left( -\frac{1}{K} \left( y^{*1}H^{*1}(x)+y^{*2}H^{*2}(x) \right) \right) \end{aligned} L=exp(−K1(y∗1H∗1(x)+y∗2H∗2(x)))
假设预测分类 = 真实分类 = 1,
| 1 1 1 | 2 2 2 | |
|---|---|---|
| H t k ( x i ) H_t^k(x_i) Htk(xi) | 0.7 0.7 0.7 | 0.3 0.3 0.3 |
| H ∗ ( x ) H^*(x) H∗(x) | 1 1 1 | − 1 2 − 1 -\frac{1}{2-1} −2−11 |
| 1 1 1 | 2 2 2 | |
|---|---|---|
| y ∗ \boldsymbol{y^*} y∗ | 1 1 1 | − 1 2 − 1 -\frac{1}{2-1} −2−11 |
− 1 K ( y ∗ 1 H ∗ 1 ( x ) + y ∗ 2 H ∗ 2 ( x ) ) = − 1 2 ( 1 ∗ 1 + − 1 2 − 1 ∗ − 1 2 − 1 ) = − 1 2 ( 1 + 1 ) = − 1 \begin{aligned} -\frac{1}{K}&\left( y^{*1}H^{*1}(x)+y^{*2}H^{*2}(x) \right)\\ &= -\frac{1}{2} \left( 1 * 1 + \frac{-1}{2-1} * \frac{-1}{2-1} \right)\\ &= -\frac{1}{2} \left( 1 + 1 \right)\\ &= -1 \end{aligned} −K1(y∗1H∗1(x)+y∗2H∗2(x))=−21(1∗1+2−1−1∗2−1−1)=−21(1+1)=−1
二分类指数损失,y=1,由于预测正确,所以 H ∗ ( x ) H^*(x) H∗(x) = 1
− y H ∗ ( x ) = − ( 1 ∗ 1 ) = − 1 \begin{aligned} -y&H^*(x)\\ & = -(1 * 1)\\ & = -1 \end{aligned} −yH∗(x)=−(1∗1)=−1
在实践中,无论是SAMME还是SAMME.R,我们都无法改变使用的损失函数,因此参数中没有为我们提供相应的选择。
loss(adaboost回归器才有)
看完参数algorithm,我们来看参数loss。与分类的情况完全相反,在AdaBoost回归当中,我们能够使用的算法是唯一的,即AdaBoost.R2,但是在R2算法下,我们却可以选择三种损失函数,分别是"linear"(线性),“square”(平方),“exponential”(指数)。
在算法AdaBoost.R2当中,三种损失函数如下定义:
首先:
D = s u p ∣ H ( x i ) − y i ∣ , i = 1 , 2 , . . . , N D = sup|H(x_i) - y_i|, i = 1,2,...,N D=sup∣H(xi)−yi∣,i=1,2,...,N
其中 y i y_i yi为真实标签, H ( x i ) H(x_i) H(xi)为预测标签,sup表示“取最大值”,但它与直接写作max的函数的区别在于,max中的元素已是固定的数值,而sup中的元素可以是一个表达式、并让该表达式在i的备选值中循环。上述式子表示,取出1~N号样本中真实值与预测值差距最大的那一组差异来作为D的值。
R2算法线性损失——
L i = ∣ H ( x i ) − y i ∣ D L_i = \frac{|H(x_i) - y_i|}{D} Li=D∣H(xi)−yi∣
R2算法平方损失——
L i = ∣ H ( x i ) − y i ∣ 2 D 2 L_i = \frac{|H(x_i) - y_i|^2}{D^2} Li=D2∣H(xi)−yi∣2
R2算法指数损失——
L i = 1 − e x p ( − ∣ H ( x i ) − y i ∣ D ) L_i = 1 - exp \left( \frac{-|H(x_i) - y_i|}{D} \right) Li=1−exp(D−∣H(xi)−yi∣)
不难发现,其实线性损失就是我们常说的MAE的变体,平方损失就是MSE的变体,而指数损失也与分类中的指数损失高度相似。在R2算法当中,这些损失函数特殊的地方在于分母D。由于D是所有样本中真实值与预测值差异最大的那一组差异,因此任意样本的 L i L_i Li在上述线性与平方损失定义下,取值范围都只有[0,1](当真实值=预测值时,取值为0,当真实值-预测值=D时,取值为1)。
特别的,对于指数损失来说,自变量的部分是在[0,1]中取值,因此 e − x e^{-x} e−x的在该定义域上的值域也为[0,1],因此 1 − e − x 1-e^{-x} 1−e−x的值域为[0,1]。事实上,在R2算法的论文当中,就有明确对损失函数的唯一要求:即值域为[0,1]。该规则使得整个AdaBoost算法的求解流程变得顺畅,具体可以在《2 原理进阶:AdaBoost的求解流程》中看到。
现在,我们已经了解了AdaBoost的全部参数了。不难发现,在AdaBoost的参数空间中,n_estimators与learning_rate是最为重要的两个参数。当我们在进行超参数调整时,注意对这两个参数的组合进行同时调整即可。
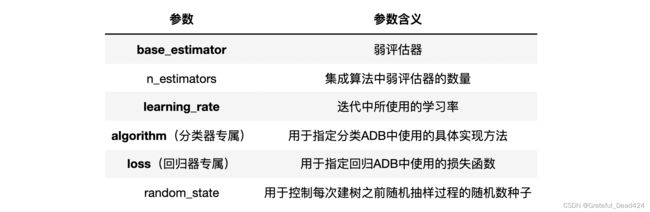
| 参数 | 参数含义 |
|---|---|
| base_estimator | 弱评估器 |
| n_estimators | 集成算法中弱评估器的数量 |
| learning_rate | 迭代中所使用的学习率 |
| algorithm(分类器专属) | 用于指定分类ADB中使用的具体实现方法 |
| loss(回归器专属) | 用于指定回归ADB中使用的损失函数 |
| random_state | 用于控制每次建树之前随机抽样过程的随机数种子 |