mlp 参数调优_AdaBoost算法介绍及其参数讲解
算法介绍
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
算法流程:
该算法其实是一个简单的弱分类算法提升过程,这个过程通过不断的训练,可以提高对数据的分类能力。整个过程如下所示:
1. 先通过对N个训练样本的学习得到第一个弱分类器;
2. 将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第二个弱分类器;
3. 将1和2都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学习得到第三个弱分类器;
4. 最终经过提升的强分类器。即某个数据被分为哪一类要由各分类器权值决定。
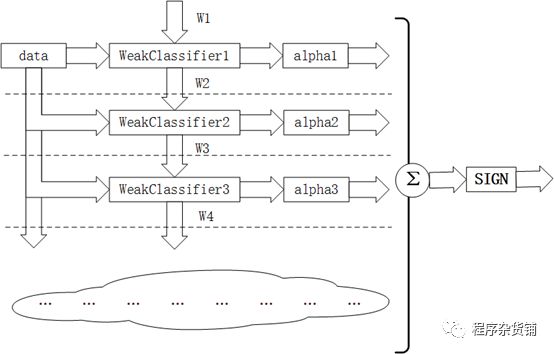
由Adaboost算法的描述过程可知,该算法在实现过程中根据训练集的大小初始化样本权值,使其满足均匀分布,在后续操作中通过公式来改变和规范化算法迭代后样本的权值。样本被错误分类导致权值增大,反之权值相应减小,这表示被错分的训练样本集包括一个更高的权重。这就会使在下轮时训练样本集更注重于难以识别的样本,针对被错分样本的进一步学习来得到下一个弱分类器,直到样本被正确分类。在达到规定的迭代次数或者预期的误差率时,则强分类器构建完成。
Adaboost算法中有两种权重,一种是数据的权重,另一种是弱分类器的权重。其中,数据的权重主要用于弱分类器寻找其分类误差最小的决策点,找到之后用这个最小误差计算出该弱分类器的权重(发言权),分类器权重越大说明该弱分类器在最终决策时拥有更大的发言权。
算法优势
Aadboost 算法系统具有较高的检测速率,且不易出现过适应现象。但是该算法在实现过程中为取得更高的检测精度则需要较大的训练样本集,在每次迭代过程中,训练一个弱分类器则对应该样本集中的每一个样本,每个样本具有很多特征,因此从庞大的特征中训练得到最优弱分类器的计算量增大。
算法优点:
adaboost是一种有很高精度的分类器;
可以使用各种方法构建子分类器,adaboost算法提供的是框架;
当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单;
简单,不用做特征筛选;
不用担心overfitting!
参数介绍
sklearn.ensemble.AdaBoostClassifier(base_estimator=None,*,n_estimators=50,learning_rate=1.0,algorithm='SAMME.R',random_state=None)
框架参数:
base_estimator:弱学习器,AdaBoostClassifier和AdaBoostRegressor都有。理论上可以选择任何一个分类或者回归学习器,不过需要支持样本权重。常用的一般是CART决策树或者神经网络MLP。如果选择的AdaBoostClassifier算法是SAMME.R,则我们的弱分类学习器还需要支持概率预测,也就是在scikit-learn中弱分类学习器对应的预测方法除了predict还需要有predict_proba。
n_estimators: 弱学习器数量,两者都有,一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是50。在实际调参的过程中,常常将n_estimators和下面介绍的参数learning_rate一起考虑。
learning_rate:弱学习器的权重缩减系数,取值范围为0~1。对于同样的训练集拟合效果,较小的ν意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。所以这两个参数n_estimators和learning_rate要一起调参。一般来说,可以从一个小一点的ν开始调参,默认是1。
algorithm:分类算法,AdaBoostClassifier才有,可选SAMME和SAMME.R。两者的区别是弱学习器权重的度量,SAMME使用分类器的分类效果作为弱学习器权重,而SAMME.R使用了对样本集分类的预测概率大小来作为弱学习器权重。由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,因此默认是用SAMME.R。一般直接使用默认,注意的是使用了SAMME.R, 则弱分类学习器参数base_estimator必须限制使用支持概率预测的分类器。SAMME算法则没有这个限制。
loss:误差的计算函数,只有AdaBoostRegressor有,可选线性'linear', 平方'square'和指数'exponential', 默认是线性,一般使用线性就足够了。这个值的意义在原理篇我们也讲到了,它对应了我们对第k个弱分类器的中第i个样本的误差的处理,即:如果是线性误差,则eki=|yi−Gk(xi)|Ek;如果是平方误差,则eki=(yi−Gk(xi))2E2k,如果是指数误差,则eki=1−exp(−yi+Gk(xi))Ek),Ek为训练集上的最大误差Ek=max|yi−Gk(xi)|i=1,2…m
弱分类器参数:
弱分类器参数要根据所选弱分类器而定,一般使用CART决策树,参数如下:
criterion: 特征选取方法,分类是gini(基尼系数),entropy(信息增益),通常选择gini,即CART算法,如果选择后者,则是ID3和C4.5;回归是mse或mae,前者是均方差,后者是和均值的差的绝对值之和,一般用前者,因为前者通常更为精准,且方便计算。
splitter: 特征划分点选择方法,可以是best或random,前者是在特征的全部划分点中找到最优的划分点,后者是在随机选择的部分划分点找到局部最优的划分点,一般在样本量不大的时候,选择best,样本量过大,可以用random。
max_depth: 树的最大深度,默认可以不输入,那么不会限制子树的深度,一般在样本少特征也少的情况下,可以不做限制,但是样本过多或者特征过多的情况下,可以设定一个上限,一般取10~100。
min_samples_split:节点再划分所需最少样本数,如果节点上的样本树已经低于这个值,则不会再寻找最优的划分点进行划分,且以结点作为叶子节点,默认是2,如果样本过多的情况下,可以设定一个阈值,具体可根据业务需求和数据量来定。
min_samples_leaf: 叶子节点所需最少样本数,如果达不到这个阈值,则同一父节点的所有叶子节点均被剪枝,这是一个防止过拟合的参数,可以输入一个具体的值,或小于1的数(会根据样本量计算百分比)。
min_weight_fraction_leaf: 叶子节点所有样本权重和,如果低于阈值,则会和兄弟节点一起被剪枝,默认是0,就是不考虑权重问题。这个一般在样本类别偏差较大或有较多缺失值的情况下会考虑。
max_features: 划分考虑最大特征数,不输入则默认全部特征,可以选 log2N,sqrt(N),auto或者是小于1的浮点数(百分比)或整数(具体数量的特征)。如果特征特别多时如大于50,可以考虑选择auto来控制决策树的生成时间。
max_leaf_nodes:最大叶子节点数,防止过拟合,默认不限制,如果设定了阈值,那么会在阈值范围内得到最优的决策树,样本量过多时可以设定。
min_impurity_decrease/min_impurity_split:划分最需最小不纯度,前者是特征选择时低于就不考虑这个特征,后者是如果选取的最优特征划分后达不到这个阈值,则不再划分,节点变成叶子节点
属性:
estimators_:list of classifiers,拟合的基学习器的集合。
classes_:array of shape=[n_classes],类的标签。
n_classes_:int,类的数量。
estimator_weights_:array of floats,在提升的总体效果中,每个估计器的权重。
estimator_errors_:array of floats,在提升的总体效果中,每个估计器的分类误差。
feature_importances_:array of shape=[n_features],如果基学习器支持的话,它表示每个特征的重要性。
方法:
decision_function(X):返回决策函数值(比如svm中的决策距离)。
fit(X,Y):在数据集(X,Y)上训练模型。
get_parms():获取模型参数
predict(X):预测数据集X的结果。
predict_log_proba(X):预测数据集X的对数概率。
predict_proba(X):预测数据集X的概率值。
score(X,Y):输出数据集(X,Y)在模型上的准确率。
staged_decision_function(X):返回每个基分类器的决策函数值
staged_predict(X):返回每个基分类器的预测数据集X的结果。
staged_predict_proba(X):返回每个基分类器的预测数据集X的概率结果。
staged_score(X,Y):返回每个基分类器的预测准确率。
调优方法
在AdaBoost中要调节的参数其实不多,主要还是基学习器里面的参数。
n_estimators:基学习器的数量,适当增加基学习器的数量能提升acc,随后收敛,通常默认值已经收敛。(请保持默认)
learning_rate:学习率,对正确率影响非常大,请谨慎调节。
algorithm:算法的选择在一定程度上也会影响正确率,但是根据不同基学习器的选择,算法的选择也有所限制。
在更换基学习器的时候,发现,对于C-SVC和Nu-SVC,当我将之前做实验得到的最优正确率的参数代入其中的时候,不论我怎么修改AdaBoost的参数,正确率都不会发生改变且和基学习器的最优正确率相同。
适用场景
对adaBoost算法的研究以及应用大多集中于分类问题,同时也出现了一些在回归问题上的应用。就其应用adaBoost系列主要解决了: 两类问题、多类单标签问题、多类多标签问题、大类单标签问题、回归问题。它用全部的训练样本进行学习。
用于二分类或多分类的应用场景;
用于做分类任务的baseline;
无脑化,简单,不会overfitting,不用调分类器;
用于特征选择(feature selection);
Boosting框架用于对badcase的修正;
只需要增加新的分类器,不需要变动原有分类器。
demo示例
from sklearn.model_selection import cross_val_scorefrom sklearn.datasets import load_irisfrom sklearn.ensemble import AdaBoostClassifierX, y = load_iris(return_X_y=True)clf = AdaBoostClassifier(n_estimators=100)scores = cross_val_score(clf, X, y, cv=5)scores.mean()# 0.9...from sklearn.ensemble import AdaBoostClassifierfrom sklearn.datasets import make_classificationX, y = make_classification(n_samples=1000, n_features=4, n_informative=2, n_redundant=0, random_state=0, shuffle=False)clf = AdaBoostClassifier(n_estimators=100, random_state=0)clf.fit(X, y)# AdaBoostClassifier(n_estimators=100, random_state=0)clf.predict([[0, 0, 0, 0]])# array([1])clf.score(X, y)# 0.983...