周志华《机器学习》——模型的评估与选择
在一幅图解释机器学习中,我们假设要进行分辨西瓜好坏的任务。
如何从众多的评判方法中,选出更好的方法呢(也就是从假设空间到版本空间)
这个过程需要解决三个问题:
1、如何判断哪个方法更好?
——越好的方法,其判断结果应该越符合真实世界(设置合理的性能度量指标,衡量判断结果和真实世界的差距)
2、在什么数据集上测试方法的好坏?
——测试集应该能够代表真实世界,且不会影响到模型训练(合理分割测试集和训练集)
3、毕竟测试集只是真实世界的抽样,如何判断在测试集上的测试结果是不是适用于真实世界?
——进行统计学检验
接下来我们分别详述一下上述三个问题的解决方法:
1、如何判断哪个方法更好——设置性能度量指标
1.1 回归任务的常用性能度量是“均方误差”
1.2 分类任务的常用性能度量包括:
(1)错误度和精度:错误度是所有分类错误的样本占总样本的比例,精度是所有分类正确的样本占总样本的比例,二者相加等于1
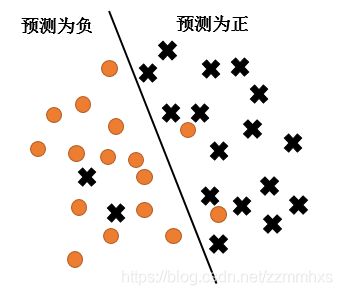
(2)查准率、查全率和F1:
查准率(precision)是所有预测为正的里面,×的比例,查全率(recall)是所有×中被预测为正的比例
因为查准率和查全率通常二者不可得兼,为了统筹两个性能指标,比较到底哪个方法更好,我们提出了F1值
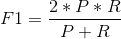
在不同的情况下,可以采用不同的F1变体:
如:当查准率和查全率重要程度不一样时(逃犯检索系统,宁可错杀不可放过,所以查全率更重要),
可以采用
![]()
或者有多个二分类混淆矩阵时,可以计算macro-F1或者micro-F1
(3)ROC和AUC
ROC如是为每个测试样本产生一个“是正类”的概率,然后将所有样本按照概率进行排序
最后从第一个到最后一个,依次计算,假如在此之前的所有样本都被划分为正类,之后的样本都被划分为负类,
则分类器的TPR和FPR分别为多少。
在坐标轴上,以TPR为纵轴,FPR为横轴
TPR=预测为正的×/全部×
FPR = 预测为负的·/全部·
最理想的分类结果是,所有正例都排在负例前面,
也就是分类器可以通过设定一个合适的阈值,将所有正例和所有负例完美分割开,
此时图像是一个(0,0)到(0,1),然后从(0,1)到(1,1)的折线,所以ROC图,越接近(0,1)点性能越好

AUC则是ROC曲线下方的面积。
(4)代价曲线
还是上述例子,在逃犯检索系统中,正反例被分类错的后果是不一样的,即代价敏感。
ROC统计的是错误的例子的数量占总数的百分比,因此不能反应出非均等代价下的性能。
因此提出代价曲线来解决非均等代价下模型性能的衡量问题。
(公式好复杂没看懂,待补充)
结论是:
代价曲线可以通过ROC图转化而来,
ROC图上每一点坐标均为(FPR,TPR),根据FNR=1-TPR,绘制一条从(0,FPR)到(1,FNR)的线
画出ROC上没一点对应的线后,所有线段的下界围成的面积即为所有条件下学习器的期望总体代价

2、在什么数据集上测试方法的好坏?——设置测试集
(1)留出法
直接将数据集D划分为互斥的训练集S和测试集T,通常选择三分之二到五分之四用于训练
为了减小因为不同的S和T划分导致的测试结果的不同,可以将D随机抽取100次,
生成100个测试集和训练集,进行100次训练和测试后返回测试的平均值
(2)交叉验证法
将数据分为K个大小相似的互斥子集,每次选择一个子集用作测试,剩下的训练,最终返回K次测试的平均值。
也可以进行p次k折较差验证后再取平均。
(3)自助法
上述两个方法中都需要留出部分数据进行测试,从而减少了用于训练的数据,影响了模型的性能。
自助法从包含m个样本的D中有放回的抽取m个样本放入D',根据概率,
m次抽取始终没有被放入D'的样本的的数量应该在36.8%附近。
我们用D'训练,用包含一部分没见过的数据的D测试。
自助法有效地保留了训练数据,因此在数据集较小,难以有效划分训练测试集的时候比较有用
但是D'的数据分布改变了初始的数据分布,因此在训练数据较多时一般不采用。
3、如何判断在测试集上的测试结果是不是适用于真实世界?——进行统计假设检验