Zero-Shot Instance Segmentation 阅读笔记
概述
本文根据视觉-语义相映射的思想,提出了一种采用语义词向量来检测和分割未见实例的端到端网络
,概括来讲,就是把数据分为两类,seen类 C s C_s Cs和unseen类 C u C_u Cu,训练集由 C s C_s Cs组成,通过训练集中的图像 x s x_s xs和与之对应的词向量 w s w_s ws来进行训练得到模型,来实现从seen实例中学习参数然后用它来推理unseen的实例。主要目的是针对工业应用上缺少数据的问题,引入词向量,通过对齐语义信息和图像特征,从而实现对未经训练类的检测和分割。
本文的模型是基于Faster R-CNN来设计的,模型结构如下,整个模型的核心部分包括Zero-Shot Detector、SMH(Seman Mask Head)、BA-RPN和Sync-bg(Synchronized Background)。

为了方便对比,下面贴一下Faster R-CNN的大致结构

Zero-Shot Detector
下图所示为Zero-Shot Detector的网络结构,其中 W s W_s Ws是seen类和背景类的词向量。 W u W_u Wu是unseen类和背景类的词向量。S是seen类的数量,U是unseen类的数量。每个类都有300维度的词向量。B是batchsize。
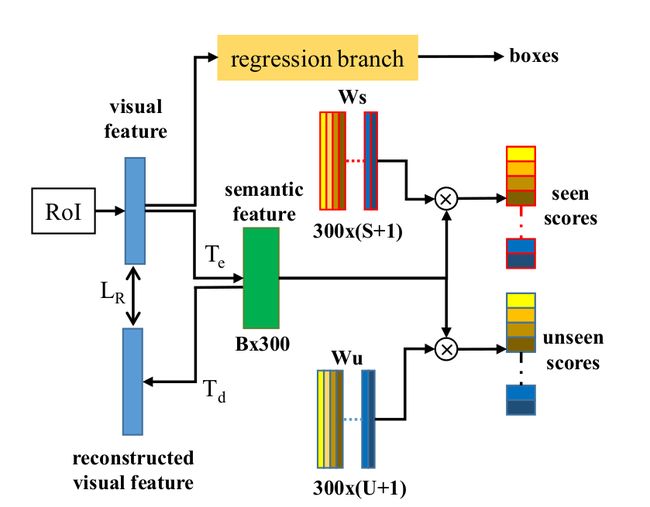
核心思想是从seen类数据中学习视觉特征和语义两种概念之间的关系并将其运用到检测unseen类目标中,对比Faster R-CNN的结构我们可以发现,作者用新设计的语义-分类分支(semantic-classification)替换了Faster R-CNN中原本的分类分支,对于这个新的分支,属于一种编解码的结构,在训练过程中,使用编码器 T e T_e Te来将从RoI输入进来的视觉特征转换为语义特征然后使用解码器 T d T_d Td来把语义特征重新解码回视觉特征, L R L_R LR是我们的损失函数,目的是为了减少针对视觉特征的重构错误,解码器和损失函数能够促进网络去学习,以便更好的将视觉-语义做对齐。在推理过程中,解码器 T d T_d Td不会被使用,我们能够通过分别对语义特征和 W s W_s Ws 、 W u W_u Wu来执行矩阵乘法来为seen类和unseen类进行进行概率赋分。
Semantic Mask Head
下图所示为SMH(Semantic Mask Head)的网络结构图,为了对unseen类实例进行实例分割,通过使用视觉-语义映射关系来进行分割,整体的结构仍旧为一种编解码结构。

编码器E是一个单一的1x1卷积层,将视觉特征解码到语义空间,然后我们可以从语义词向量中得到分割结构。考虑到这个单向编码结构不足以严谨的让视觉特征和语义相对齐,作者开发了一个解码结构D,用损失函数 L R L_R LR来进一步提高视觉特征和语义词向量之间的映射关系的质量。文中解码器解码语义的词向量回到视觉特征,同时使用损失函数 L R L_R LR来最小化重构的视觉特征和原始视觉特征的差异。以此为目的,该解码器相对于编码器具有对称结构,同样包含单个1x1卷积层,并有着与编码器E相反的输入输出通道。使用300维度的词向量作为作为每个类别的语义表征,所以编码器E负责将输入的视觉特征转换为300维度的语义特征。在这个300x28x28的语义特征张量中,每个通道都代表了词向量的一个维度,每个300x1元素都是一个词向量。为了得到每个元素的分类结果分数,我们需要计算每个元素的词向量和所有seen类和unseen类的词向量的相似度,从而找到最接近的类。为了这个目的,在编码器后面加入了一个分类器。这个模块包含两个分支,分别是针对seen类和unseen类。在上述所提及的分支中, W s W_s Ws-Conv表示固定的1x1卷积层,我们采用所有的seen类和背景类的词向量作为它的权重, W u W_u Wu-Conv同样固定1x1卷积层,并用包含所有unseen类和背景类的词向量作为权重, W s W_s Ws和 W u W_u Wu在我们的zero-shot检测器中是一样的。我们通过分数,合并seen类和unseen类的结果。
关于SMH模块和Zero-Shot Detector中都出现的损失函数 L R L_R LR,如下所示,利用MSE Loss计算原始视觉特征O和重构视觉特征R中每个元素的均方误差。
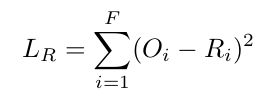
BA-RPN and Synchronized Background
在Zero-Shot Detector的介绍中我们知道,seen类和unseen类的词向量 W s W_s Ws和 W u W_u Wu用作固定FC层的权重值,用来将对象分类为n+1类,n表示可见类和未见类数量,1表示背景类。同时在SMH(Semantic Mask Head)模块的介绍中,又一次的使用了 W s W_s Ws和 W u W_u Wu来作为 W s W_s Ws-Conv和 W u W_u Wu-Conv的权重值,将像素分为n+1类,即,还将每个像素分类为背景类和其他目标类。由此可知 W s W_s Ws和 W u W_u Wu中背景类的词向量直接影响到背景类的分类结果。又因为现有的背景类词向量是从大规模文本数据中学习而来的,没有很好的利用视觉信息,不能有效的表达复杂的背景类。未解决该问题,作者提出了BA-RPN网络,该网络将视觉语义学习过程引入到原始的RPN网络中,以从图像中学习得到更加合理的背景类词向量。BA-RPN的结构如下图所示,使用T将BxN维的视觉特征转换为Bx300维的语义特征,其中B是批次大小,N是视觉特征的维度。然后使用包含背景类的词向量 V b V_b Vb的Wbf来获得前景-背景类的的分类概率分数Sbf。我们使用Sync-bg来同步Zero-Shot Detector的W W s W_s Ws和 W u W_u Wu中的 V b V_b Vb,SMH中的 W s W_s Ws-Conv和 W u W_u Wu-Conv。

作者使用300x2维FC层Wbf从输入的视觉特征中获取背景-前景二分类的概率分数。Wbf的维度为300x2向量,表示学习前景和背景两种词向量。Wbf将在训练过程中进行优化,以便我们能够为背景类学习到一个新的词向量 V b V_b Vb。
现在我们有了一个新的词向量作为背景类,它可以用来替换我们的Zero-Shot Detector和SMH中的原始词向量。但是这样做仍然有一个问题,背景类在不同的图像中有不同的形式,而从BA-RPN中学习到的背景词向量仍然是固定的。BA-RPN和整个ZSI框架的训练过程被剥离,导致背景学习仅限于BA-RPN,Zero-Shot Detector和SMH的优势没有得到很好的利用。为了解决这些问题,作者提出了同步背景策略(Synchronized Background),并在训练和推理中使用这种同步操作,具体过程如下:
输入:来自特征提取网络(backbone)的视觉特征x
1、将x输入到BA-RPN来得到所有候选区域的背景词向量 V b V_b Vb和特征 x p x_p xp
2、用背景词向量 V b V_b Vb更Zero-Shot Detector中的 W s W_s Ws
3、用背景词向量 V b V_b Vb更新SMH中的 W s W_s Ws-Conv
4、通过Zero-Shot Detector和SMH前向传播 x p x_p xp
5、计算损失然后反向传播来更新BA-RPN中的背景词向量 V b V_b Vb
最后
论文:https://arxiv.org/abs/2104.06601
源码:https://github.com/zhengye1995/Zero-shot-Instance-Segmentation
水平有限,有理解不到位的地位还请大佬们指正
