【轻量级网络】--ShuffleNet V2论文解读
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
参考文章:https://blog.csdn.net/u014380165/article/details/81322175
Abstract
目前,神经网络架构设计主要由计算复杂度的间接度量(即FLOPs)引导。然而,直接度量(例如,速度)还取决于诸如存储器访问成本和平台特性之类的其他因素。因此,这项工作建议评估目标平台上的直接度量,而不仅仅考虑FLOPs。
1 Introduction
实时任务通常旨在在由目标平台(例如,硬件)和应用场景(例如,自动驾驶需要低等待时间)给出的有限计算预算下获得最佳准确度。这激发了一系列针对轻量级架构设计和更快速度准确性的工作,包括Xception ,MobileNet ,MobileNet V2 ,ShuffleNet和CondenseNet 。Group convolution 和depth-wise convolution 这些工作中至关重要。
为了测量计算复杂性,广泛使用的度量是浮点运算的数量,或FLOPs,这个指标主要衡量的就是卷积层的乘法操作。但是这篇文章通过一系列的实验发现FLOPs并不能完全衡量模型速度,比如在Figure1(c)(d)中,相同MFLOPs的网络实际速度差别却很大,因此以FLOPs作为衡量模型速度的指标是有问题的。

间接(FLOPs)和直接(速度)指标之间的差异可归因于两个主要原因。首先,FLOP没有考虑几个对速度有很大影响的重要因素。一个这样的因素是内存访问消耗时间(MAC)。在诸如group卷积的某些操作中,这种成本占运行时的很大一部分。它可能是具有强大计算能力的设备(例如GPU)的瓶颈。另一个是并行度。在相同的FLOP下,具有高并行度的模型可能比具有低并行度的另一个模型快得多。
其次,具有相同FLOPs的操作可能具有不同的运行时间,具体取决于平台。例如,张量分解广泛用于早期工作以加速矩阵乘法。然而,最近的工作发现分解在GPU上甚至更慢,尽管它将FLOP降低了75%。我们调查了这个问题并发现这是因为最新的CUDNN 库专门为3×3转换而优化。我们当然不能认为3×3转换比1×1转速慢9倍。
通过这些观察,我们提出应该考虑两个原则来实现有效的网络架构设计。首先,应该使用直接度量(例如,速度)而不是间接度量(例如,FLOPs)。其次,应在目标平台上评估此类指标。
2 高效网络设计实用指南
我们的研究是在两个广泛采用的硬件上进行的,输入图像大小为224×224。每个网络随机初始化并评估100次。
为了开始我们的研究,我们分析了两个SOTA的网络的运行时间性能,ShuffleNet v1和MobileNet v2。它们广泛用于移动设备等低端设备。它们代表了当前的趋势,其核心是group convolution 和 depth-wise convolution,它们也是其他SOTA的关键组件,如ResNeXt ,Xception ,MobileNet和CondenseNet。
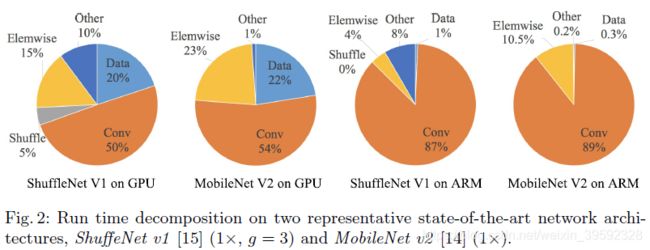
整个运行时被分解用于不同的操作,如图2所示。我们注意到FLOPs度量仅考虑卷积部分,虽然这部分消耗的时间最多,但其他操作包括数据I / O,数据shuffle和element-wise操作(AddTensor,ReLU等)也占用了相当多的时间。因此,FLOP对实际运行时的估计不够准确。
G1)卷积层的输入和输出特征通道数相等时MAC最小
现代网络通常采用深度可分离卷积depthwise separable convolutions,其中逐点卷积(即1×1卷积)占复杂性的大部分。我们研究了1×1卷积的kernel shape。形状由两个参数指定:输入通道数 c 1 {c_1} c1和输出通道数 c 2 {c_2} c2。设h和w为特征映射的spatial size,1×1卷积的FLOPs为 B = h w c 1 c 2 B = hw{c_1}{c_2} B=hwc1c2,更具体的写法是 B = 1 ∗ 1 ∗ h w c 1 c 2 B = 1*1*hw{c_1}{c_2} B=1∗1∗hwc1c2。
接下来看看存储空间,因为是1*1卷积,所以输入特征和输出特征的尺寸是相同的,这里用h和w表示,其中 h w c 1 hw{c_1} hwc1表示输入特征所需存储空间, h w c 2 hw{c_2} hwc2表示输出特征所需存储空间,c1c2表示卷积核所需存储空间, M A C = h w ( c 1 + c 2 ) + c 1 c 2 MAC = hw({c_1} + {c_2}) + {c_1}{c_2} MAC=hw(c1+c2)+c1c2
根据均值不等式可以得到 M A C ≥ 2 h w B + B h w MAC \ge 2\sqrt {hwB} + \frac{B}{{hw}} MAC≥2hwB+hwB
把MAC和B代入上式,就得到 ( c 1 − c 2 ) 2 ≥ 0 {({c_1} - {c_2})^2} \ge 0 (c1−c2)2≥0,因此等式成立的条件是 c 1 = c 2 {c_1} = {c_2} c1=c2,也就是输入特征通道数和输出特征通道数相等时,在给定FLOPs前提下,MAC达到取值的下界。
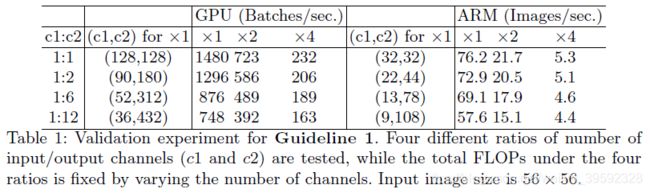
为了验证上述结论,如下进行实验。通过重复堆叠10个building blocks来构建基准网络。每个块包含两个卷积层。第一个包含 c 1 {c_1} c1输入通道和 c 2 {c_2} c2输出通道,第二个相反。表1通过改变比率 c 1 : c 2 {c_1}:{c_2} c1:c2来报告运行速度,同时确定总FLOPs。很明显,当 c 1 : c 2 {c_1}:{c_2} c1:c2接近1:1时,MAC变小,网络评估速度更快。
G2)过多的group卷积操作会增大MAC
group卷积是现代网络架构的核心,它通过将所有通道之间的密集卷积改变为稀疏(仅在通道组内)来降低计算复杂度(FLOPs)。一方面,它允许在给定固定FLOPs的情况下使用更多通道,并增加网络容量(从而提高精度)。然而,另一方面,增加的通道数导致更多的MAC。
和前面同理,带group操作的1*1卷积的FLOPs为 B = h w c 1 c 2 / g B = hw{c_1}{c_2}/g B=hwc1c2/g,多了一个除数g,g表示group数量。这是因为每个卷积核都只和c1/g个通道的输入特征做卷积,所以多个一个除数g。 同理, M A C = h w ( c 1 + c 2 ) + c 1 c 2 g MAC = hw({c_1} + {c_2}) + \frac{{{c_1}{c_2}}}{g} MAC=hw(c1+c2)+gc1c2,和前面不同的是这里卷积核的存储量多了除数g,和B同理。
1×1组卷积的MAC和FLOPs之间的关系是

定固定的输入形状 c 1 × h × w {c_1} \times h \times w c1×h×w和计算成本B,MAC随着g的增长而增加。
为了研究实际中的影响,通过堆叠10个逐点组卷积层来构建基准网络。表二报告了当使用固定总FLOPs不同组数的运行时间
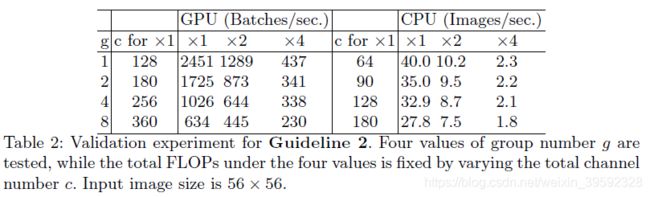
其中c表示 c 1 + c 2 {c_1} + {c_2} c1+c2的和,通过控制这个参数可以使得每个实验的FLOPs相同,可以看出随着g的不断增大,c也不断增大,这和前面说的在基本不影响FLOPs的前提下,引入group操作后可以适当增加网络宽度吻合。从速度上看,group数量的增加对速度的影响还是很大的,原因就是group数量的增加带来MAC的增加(公式2),而MAC的增加带来速度的降低。
G3)模型中的分支数量越少,模型速度越快
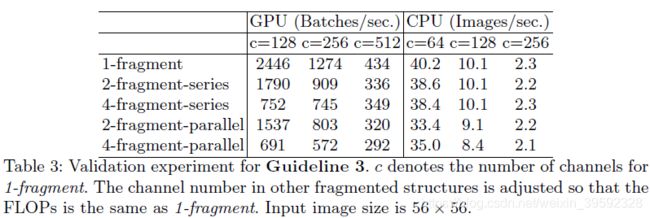
网络结构设计上,文章用了一个词:fragment,可以简单理解为网络的支路数量。为了研究fragment对模型速度的影响,作者做了Table3这个实验,其中2-fragment-series表示一个block中有2个卷积层串行,也就是简单的叠加;4-fragment-parallel表示一个block中有4个卷积层并行,类似Inception的整体设计。可以看出在相同FLOPs的情况下,单卷积层(1-fragment)的速度最快。因此模型支路越多(fragment程度越高)对于并行计算越不利,这样带来的影响就是模型速度变慢,比如Inception、NASNET-A这样的网络。
G4)element-wise操作所带来的时间消耗远比在FLOPs上的体现的数值要多
如图2所示,轻量级模型中,element-wise操作占用了相当多的时间,尤其是在GPU上。这里,element-wise操作符包括ReLU,AddTensor,AddBias等。
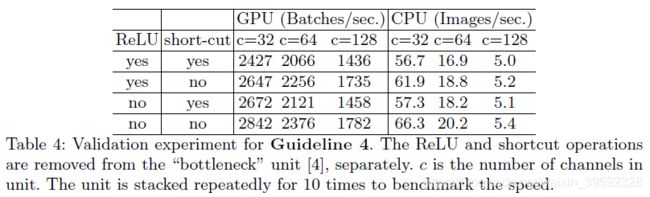
因此作者做了Table4的实验,Table4的实验是基于ResNet的bottleneck(1 × 1 conv+ 3 × 3 conv+1 × 1 conv, with ReLU and shortcut connection)的,short-cut其实表示的就是element-wise操作。这里作者也将depthwise convolution归为element-wise操作,因为depthwise convolution也具有低FLOPs、高MAC的特点。
轻量级神经网络架构的最新进展主要基于FLOPs度量,并未考虑上述这些属性。例如,ShuffleNet v1严重依赖于群卷积(针对G2)和类似瓶颈的构建块(针对G1)。MobileNet v2 使用了违反G1的inverted bottleneck结构。它在thick特征映射上使用深度卷积和ReLU,这违反了G4。auto-generated结构高度分散并违反G3。
3 ShuffleNet V2: an Efficient Architecture
回顾ShuffleNet V1
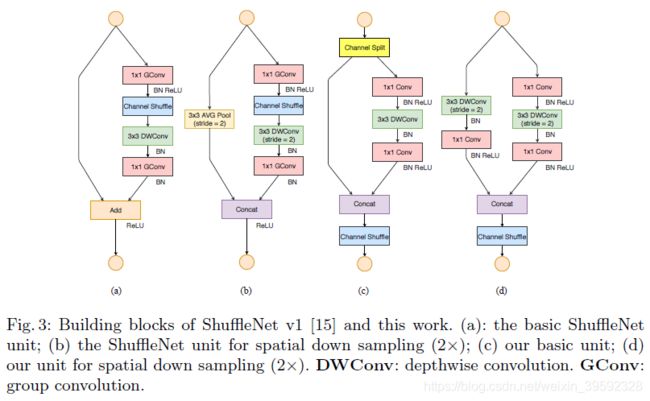
轻量级网络面临的主要挑战是,在给定的计算预算(FLOPs)下,只有有限数量的特征通道可用。为了在不显着增加FLOPs情况下增加通道数,在中采用了两种技术:逐点组卷积和瓶颈状结构。然后引入“通道shu ffl e”操作以实现不同通道组之间的信息通信并提高准确性。构建块如图3(a)(b)所示。其中(a)和(b)是ShuffleNet v1的两种不同block结构,两者的差别在于后者对特征图尺寸做了缩小,这和ResNet中某个stage的两种block功能类似。逐点组卷积和瓶颈结构都会增加MAC(G1和G2)。此外,使用太多组违反了G3。shortcut连接中的element-wise“Add”操作也是不合需要的(G4)。因此,为了实现高模型容量和效率,关键问题是如何保持大量且同样宽的通道,既没有密集卷积也没有太多组。
Channel Split and ShuffleNet V2
从(a)和(c)的对比可以看出首先(c)在开始处增加了一个channel split操作,这个操作将输入特征的通道分成c-c’和c’,c’在文章中采用c/2,这主要是和前面第1点发现对应。然后(c)中取消了1×1卷积层中的group操作,这和前面第2点发现对应,同时前面的channel split其实已经算是变相的group操作了。其次,channel shuffle的操作移到了concat后面,和前面第3点发现对应,同时也是因为第一个1*1卷积层没有group操作,所以在其后面跟channel shuffle也没有太大必要。最后是将element-wise add操作替换成concat,这个和前面第4点发现对应。多个(c)结构连接在一起的话,channel split、concat和channel shuffle是可以合并在一起的。(b)和(d)的对比也是同理,只不过因为(d)的开始处没有channel split操作,所以最后concat后特征图通道数翻倍,可以结合后面Table5的具体网络结构来看。
整体网络结构类似于ShuffleNet v1],并总结在表5中。只有一个不同之处:在global averaged pooling之前添加额外的1×1卷积层以混合特征,这在ShuffleNet v1中是不存在的。每个块中的通道数量被缩放以生成不同复杂度的网络,标记为0.5×,1×等。
Figure5是ShuffleNet v2的具体网络结构示意图,不同stage的输出通道倍数关系和前面描述的吻合,每个stage都是由Figure3(c)(d)所示的block组成,block的具体数量对于Figure5中的Repeat列。

网络准确性分析
ShuffleNet v2不仅效率高,而且准确。主要有两个原因。首先,每个构建块的高效率使得能够使用更多的特征通道和更大的网络容量。
其次,在每个块中,一半的特征通道(当 c ′ = c / 2 c' = c/2 c′=c/2时)直接通过该块并加入下一个块。这可以被视为一种特征重用,与DenseNet 和CondenseNet中的类似。
在DenseNet 中,为了分析特征重用模式,绘制了层间权重的l1范数,如图4(a)所示。很明显,相邻层之间的连接比其他层更强。这意味着所有层之间的密集连接可能引入冗余。最近的CondenseNet也支持这一观点。
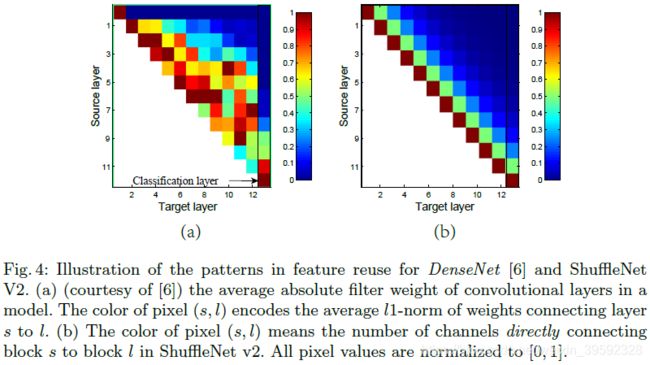
在ShuffleNet V2中,很容易证明第i和第(i + j)个构建块之间的“直接连接”通道的数量是 r j c {r^j}c rjc,其中 r = ( 1 − c ′ ) / c r = (1 - c')/c r=(1−c′)/c。换句话说,特征重用量随着两个块之间的距离呈指数衰减。在远程块之间,特征重用变得更弱。图4(b)绘制了与(a)中类似的可视化,其中r = 0.5。注意,(b)中的模式类似于(a)。
因此,ShuffleNet V2的结构通过设计实现了这种类型的特征重用模式。与DenseNet一样,它具有与高精度特征重用相似的优点,但如前面所分析的那样,它的效率要高得多。这在实验中得到验证,表8。
4 实验
Table8是关于一些模型在速度、精度、FLOPs上的详细对比。实验中不少结果都和前面几点发现吻合,比如MobileNet v1速度较快,很大一部分原因是因为简单的网络结构,没有太多复杂的支路结构;IGCV2和IGCV3因为group操作较多,所以整体速度较慢;Table8最后的几个通过自动搜索构建的网络结构,和前面的第3点发现对应,因为支路较多,所以速度较慢。

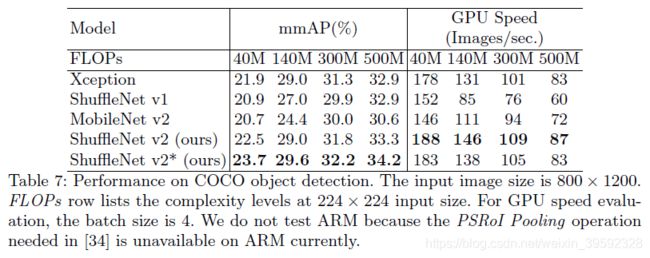
Table7是在COCO数据集上的速度和精度对比。ShuffleNet v2*是指在每个block的第一个pointwise卷积层前增加一个3×3的depthwise卷积层,可以参看前面Figure3(d),目的是增加感受野,这样有助于提升检测效果(受Xception启发)。