2023.1.8 学习周报
文章目录
- 摘要
- 文献阅读
-
- 1.题目
- 2.摘要
- 3.介绍
- 4.论文主要贡献
- 5.相关工作
-
- 5.1 序列感知的推荐系统
- 5.2 神经注意模型
- 6.模型:ATTREC
-
- 6.1 序列推荐
- 6.2 基于Self-Attention的用户短期兴趣建模
- 6.3 用户长期兴趣建模
- 6.4 模型学习
- 7.实验
-
- 7.1 数据集
- 7.2 评估指标
- 7.3 模型比较
- 7.4 实验效果
- 8.讨论
- 9.结论
- 深度学习
-
- 1.self-attention是什么?
- 2.self-attention的好处
- 3.模型
- 4.self-attention代码实现
- 总结
摘要
This week, I read a paper on the mechanism of self-attention, a new sequence aware recommendation model is proposed, which can estimate the relative weight of each item in the user interaction trajectory through the self-attention mechanism to better represent the user’s instantaneous interest. The key point of this paper is to propose a method combining metric learning and Self-Attention to solve the problem of sequence recommendation, and to explicitly control the impact of long-term and short-term interests on the model. I continue to learn about self-attention, I mainly learn the advantages of self-attention, the characteristics of model implementation, and the use of code to implement self-attention.
本周,我阅读了一篇关于自注意力机制相关的论文,论文提出了一种新的序列感知推荐模型,通过自注意力机制,能够估计用户交互轨迹中每个item的相对权重,以更好地表示用户的瞬时兴趣。论文最主要的核心点是提出结合度量学习和Self-Attention的方法来解决序列推荐问题,以及显式地控制了长短期兴趣对模型的影响。我继续展开对self-attention的学习,主要学习了self-attention的优点,模型实现的特点,以及用代码实现self-attention。
文献阅读
1.题目
文献链接:Next Item Recommendation with Self-Attentive Metric Learning
2.摘要
In this paper, we propose a novel sequence-aware recommendation model. Our model utilizes self-attention mechanism to infer the item-item relationship from user’s historical interactions. With self-attention, it is able to estimate the relative weights of each item in user interaction trajectories to learn better representations for user’s transient interests. The model is finally trained in a metric learning framework, taking both local and global user intentions into consideration. Experiments on a wide range of datasets on different domains demonstrate that our approach outperforms the state-of-theart by a wide margin.
3.介绍
问题:在推荐系统中,使用CNN和RNN去捕捉用户整个历史行为时,都存在着无法明确捕获item-item交互的问题。
方案:基于用户历史上下文对item-item的关系建模的动机是符合直觉的,因为是去理解item之间更为精细的关系,而不是简单的统一对待。论文假设为模型提供inductive bias将提升表示质量,并最终改进推荐系统的效果。
论文提出的模型不仅对连续的item建模,而且对当前窗口中的所有用户行为进行学习,因此整个模型可以视为是局部-全局方法。论文提出的模型采用度量学习框架的形式,在训练时使用户的self-attended表示为与预期item之间的距离更近,而且这篇文章是第一个提出基于度量学习和基于attention方法的序列推荐方法。
4.论文主要贡献
1)提出一种新的序列推荐任务框架,模型将self-attention网络与度量embedding相结合,以模拟用户的临时意图和长期意图。
2)提出的框架在固定的基准数据集上表现出最先进的性能,证明了在序列建模期间item-item交互的实用性。论文提出的模型超过了当前的Caser,TransRec和RNN等。
3)进行了广泛的超参数和消融研究,论文研究了各种关键超参数和模型架构对模型性能的影响,还提供了学习注意力矩阵的定性可视化。
5.相关工作
5.1 序列感知的推荐系统
论文中大多数方法是专门为评分预估任务设计的。除了马尔科夫链,度量embedding也在序列感知的推荐上有良好的表现。
5.2 神经注意模型
CNN和RNN需要从大量数据中学习以获得有意义的结果,但是数据稀疏性使得模型训练相当困难。然而注意力机制可以帮助克服它们的缺点,它能帮助RNN解决长依赖问题,并帮助CNN集中注意力到输入的重要部分。
最近将Attention应用到推荐的研究有hashtag recommendation,one-class recomendation,session based recommendation。在推荐系统中使用self-attention并非直截了当的,这证明了作者工作的新颖性。
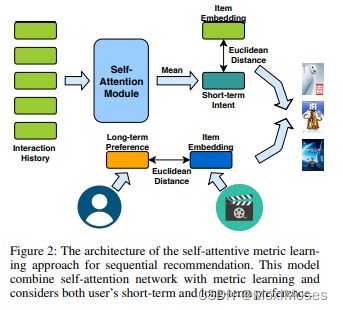
6.模型:ATTREC
AttRec用self-attention对用户短期兴趣建模,用协同度量学习对用户长期兴趣建模。
6.1 序列推荐
定义U为用户集合,I为item集合,其中| U |=M,| I |=N。定义用户行为序列为:
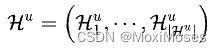
6.2 基于Self-Attention的用户短期兴趣建模

Self-Attention模块:
基础的attention只能通过对整个上下文中有限的知识进行学习,而self-attention能够保持上下文序列信息,并且不需要考虑它们之间的距离来捕获序列上各元素的关系。
这篇文章对Query和Key都做了ReLU的非线性变换,保持Value不变。在其他领域中,value通常是预训练的,用的是word embedding或图像特征。而在本文模型中value的值是需要学习的。无论是做线性变换还是非线性变换都会增加参数学习的困难,因为query和key是作为辅助因素,所以不像value对变换那么敏感。
为了学习单一attentive表示,将L个self-attention的Embedding取平均值作为用户短期兴趣:

有时间信号的输入Embedding:
如果没有序列信号,则输入退化为a bag of embedding,同时无法保留顺序模式。本文通过位置embedding给query和key增加时间信息,时间Embedding由两个正弦信号定义得到:
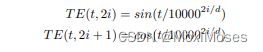
其中:TE在非线性变换之前添加给query和key。
6.3 用户长期兴趣建模
本文为了避免点积的问题,使用欧式距离来衡量item和user的接近程度:
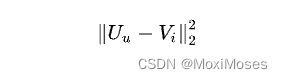
6.4 模型学习
目标函数:
给定时间步t的短期attentive隐因子和长期偏好后,任务为预测在时间步t+1用户将产生交互的item。为了保持一致,对短期和长期都用欧式距离建模,使用它们的和作为最终的推荐分数:
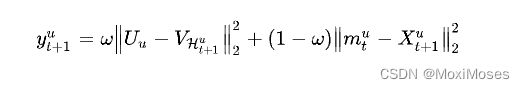
其中:第一项表示长期兴趣推荐分数,第二项表示短期兴趣推荐分数。
在某些情况下,想要预测几个item,而不是只预测一个item,这样能让模型捕获序列中的跳跃行为。定义T+为T个用户喜欢的item。本文采用pairwise排序方法学习模型参数,将T-定义为用户无行为的负样本。为了鼓励区分正负user-item对,使用基于边界的hinge loss:

其中:r是边界参数,用l2控制模型复杂度。在稀疏数据集上也是用归一裁剪策略来限制X, V, U在一个单元欧式球上:
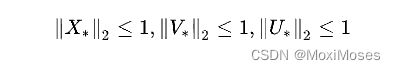
这种正则化方法对于稀疏数据集,减轻了维度问题的困扰并预防数据点不会传播得太广。
优化和推荐:
用adaptive gradient algorithm作为优化方法,推荐欧式距离最小的top N。在推荐阶段,一次计算所有user item对的推荐分数,用有效的排序算法生成排序列表。
下图为整个模型的框架:
7.实验
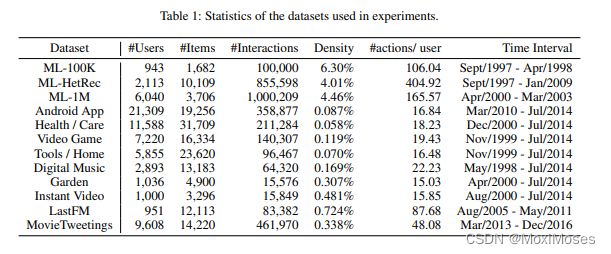
7.1 数据集
预处理:丢弃不足10个行为的用户,移除掉冷启动物品。
7.2 评估指标
hit ratio衡量预测准确率,mean reciprocal rank衡量排序质量:

MRR考虑预测结果中groundtruth item的位置:
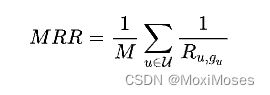
7.3 模型比较
神经网络方法:HRM,Caser
度量Embedding方法:PRME,TransRec
7.4 实验效果
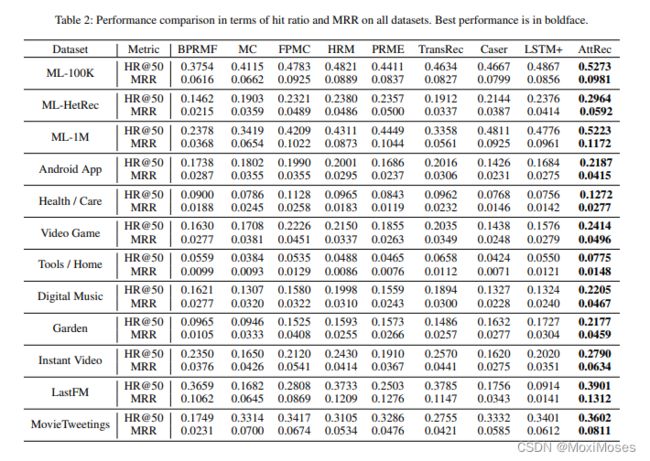
8.讨论
Self-Attention的影响:Self-Attention的效果比其他方法好
聚合方法的影响:平均方法效果最好
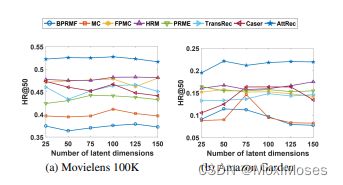
权重w的影响:它用于控制长短期兴趣的贡献。从下图a中可以发现,设置w=0说明仅考虑短期兴趣,效果比仅考虑长期兴趣w=1更好。w取值为0.2-0.4较好,说明短期兴趣在序列推荐中比较重要。

序列长度L的影响:上图b中表示合适的高度依赖于数据集的密集程度。在MovieLens数据集上,平均每个用户有超过100个行为,设置越大效果越好。然而,在稀疏数据集上,应当设置的比较小,因为随着L的增长会导致训练样本的减少。
隐式维度大小的影响:从下图中可以发现,本文模型在任何维度上均优于其他模型,更大的维度效果不一定更好,MC和Caser的表现不稳定。
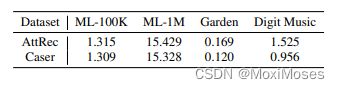
模型效率:
9.结论
这篇论文提出了一种用于序列推荐的基于self-attention的度量学习方法AttRec。它结合了用户的短期意图和长期偏好,以预测用户的下一步行动。它利用self-attention从用户最近的行为中学习用户的短期意图。最后,通过实验结果表明,AttRec可以准确捕捉用户最近行为的重要性。
深度学习
1.self-attention是什么?
可以用之前学习过的RNN来做解释,RNN网络的的输入是一个定长的向量。例如,分类网络的输入图片大小是固定的,当网络的输入变为长度可变的向量时,RNN网络就不再适用了,而Self-attention可以解决这一问题,动态地生成不同连接的权重。
2.self-attention的好处
1)self-attention的每个单元都可以捕捉到整句的信息,解决了长距离依赖学习的问题。
2)self-attention容易并行化:RNN的计算过程不是并行计算的,每个单元需要等到其他需要输入单元的信息计算后,再进行运算。有人尝试用CNN解决这个问题,但需要叠加很多层,才能捕捉长远的信息。
3)self-attention的复杂度不高,并且self-attention可以用作特征提取器和编码器。
3.模型
q, k, v是由每个单元的输出分别乘上三个不同的矩阵得到:
q:query,用来匹配其他单元。
k:key,用来被其他单元匹配。
v:value,需要被提取的信息。
下面的步骤得到每个单元的编码:
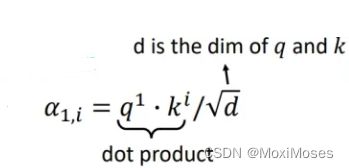
1)通过q和k计算相似度α
对每个单元,用它的query去对包括自身的所有单元的key做attention。如下图所示,它对包括自身的所有单元做attention,点乘代表相似度,d的设置是由于q和k的数值会随着他们的维度的增加而增加。
2)通过softmax计算a hat,进行归一化。
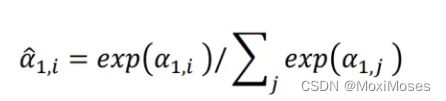
3)计算每个单元经过attention后的综合信息b
每个单元attention后的综合信息 = 这个单元对句子所有各个单元的a hat乘上各个单元的信息v的总和:
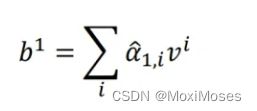
其中:这里的计算是可以并行运算得到结果的
4)为什么self-attention可以进行矩阵的并行计算?
q和k的并行化:每个q都需要和每个k进行一次运算,然后再进行一次softmax可以得到A hat。
这里能用矩阵表示的运算,就可以通过并行化加速。因此,self-attention的计算可以用矩阵计算,可以用GPU进行加速。
5)位置信息
我们需要加入位置信息,于是在前面公式的基础上,加入一个特殊的向量ei,维度和a一样。如下图所示,e其实不是学出来的,是由人为设定的,每个位置都不一样,每一个代表在第几个positon。

4.self-attention代码实现
import torch
from torch import nn
from math import sqrt
class Self_Attention(nn.Module):
# input : batch_size * seq_len * input_dim
# q : batch_size * input_dim * dim_k
# k : batch_size * input_dim * dim_k
# v : batch_size * input_dim * dim_v
def __init__(self, input_dim, dim_k, dim_v):
super(Self_Attention, self).__init__()
self.q = nn.Linear(input_dim, dim_k)
self.k = nn.Linear(input_dim, dim_k)
self.v = nn.Linear(input_dim, dim_v)
self._norm_fact = 1 / sqrt(dim_k)
def forward(self, x):
Q = self.q(x) # Q: batch_size * seq_len * dim_k
K = self.k(x) # K: batch_size * seq_len * dim_k
V = self.v(x) # V: batch_size * seq_len * dim_v
atten = nn.Softmax(dim=-1)(
torch.bmm(Q, K.permute(0, 2, 1))) * self._norm_fact # Q * K.T() # batch_size * seq_len * seq_len
output = torch.bmm(atten, V) # Q * K.T() * V # batch_size * seq_len * dim_v
return output
x = torch.randn(4, 3, 2)
print(x)
print(x.size())
self_attention = Self_Attention(2, 4, 5)
res = self_attention(x)
print(res)
print(res.size())
输出结果:
tensor([[[-0.4794, 0.4340],
[ 0.5843, 0.4087],
[-0.5079, 0.3864]],
[[ 0.9442, 1.3168],
[-0.2837, 0.7687],
[ 0.5011, 0.4151]],
[[ 0.0819, 1.4348],
[ 0.1038, 0.6332],
[-1.0183, 1.0199]],
[[-0.6516, 0.0239],
[ 1.3476, -1.7734],
[ 0.2902, 0.9868]]])
torch.Size([4, 3, 2])
tensor([[[ 0.3162, -0.3108, 0.0127, -0.1340, 0.0417],
[ 0.3196, -0.3107, 0.0286, -0.1252, 0.0493],
[ 0.3160, -0.3108, 0.0120, -0.1344, 0.0414]],
[[ 0.3989, -0.3825, -0.1991, -0.3072, -0.0168],
[ 0.4234, -0.4039, -0.2630, -0.3592, -0.0346],
[ 0.4163, -0.3973, -0.2405, -0.3416, -0.0278]],
[[ 0.5054, -0.4250, -0.0657, -0.2672, 0.0727],
[ 0.5136, -0.4308, -0.0770, -0.2780, 0.0709],
[ 0.5199, -0.4371, -0.0990, -0.2951, 0.0640]],
[[ 0.3259, -0.3277, -0.0812, -0.1990, 0.0069],
[ 0.3233, -0.3229, -0.0545, -0.1806, 0.0168],
[ 0.1378, -0.2116, 0.0181, -0.0528, -0.0153]]],
grad_fn=<BmmBackward0>)
torch.Size([4, 3, 5])
总结
谈谈自己对self-attention与attention之间差异的理解:注意力机制中Q代表自己,K代表别人,目的是找自己的哪个部分与别人相关性更高,而自注意力机制中Q和K都是自己,目的是找自己的哪个部分与最终结果相关性更高。具体来说,可以用A和B为例,注意力机制寻找的是A和B之间的关系,自注意力机制寻找的是A与A自身内部的关系。假如A是一段话:“我喜欢你”,自注意力机制就是寻找“我”与“我”、“喜”、“欢”、“你”之间的关系,最终形成一个矩阵。