信息抽取总结
一、知识图谱与信息抽取
1.1 知识与知识图谱
知识图谱(Knowledge Graph)以结构化的形式描述客观世界中概念、实体及其之间的关系,将互联网的信息表达成更接近人类认知世界的形式,提供了一种更好地组织、管理和理解互联网海量信息的能力。知识图谱本质上是以三元组结构(主语-谓语-宾语)表示实体及实体关系的语义网络,谷歌公司于2012年重新提出了知识图谱的概念以保持其在智能搜索引擎的领先地位。时任谷歌副总裁阿密特·辛格(Amit Singhal)指出知识图谱是“Things,Not Strings”,在此之前搜索引擎是通过爬取网页并基于关键词返回网页排序结果,而基于知识图谱得到的是与关键词有关联的表示真实世界中的实体的图文描述信息。
在行业的实践中之所以对知识图谱期望太高,是因为人类知识和知识图谱这两个概念容易引起歧义:人类知识包括原理、技能等高级知识,而知识图谱源自语义网络、本体论,借助RDF三元组及模式(schema)的形式构建计算机可理解、可计算的实体及实体之间关联的事实性知识库,即图谱可形象地称作“万事通”而非“科学家”。
1.2 知识获取、知识抽取与信息抽取的区别与联系
行业用户往往希望,结构化的知识靠AI自动化构建,不用介入任何人工,即可产生低成本、高质量的知识,然而这些是不切实际的幻想。因此,这里要正本清源,辨析知识图谱的常规的获取知识方式。
知识获取是组织从某种知识源中总结和抽取有价值的知识的活动,我们认为,根据该定义,知识获取强调的是获取知识的一种活动,包括从结构化、半结构化和非结构化的信息资源中提取出计算机可理解和计算的结构化数据,以供进一步分析和利用。因此,其范围应包括知识抽取和信息抽取。
知识抽取,即从不同来源、不同结构的数据中进行知识提取,形成知识(结构化数据)存入到知识图谱。信息抽取,即从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术[5]。
数据、信息和知识的关系为:信息是存在于数据(数字、文本、图像等)中的反映客观世界的实体,通过提炼、加工建立实体之间的联系形成了知识,知识是对世界客观规律的归纳和总结。因此,知识抽取在方法上包括了信息抽取和ETL(数据仓库),但方法不局限于结构化信息的生成或关系数据库模式(schema)的直接转换,还需借助本体库或自动方法归纳新的模式。
在本文中,知识抽取和信息抽取的内涵与外延近乎等价,两者都是应用自然语言技术从文本获取实体、关系、属性和事件知识。
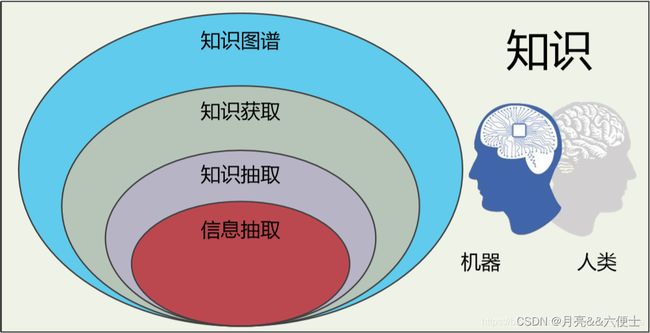
总的来说,知识、知识图谱、知识获取、知识抽取、信息抽取这些概念逐层递进,以一张韦恩图表示(如图1所示):知识的表示、获取和处理是人类特有的能力,知识图谱架起了一座基于人类知识和计算机获取认知能力的桥梁,知识获取涵盖了产生机器可理解的知识的活动,知识抽取强调通过数据模式组织三元组知识,而信息抽取是借助自然语言处理技术生产知识的能力。信息抽取是知识工程、大数据、机器学习、自然语言处理的交叉技术。下文将重点探讨信息抽取在知识图谱的应用与实践。
二、融合信息抽取的知识图谱构建范式
近年来,自然语言处理技术的飞速发展尤其是深度迁移学习技术给方兴未艾的知识图谱注入了一针“强心剂”。预训练语言模型性能的提升降低了从海量的非结构化文本中获取知识的成本,推动了知识图谱在行业企业的落地应用。
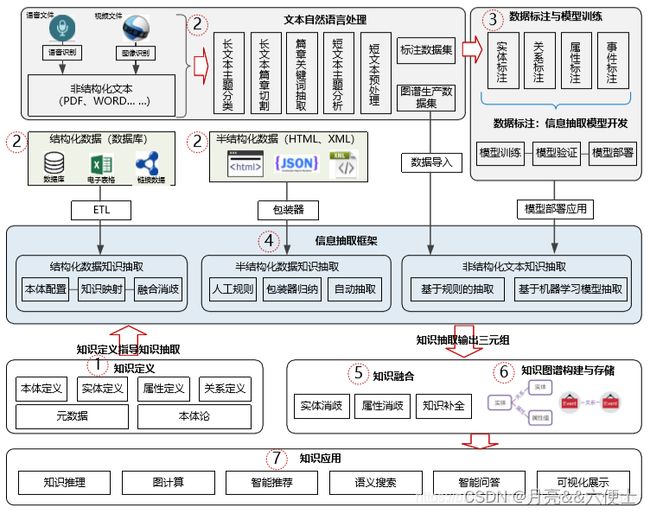
如图所示的体系架构,百分点公司在行业知识图谱的实践应用中,信息抽取技术占据着核心地位。行业知识图谱构建的生命周期历经知识定义、知识获取、知识融合、知识存储、知识应用多个环节,这些过程的每一步都需要专业的信息处理技术与技能才能完成。下面重点阐述信息抽取相关的知识定义及知识获取环节内容。
2.1 知识定义
传统的知识工程研究领域人们以本体、主题词表、元数据、数据模式来建立结构化的知识,在本文知识定义泛指结构化的数据模型,即通过构建图谱模式(schema)规范数据层的表达与存储。数据模型是线状或网状的结构化知识库的概念模板,知识图谱一般采用资源描述框架(RDF)、RDF模式语言(RDFS)、网络本体语言(OWL)及属性图模型。
(1)RDF模型
RDF在形式上以三元组表示实体及实体之间的关系,反映了物理世界中具体的事物及关系
(2)RDFS模型
RDFS在RDF的基础上定义了类、属性以及关系来描述资源,并且通过属性的定义域和值域来约束资源。RDFS在数据层的基础上引入了模式层,模式层定义了一种约束规则,而数据层是在这种规则下的一个实例填充,如图所示。

(3)OWL模型
OWL是对RDFS关于描述资源词汇的一个扩展,OWL中添加了额外的预定义词汇来描述资源,具备更好的语义表达能力。
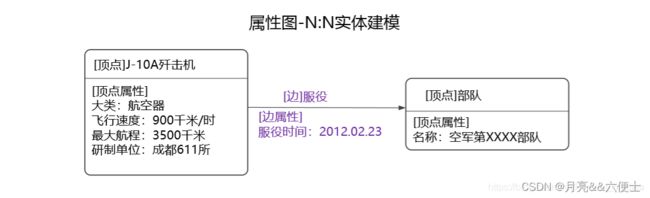
(4)属性图
属性图数据模型由顶点、边及其属性构成,图数据库通常是指基于属性图模型的图数据库。属性图与RDF图最大的区别在于:RDF图可以更好地支持多值属性;RDF图不支持两顶点间多个相同类型的边;RDF图不支持边属性。
 知识定义与信息模型的概念类似,可借鉴元数据和本体论技术,描述定义域的实体类型及其属性、关系和实体上的允许操作,常见的流行方法包括自上而下(Top-down)的构建方式、自下而上(Bottom-up)的构建方式。自上而下,即由行业专家预先定义图谱模式,再以模式组织数据层资源建设;自下而上,即通过信息抽取技术从文本中抽取出实体,再依赖大数据挖掘、机器学习技术分析实体的语义关联关系来构建模式。自上而下显然更加准确,然而自下而上代表着数据驱动的自动图谱构建模式,不论是哪一种方法知识定义应是信息抽取的前提条件。
知识定义与信息模型的概念类似,可借鉴元数据和本体论技术,描述定义域的实体类型及其属性、关系和实体上的允许操作,常见的流行方法包括自上而下(Top-down)的构建方式、自下而上(Bottom-up)的构建方式。自上而下,即由行业专家预先定义图谱模式,再以模式组织数据层资源建设;自下而上,即通过信息抽取技术从文本中抽取出实体,再依赖大数据挖掘、机器学习技术分析实体的语义关联关系来构建模式。自上而下显然更加准确,然而自下而上代表着数据驱动的自动图谱构建模式,不论是哪一种方法知识定义应是信息抽取的前提条件。
2.2 知识获取
按数据源类型划分,知识获取包括从结构化、半结构化和非结构化的数据中获取知识。
从结构化数据中获取知识,需把关系数据库中的数据转换成RDF形式的知识,可使用开源工具D2RQ等将关系数据库转换为RDF,但难点在于难以自动与图谱模式结合与映射,需要依赖人工编写映射规则;从半结构化的网页数据获取知识主要采用包装器方法,而对于行文格式稳定的文本可视作半结构化数据,可通过格式解析、基于规则的方法进行抽取。
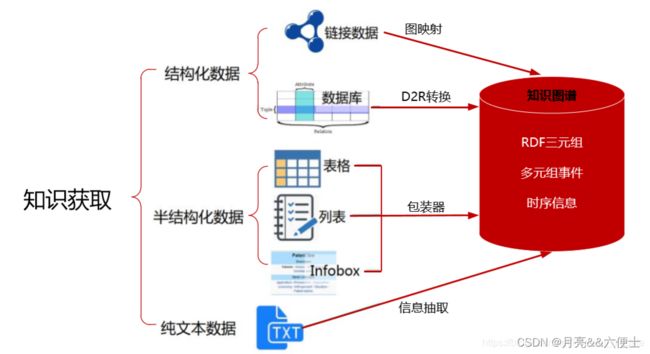
对于非结构化的文本数据,抽取的知识主要包括实体、关系、属性。
对应的研究问题有四个:一是实体抽取,也即命名实体识别,实体包括概念、组织机构、人名、地名、时间等;二是关系抽取,即两个实体之间的关联性知识等,包括上下位、类属关系等;三是属性抽取,即实体或关系的特征信息,关系反映实体与外部的联系,而属性体现实体的内部特征;四是事件抽取,事件是发生在某个特定时间点或时间段、某个特定地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变。
非结构化数据的抽取问题,研究的人比较多,对于具体的语料环境,采取的技术也不尽相同。对于纯文本一般按照篇、章、段、句进行文本切割,基于主题词对文本分类、聚类预处理,并由人工开展数据标注与模型训练,最后集成多种信息抽取模型抽取知识。
三、基于信息抽取算法构建知识图谱
3.1结构化信息抽取
行业知识图谱的构建过程往往需要将业务系统的部分关系型数据库的数据抽取出来,并转换为RDF模型或属性图模型的形式存入图谱数据库中,这种从关系型数据库接入数据、预处理并映射为图谱模式的抽取方式称为结构化信息抽取。
W3C为此制定了两个知识映射标准语言:R2RML及直接映射(DM),DM和R2RML映射语言用于定义关系数据库中的数据如何转换为RDF数据的各种规则,具体包括URI的生成、RDF类和属性的定义、空节点的处理、数据间关联关系的表达等[9]。
直接映射将关系型数据库中的一张表映射为RDF的类(Class),表中的列映射为属性(Property),表的一行映射为一个资源或实体并创建资源标识符,单元格值映射为属性值[9]。直接映射可将关系数据库表结构和数据直接转换为RDF图,但直接映射仅仅提供简单转换能力。而R2RML映射语言可灵活定制从关系型数据库数据实例转换为RDF数据集的映射规则,符合R2RML映射算法的工具输入是关系数据库检索数据的逻辑表,逻辑表通过三元组映射转换为具有相同数据模式的RDF并作为输出结果。
3.2半结构化信息抽取
半结构化数据是一种特殊的结构化数据形式,该形式的数据不符合关系数据库或其他形式的数据表形式结构,但又包含标签或其他标记来分离语义元素并保持记录和数据字段的层次结构[9]。针对网页数据的信息抽取技术较为成熟,可依网页结构化的不同程度分别采用人工方法、半自动或全自动的方法开发包装器进行信息抽取。
基于有监督学习的包装器归纳方法,首先从已标注的训练数据中学习网页信息抽取规则,然后对具有相同结构的网页数据进行抽取,一般的开发流程遵循“网页清洗、数据标注、包装器空间生成、评估”四个步骤,该方法依赖人工长期维护更新包装器。手工方法开发包装器首先通过人工分析网页的结构和代码,并编写网页的数据抽取表达式;表达式的形式一般可以是XPath表达式、css选择器的表达式等,该方法适合简单、结构稳定的网站的抽取。
3.3非结构化信息抽取
- 信息抽取框架
如前文所述,非结构化文本的信息抽取主要包括命名实体识别、属性抽取、关系抽取、事件抽取等四个任务。命名实体识别是知识图谱构建和知识获取的基础和关键,属性抽取可看做实体和属性值之间的一种名词性关系而转化为关系抽取,因此信息抽取可归纳为实体抽取、关系抽取和事件抽取三大任务。
- 命名实体识别
目前为止,命名实体识别主流方法可概括为:基于词典和规则的方法、基于统计机器学习的方法、基于深度学习、迁移学习的方法等,如图所示。在项目实际应用中一般应结合词典或规则、深度学习等多种方法,充分利用不同方法的优势抽取不同类型的实体,从而提高准确率和效率。在中文分词领域,国内科研机构推出多种分词工具(基于规则和词典为主)已被广泛使用,例如哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba分词等。
基于统计机器学习的方法可细分为两类:第一类,分类方法,即首先识别出文本中所有命名实体的边界(分词),再对这些命名实体进行分类;第二类,序列化标注方法,即对于文本中每个词可以有若干个候选的类别标签,每个标签对应于其在各类命名实体中所处的位置,通过对文本中的每个词进行序列化的自动标注(也即分类),再将自动标注的标签进行整合,最终获得有若干个词构成的命名实体及其类别。序列化标注曾经是最普遍并且有效的方法,典型模型包括条件随机场(CRF)、隐马尔可夫模型(HMM)、最大熵马尔可夫模型(MEMM)、最大熵(ME)、支持向量机(SVM)等。与普通的分类问题相比,序列标注问题中当前标签的预测不仅与当前的输入特征相关,还与之前的预测标签相关,即预测标签序列是有强相互依赖关系的。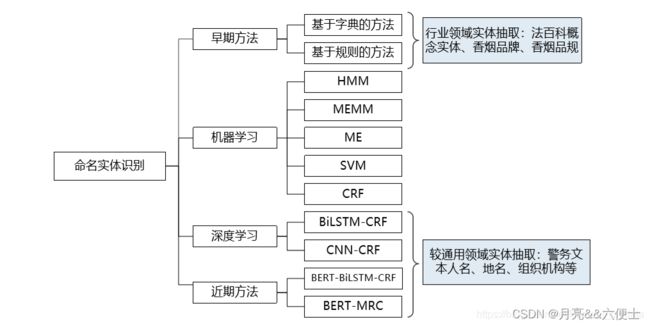
深度学习、迁移学习使用低维、实值、稠密的向量形式表示字、词、句,再使用RNN/CNN/注意力机制等深层网络获取文本特征表示,避免了传统命名实体识别人工特征工程耗时耗力的问题,且得到了更好的效果,目前常用的框架方法有BiLSTM-CRF、BERT-CRF/BERT-BiLSTM-CRF。
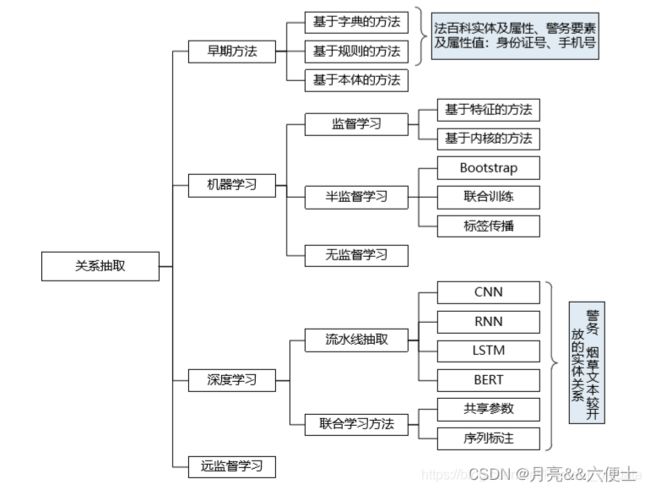
3.4 关系抽取
从前文可知,关系抽取指三元组抽取,实体间的关系形式化地描述为关系三元组(主语,谓语,宾语),其中主语和宾语指的是实体,谓语指的是实体间的关系。早期的关系抽取方法包括基于规则的关系抽取方法、基于词典驱动的关系抽取方法、基于本体的关系抽取方法。基于机器学习的抽取方法以数据是否被标注作为标准进行分类,包括:有监督的关系抽取算法、半监督的关系抽取算法、无监督的关系抽取算法,如图所示。