深度学习 - VGG16介绍及预训练神经网络的使用
这里写自定义目录标题
-
- 什么是VGG开头神经网络
- 调用预训练模型(代码)
-
- 加载预训练网络
- 构建完整的模型
- 模型的初步训练(训练自定义层)
- 对模型进行微调(训练部分VGG16层及自定义层)
官方所有的预训练网络说明:链接
- 可以查询到所有可用的预训练网络及其使用方法
- 包含参数说明
在Keras中提供了以下图像分类模型的代码和预训练的权重:

均可以使用keras.applications 模块进行导入:(可以从下边复制)
from keras.applications.xception import Xception
from keras.applications.vgg16 import VGG16
from keras.applications.vgg19 import VGG19
from keras.applications.resnet50 import ResNet50
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_resnet_v2 import InceptionResNetV2
from keras.applications.mobilenet import MobileNet
from keras.applications.densenet import DenseNet121
from keras.applications.densenet import DenseNet169
from keras.applications.densenet import DenseNet201
from keras.applications.nasnet import NASNetLarge
from keras.applications.nasnet import NASNetMobile
from keras.applications.mobilenet_v2 import MobileNetV2
接下来以VGG16神经网络为例进行说明
什么是VGG开头神经网络
VGG全称是Visual Geometry Group,属于牛津大学科学工程系,其发布了一些列以VGG开头的卷积网络模型,可以应用在人脸识别、图像分类等方面,分别从VGG16~VGG19。
VGG研究卷积网络深度的初衷是想搞清楚卷积网络深度是如何影响大规模图像分类与识别的精度和准确率的,最初是VGG-16, 号称非常深的卷积网络全称为(GG-Very-Deep-16 CNN) 。
VGG在加深网络层数同时为了避免参数过多,在所有层都采用3x3的小卷积核,卷积层步长被设置为1。VGG的输入被设置为224x244大小的RGB图像,在训练集图像上对所有图像计算RGB均值,然后把图像作为输入传入VGG卷积网络,使用3x3或者1x1的filter,卷积步长被固定1。
VGG模型架构
VGG全连接层有3层,根据卷积层+全连接层总数目的不同可以从VGG11 ~ VGG19,最少的VGG11有8个卷积层与3个全连接层,最多的VGG19有16个卷积层+3个全连接层,此外VGG网络并不是在每个卷积层后面跟上一个池化层,还是总数5个池化层,分布在不同的卷积层之下.
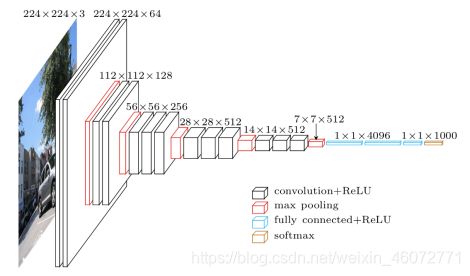
VGG的作者在论文中将它称为是Very Deep Convolutional Network,如上图所示的VGG16网络带权层就达到了16层,这在当时已经很深了。网络的前半部分,每隔2~3个卷积层接一个最大池化层,4次池化共经历了13个卷积层,加上最后3个全连接层共有16层,也正因此我们称这个网络为VGG16。
VGG16不仅结构清晰,层参数也很简单。所有的卷积层都采用3x3的卷积核,步长为1;所有池化层都是2x2池化,步长为2。正因为此,我们看到图片尺寸变化规律,从224x224到112x112等,直到最后变成7x7。同时我们注意到特征图通道的数量也一直在加倍,从64到128最终变成512层。因此VGG16结构图画出来非常美观,实现起来也很规整。

Conv: 表示卷积层
FC: 表示全连接层(dense)
Conv3: 表示卷积层使用3x3 filters
Conv3-64: 表示深度64
maxpool: 表示最大池化
在实际处理中还可以对第一个全连接层改为7x7的卷积网络,后面两个全连接层改为1x1的卷积网络,这个整个VGG就变成一个全卷积网络FCN。
VGG在加深CNN网络深度方面首先做出了贡献,但是VGG也有自身的局限性,不能无限制的加深网络,在网络加深到一定层数之后就会出现训练效果褪化、梯度消逝或者梯度爆炸等问题,总的来说VGG在刚提出的时候也是风靡一时,在ImageNet竞赛数据集上都取得了不错的效果。
VGG有两个很大的缺点
- 网络架构weight数量相当大,很消耗磁盘空间。
- 训练非常慢由于其全连接节点的数量较多,再加上网络比较深,VGG16有533MB+,VGG19有574MB。这使得 部署VGG比较耗时。
调用预训练模型(代码)
重要参数
include_top:是否包括顶部的全连接层。weights:None代表随机’imagenet’初始化,代表加载在ImageNet上预训练的权值。input_tensor:可选,Keras张量作为模型的输入(即layers.Input()输出的tensor)。input_shape:可选,输入尺寸元组,当仅include_top=False时有效值(否则输入形状必须是(299, 299, 3),因为预训练模型是以这个大小训练的)它必须拥有3个输入通道,且宽高必须不小于71例如。(150, 150, 3)是一个合法的输入尺寸。pooling:可选,当include_top为False时,该参数指定了特征提取时的池化方式。- None 代表不池化,直接输出最后一层卷积层的输出,该输出是一个4D张量。
- ‘avg’ 代表平均值平均池化(GlobalAveragePooling2D),相当于在最后一层卷积层后面再加一层平均池化层,输出是一个2D张量。
- ‘max’ 代表最大池化。
classes:可选,图片分类的类别数,仅当include_top为和True不加载预训练权值时可用。
加载预训练网络
第一次使用需要下载,可能会比较慢;
如果已下载,则可直接调用。
# 读取内置神经网络VGG16
conv_base = keras.applications.VGG16(weights='imagenet', include_top=False)
>>>Downloading data from https://github.com/fchollet/deep-learning
models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58892288/58889256 [==============================] - 774s 13us/step
可以通过conv_base.summary()观察,VGG16模型架构
print('VGG16层数:', len(conv_base.layers))
>>>VGG16层数: 19
构建完整的模型
构建序列模型 ==> 添加VGG16模型(输入) ==> 添加全局平均化层 ==> 添加全连接层(输出)
# 构建模型,增加全连接层
model = keras.Sequential()
model.add(conv_base)
model.add(keras.layers.GlobalAveragePooling2D())
model.add(keras.layers.Dense(512, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid’))
模型的初步训练(训练自定义层)
训练步骤
- 在预训练卷积基上添加自定义层
- 使用
conv_base.trainable = False冻结卷积基所有层 - 训练添加的分类层
- 解冻卷积基的一部分层
- 联合训练解冻的卷积层和添加的自定义层
在初步训练中要锁定卷积基的参数值,因为我们自己加入的全连接层的参数是随机初始化的,在初步训练中会影响卷积基的参数,导致降低准确率。
conv_base.trainable = False # 使得VGG卷积中的参数不可训练
# 因为在训练模型是,最后的两层全连接层是随机初始化的参数,有可能会影响到VGG16卷积层的参数
# 优化模型
model.compile(optimizer=keras.optimizers.Adam(lr=0.001),
loss='binary_crossentropy',
metrics=['acc’])
# 进行训练
history = model.fit( train_image_ds,
steps_per_epoch=train_count//BATCH_SIZE,
epochs=5,
validation_data=test_image_ds,
validation_steps=test_count//BATCH_SIZE
)
>>>Train for 62 steps, validate for 31 steps
Epoch 1/5
62/62 [==============================] - 407s 7s/step - loss: 0.6301 - acc: 0.6190 - val_loss: 0.5986 - val_acc: 0.6552
...
对模型进行微调(训练部分VGG16层及自定义层)
所谓微调:冻结模型库的底部的卷积层,共同训练新添加的分类器层和顶部部分卷积层。这允许我们“微调”基础模型中的高阶特征表示,以使它们与特定任务更相关。
只有分类器已经训练好了,才能微调卷积基的顶部卷积层。如果有没有这样的话,刚开始的训练误差很大,微调之前这些卷积层学到的表示会被破坏掉。
我们只对最后卷积基中的最后三层的参数进行解冻,在微调中对这些解冻的函数进行优化
# 只保留卷积基最后三层为解冻状态,其他层重新锁定
for layer in conv_base.layers[-3:]:
layer.trainable = True
微调要重新构建优化器,并且调用训练函数
# 设置优化器
model.compile(optimizer=keras.optimizers.Adam(lr=0.0005/10), # 注意在微调中需要降低学习率
loss='binary_crossentropy',
metrics=['acc’])
initial_epochs = 5 # 初步训练模型时的训练次数
fine_epochs = 4 # 微调的训练次数
total_epochs = initial_epochs + fine_epochs # 总次数
history = model.fit(
train_image_ds,
steps_per_epoch=train_count//BATCH_SIZE,
epochs=total_epochs, # 总训练次数
initial_epoch=initial_epochs, # 传入微调训练次数
validation_data=test_image_ds,
validation_steps=test_count//BATCH_SIZE
)
>>>Train for 62 steps, validate for 31 steps
Epoch 6/9
62/62 [==============================] - 518s 8s/step - loss: 0.5063 - acc: 0.7253 - val_loss: 0.5549 - val_acc: 0.6905
...
到此,模型训练✅