论文理解记录:Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration
论文核心
论文剪枝对象是卷积核,与其他论文不同点在于作者思考了 norm-wise 作为卷积核重要性判断的弊端,并提出了 FPGM 算法,该算法先计算出所有卷积核的几何中心(作者把卷积核当作多维空间中的点),然后找到距离几何中心近的卷积核,并删除。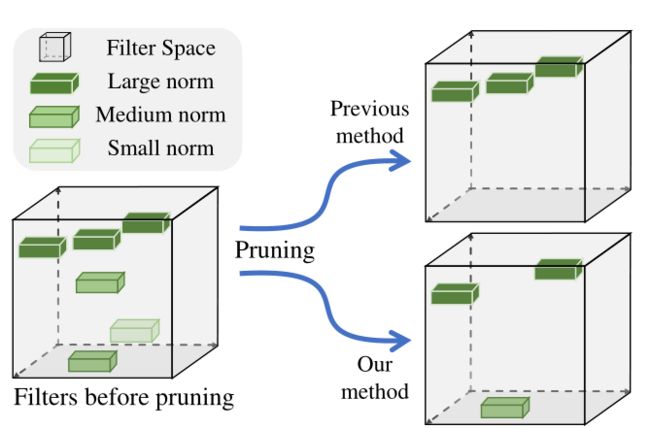
论文细节品读
norm-wise 评判标准的不足:
作者提出使用 nrom-wise 需要满足两个条件如下图所示,下图表示同一层中卷积核 l 1 l1 l1-nrom 或 l 2 l2 l2-norm的分布情况,然后使用 norm-wise 评判标准需要满足:卷积核的 norm 方差要大,这便于剪枝;待剪枝的卷积核(即norm 相对较小的卷积核)的 norm 要趋近于0。
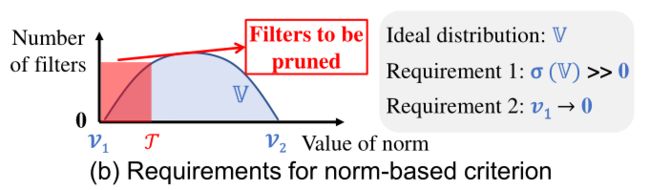
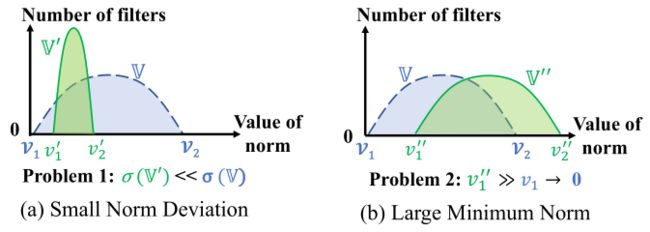
使用 norm-wise 剪枝需同时满足以上两个要求,然而现实情况可能如下图所示,左图表示 norm 分布在很狭窄的范围,右图表示相对较小的 norm 值也远大于0。
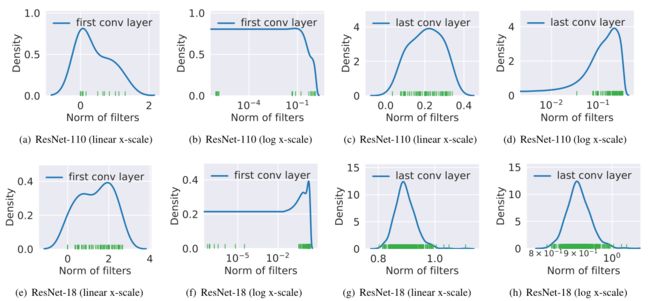
论文作者给出了两个例子,一个是 resnet110 在数据集 CIFAR-10上训练后卷积核 norm 值分布的结果,一个是 resnet18 在数据集 ILSVRC-2012 上训练后卷积核 norm 值分布结果,可以看出 norm 值分布不满足 norm-wise 使用的前提条件。
FPGM 算法:
计算几何中位数是一个很耗时的问题,论文作者在这里没有用传统的逼近法来求几何中位数,而是转化为求哪个卷积核离其他卷积核距离总和最小,则这个卷积核就是几何中心。下面是伪代码,了解一下大致思路。

结合作者提供的源码更好理解作者的思路:
def get_filter_similar(self, weight_torch, compress_rate, distance_rate, length, dist_type="l2"):
codebook = np.ones(length)
if len(weight_torch.size()) == 4:
filter_pruned_num = int(weight_torch.size()[0] * (1 - compress_rate))
similar_pruned_num = int(weight_torch.size()[0] * distance_rate)
weight_vec = weight_torch.view(weight_torch.size()[0], -1)
if dist_type == "l2" or "cos":
# weight_vec.shape = [输出通道数, 输入通道数*kernel_width*kernel_height]
# 对 weight_vec第一维求欧氏距离,也就是求每个卷积核的l2
norm = torch.norm(weight_vec, 2, 1)
norm_np = norm.cpu().numpy()
elif dist_type == "l1":
norm = torch.norm(weight_vec, 1, 1)
norm_np = norm.cpu().numpy()
filter_small_index = []
filter_large_index = []
filter_large_index = norm_np.argsort()[filter_pruned_num:]
filter_small_index = norm_np.argsort()[:filter_pruned_num]
# distance using numpy function
indices = torch.LongTensor(filter_large_index).cuda()
# 使用index_select indices必须为LongTensor类型
weight_vec_after_norm = torch.index_select(weight_vec, 0, indices).cpu().numpy()
# for euclidean distance
if dist_type == "l2" or "l1":
# 该结果为一个斜对称矩阵,矩阵每一行表示该卷积核到其他卷积核的欧氏距离
similar_matrix = distance.cdist(weight_vec_after_norm, weight_vec_after_norm, 'euclidean')
elif dist_type == "cos": # for cos similarity
similar_matrix = 1 - distance.cdist(weight_vec_after_norm, weight_vec_after_norm, 'cosine')
# 矩阵每一行求和,表示该卷积核到其他卷积核的总距离
similar_sum = np.sum(np.abs(similar_matrix), axis=0)
# for distance similar: get the filter index with largest similarity == small distance
similar_large_index = similar_sum.argsort()[similar_pruned_num:]
similar_small_index = similar_sum.argsort()[: similar_pruned_num]
similar_index_for_filter = [filter_large_index[i] for i in similar_small_index]
print('filter_large_index', filter_large_index)
print('filter_small_index', filter_small_index)
print('similar_sum', similar_sum)
print('similar_large_index', similar_large_index)
print('similar_small_index', similar_small_index)
print('similar_index_for_filter', similar_index_for_filter)
kernel_length = weight_torch.size()[1] * weight_torch.size()[2] * weight_torch.size()[3]
for x in range(0, len(similar_index_for_filter)):
codebook[
similar_index_for_filter[x] * kernel_length: (similar_index_for_filter[x] + 1) * kernel_length] = 0
print("similar index done")
else:
pass
return codebook
为了帮助大家理解,这里我把关键点提炼出来:
- 按给出的压缩率,将卷积核分成待剪枝部分和保留部分(这里区 分待剪枝部分和保留部分依旧是采用的 norm 方法)
- 计算每个卷积核到其他卷积核的欧氏距离
- 每个卷积核到其他卷积核距离求和,到其他卷积核距离之和最小的卷积核,为几何中心
可视化分析:
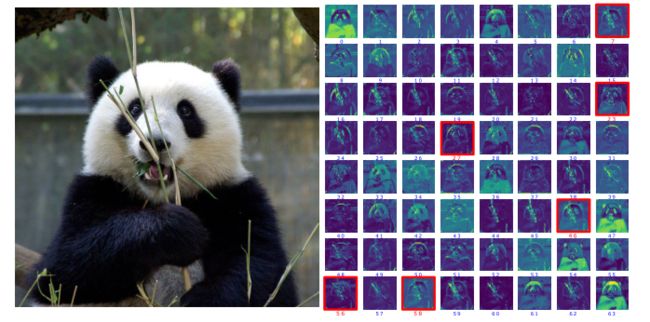
论文作者将 resnet50 第一层卷积后的 feature map 进行了可视化操作,然后找到对应的卷积核的输出通道,观察分析。红色框框为被删掉的卷积核对应的 feature map ,其实个人感觉这分析有道理,但是道理又不那么多…如果删除的是其他卷积核,估计也能找出相应的理由。不过可视化分析确实是挺好玩的一个流程。
总结
该篇论文剪枝方案也是基于规则剪枝的,至于各种规则剪枝,则各有各的道理,最后好效果才是硬道理。在论文的源码中,还用到了软剪枝方案,这就涉及到了该篇论文作者另一篇论文了。后续会继续更新该篇论文的实验复现情况。