Effectiveness of Arbitrary Transfer Sets for Data-free Knowledge Distillation
Effectiveness of Arbitrary Transfer Sets for Data-free Knowledge Distillation
我们研究任何任意转移集对知识提炼任务的有效性,尽管它与原始训练数据无关。如果证明是有效的,这样的数据集实际上可以用来设计重要的、通常是强大的KD任务的基线,同时为我们节省了现有的无数据蒸馏方法所产生的合成转移集的大量开销。这对于文本/图像领域尤其如此,因为在该领域,很容易从无处不在的公开来源中收集大量未标记的任意数据。更重要的是,这种调查可以发现对蒸馏过程机制的重要见解。
因此,在这项工作中,我们考虑在(i)随机噪声输入,(ii)任意合成数据集,和(iii)任意自然数据集向组成转移集。我们观察到任意数据样本可能不会均匀地投影到教师的学习分类区域中。换言之,任意数据样本可能不会均匀地投影到教师的学习分类区域中。分类区域的不平衡导致学生在蒸馏过程中过度拟合分类边界。也就是说,它不能保留从原始训练数据中学习到的类决策边界,从而严重影响了学生的泛化能力。这些观察结果导致了这样一个假设:一个理想的转移集应该平等地代表教师模型的所有分类区域,这样可以最小化决策边界的扭曲,从而有助于实现有效的知识转移。换言之,为了成功地将教师的学习传授给学生,任意迁移集需要“目标类别平衡”。
综上所述,本工作的贡献如下:
- 我们在文献中首次表明,在 "无数据 "的情况下,可以有效利用与目标数据集无关的任意转移集来完成知识提炼的任务。
- 为了最大限度地发挥使用这种转移集的蒸馏功效,我们提出了一种简单而有效的方法,即使其 “类平衡”。
- 我们在MNIST、FMNIST、CIFAR-10和CIFAR-100等多个基准数据集上实证了所提出的方法的有效性,因为我们实现了与最先进的无数据蒸馏方法相当的性能。
3. Class-balanced Arbitrary Transfer Sets
3.2. KD with Arbitrary Transfer Set
在缺乏原始培训数据的情况下(参见第。1对于这种情况)多种方法(例如[15,17,2,1])组成合成转移集并实现有效蒸馏。然而,很明显(图1(a))这些样本在视觉上与训练样本非常不同,因此实际上可能不在数据流形上。
从这些观察出发,我们考虑研究由任意样本组成的转移集对进行KD的有效性。也就是说,如果转移集是通过从有限的公开可用数据集中随机挑选样本组成的,而不是精心制作或选择。
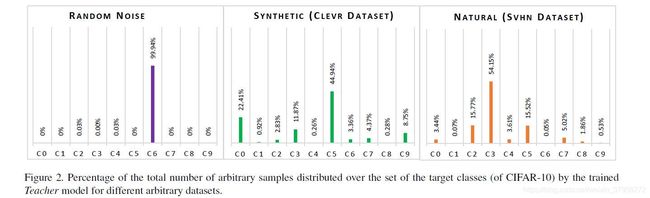
当我们构造一个转移集时,通常我们试图确保教师的所有分类区域都有样本。然而,任意组合的传输集不太可能具有代表数据分布的所有分类区域的样本。这意味着,教师预测的标签分布可能极不平衡。因此,使用任意数据作为转移集的学生模型学习的决策边界与使用原始训练样本学习的决策边界(即教师学习的边界)相比,将被扭曲。例如,图2显示了在CIFAR-10上训练的AlexNet教师预测的三种不同任意数据集的标签分布:随机噪声、Clevr和SVHN。可以注意到,这些分布远非均匀。这可能是由于预先训练的深度模型在任意转移集上标记的分类区域不成比例。显然,任意数据不太可能保留使用原始训练数据学习到的相同的类边界。因此,随机组成的转移集并不是进行提炼的理想选择(第4节)。
鉴于这样的重要观察,我们提出了一种简单而有效的策略,以确保转移集中所有分类区域的表示,这有助于减轻决策边界的失真。在组成任意转移集的同时,我们通过设计强制其在目标标签集上具有更接近于统一的标签分布。请注意,预测的标签仍然会与视觉模式完全无关,也就是说,即使对于相同的预测标签,人们可能也不会期望任意转移集中的数据点与原始训练集之间有任何语义/视觉相似性。尽管是不相关的样本,我们的目标是让这些样本均匀地跨越所有分类区域,从而形成’目标类平衡’的任意转移集。

算法1:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vdXuexTG-1616124341574)(003.jpg)]
算法1(也是图1(b))显示了利用我们的假设,从免费提供的无标签数据集库中组成这样一个转移集的步骤。请注意,在有限的任意样本供给下,可能无法得到精确一致的预测标签分布。然而,这里的目标是小心翼翼地避免前述随机组成的极端不平衡。不同于现有的无数据KD方法,如[17,4,1],我们不产生任何合成样本,并使用现有的无标签数据集的原始形式。在组成任意转移集的同时,我们只需要对每个样本通过教师模型进行一次正向传递,而且不涉及反向传播,这使得我们提出的算法的计算密集度大大降低,特别是与现有方法相比[17,4,1]。当得到迁移集 ( D ‾ ) (\overline D) (D)后,我们对学生模型进行蒸馏:
到迁移集 ( D ‾ ) (\overline D) (D)后,我们对学生模型进行蒸馏:
