Detectron2入门代码教程——以Faster RCNN在自定义数据集上目标检测为例
文章目录
- Detectron2介绍
- 代码解读
-
- 准备数据集
- 训练
- 验证
- 参考资料
Detectron2介绍
Detectron2是Facebook AI Research的下一代库,提供最先进的检测和分割算法。它是Detectron和maskrcnn-benchmark的继承者。它支持Facebook中的许多计算机视觉研究项目和生产应用。
简单来说,Detectron2是一个提供了简单的快速实现Facebook中的许多计算机视觉研究成果的框架。想要看看具体支持哪些成果可以看看他们的Model Zoo,以及github仓库。
本文将以搭建Faster RCNN完成目标检测Detection为例,数据集使用更加具有泛用性的自定义数据集。
代码解读
首先导入一系列需要用到的包。
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
# import some common libraries
import numpy as np
import os, json, cv2, random
# import some common detectron2 utilities
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
from detectron2.structures import BoxMode
from tqdm import tqdm
准备数据集
由于是自定义数据集,所以需要完成数据集的注册。
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in tqdm(enumerate(imgs_anns.values())):
# if idx > 100:
# break
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"category_id": 0,
}
objs.append(obj)
record["annotations"] = objs
# print("record")
# print(record)
dataset_dicts.append(record)
return dataset_dicts
for d in ["train", "val"]:
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("/home/faster_rcnn/datasets/balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
这里定义了一个函数get_balloon_dicts,它被DatasetCatalog.register使用。
该函数接收可以提供 数据集图片和标注文件的字符串信息,输出一个格式化后的标注列表信息。
下面给出格式化前标注文件中某个元素的格式为例:
"24_Soldier_Firing_Soldier_Firing_24_281": {
"fileref": "",
"size": 0,
"filename": "24_Soldier_Firing_Soldier_Firing_24_281.jpg",
"base64_img_data": "",
"file_attributes": {},
"regions": {
"0": {
"shape_attributes": {
"name": "polygon",
"all_points_x": [
387,
401
],
"all_points_y": [
300,
315
]
},
"region_attributes": {}
},
"1": {
"shape_attributes": {
"name": "polygon",
"all_points_x": [
712,
730
],
"all_points_y": [
414,
435
]
},
"region_attributes": {}
}
}
},
结合代码可以看出,get_balloon_dicts函数将每个图片做成一个record字典,record字典包括file_name、image_id、height、width和annotations,前面四个是图片的基本信息,annotations是由obj组成的列表objs,每个obj是一个字典,即annotations是以字典为元素的列表。每个obj就对应着一张图片上的其中一个框,包括bbox、bbox_mode、category_id,分别表示bbox的坐标、bbox的标注格式、框中物体的类别。
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
则设置了类别的label,这里只有一种,是balloon。
训练
from detectron2.engine import DefaultTrainer
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"))
cfg.DATASETS.TRAIN = ("balloon_train",)
cfg.DATASETS.TEST = ()
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml") # Let training initialize from model zoo
cfg.SOLVER.IMS_PER_BATCH = 2 # This is the real "batch size" commonly known to deep learning people
cfg.SOLVER.BASE_LR = 0.000025 # pick a good LR
cfg.SOLVER.MAX_ITER = 270000 # 300 iterations seems good enough for this toy dataset; you will need to train longer for a practical dataset
cfg.SOLVER.STEPS = [] # do not decay learning rate
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 512 # The "RoIHead batch size". 128 is faster, and good enough for this toy dataset (default: 512)
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # only has one class (ballon). (see https://detectron2.readthedocs.io/tutorials/datasets.html#update-the-config-for-new-datasets)
# NOTE: this config means the number of classes, but a few popular unofficial tutorials incorrect uses num_classes+1 here.
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()
这里设置了一些配置项,开始训练。训练结果过默认存放在output文件夹,权重存放在model_final.pth。
验证
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth") # path to the model we just trained
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 # set a custom testing threshold
predictor = DefaultPredictor(cfg)
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.data import build_detection_test_loader
evaluator = COCOEvaluator("balloon_val", output_dir="./output")
val_loader = build_detection_test_loader(cfg, "balloon_val")
print(inference_on_dataset(predictor.model, val_loader, evaluator))
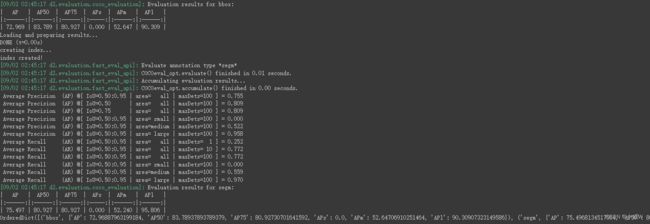
首先读取了训练的结果"model_final.pth",设置了阈值为0.7,阈值越高越严格。
最后打印出了验证的结果,正确的输出应该与下图相类似。
参考资料
https://github.com/facebookresearch/detectron2
https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5#scrollTo=gKkz6CkaL6Y2