3.1 AlexNet网络结构详解与花分类数据集下载
AlexNet详解

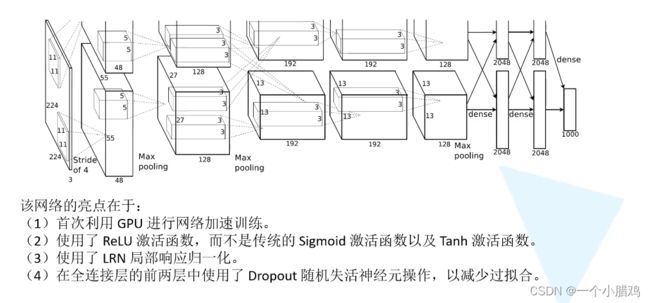
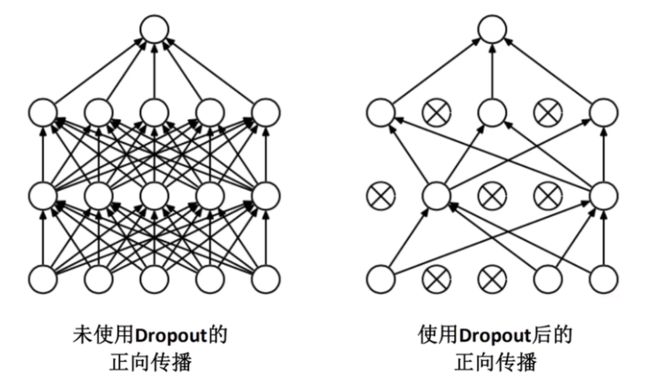
使用Dropout的方式在网络正向传播过程中随机失活一部分神经元,以减少过拟合
经卷积后的矩阵尺寸大小计算公式为:
N = ( W - F + 2P ) / S + 1
①输入图片大小为 W×W
②Filter大小 F×F
③步长S
④ padding的像素数P
Conv1
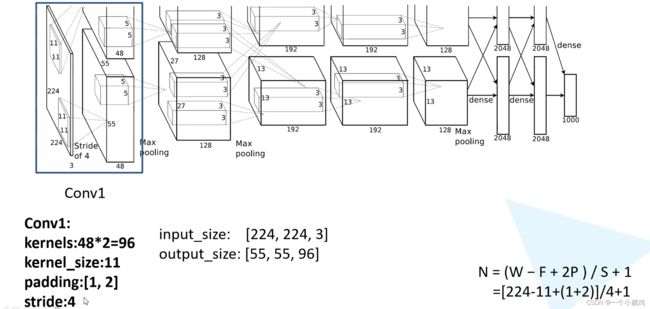
注意:原作者实验时用了两块GPU并行计算,上下两组图的结构是一样的。
输入:input_size = [224, 224, 3]
卷积层:
kernels = 48 * 2 = 96 组卷积核
kernel_size = 11
padding = [1, 2] (左上围加半圈0,右下围加2倍的半圈0)
stride = 4
输出:output_size = [55, 55, 96]
经 Conv1 卷积后的输出层尺寸为:
Output = ( W − F + 2 P )/ S + 1 = [ 224 − 11 + ( 1 + 2 ) ] / 4 + 1 = 55
Maxpool1

输入:input_size = [55, 55, 96]
池化层:(只改变尺寸,不改变深度channel)
kernel_size = 3
padding = 0
stride = 2
输出:output_size = [27, 27, 96]
经 Maxpool1 后的输出层尺寸为:
O u t p u t = ( W − F + 2 P ) / S + 1 = ( 55 − 3 ) / 2 + 1 = 27
Conv2

输入:input_size = [27, 27, 96]
卷积层:
kernels = 128 * 2 = 256 组卷积核
kernel_size = 5
padding = [2, 2]
stride = 1
输出:output_size = [27, 27, 256]
经 Conv2 卷积后的输出层尺寸为:
O u t p u t = ( W − F + 2 P ) / S + 1 = [ 27 − 5 + ( 2 + 2 ) ] 1 + 1 = 27
Maxpool2

输入:input_size = [27, 27, 256]
池化层:(只改变尺寸,不改变深度channel)
kernel_size = 3
padding = 0
stride = 2
输出:output_size = [13, 13, 256]
经 Maxpool2 后的输出层尺寸为:
O u t p u t = ( W − F + 2 P ) / S + 1 = ( 27 − 3 ) / 2 + 1 = 13
Conv3

输入:input_size = [13, 13, 256]
卷积层:
kernels = 192* 2 = 384 组卷积核
kernel_size = 3
padding = [1, 1]
stride = 1
输出:output_size = [13, 13, 384]
经 Conv3 卷积后的输出层尺寸为:
O u t p u t = ( W − F + 2 P ) / S + 1 = [ 13 − 3 + ( 1 + 1 ) ] / 1 + 1 = 13
Conv4
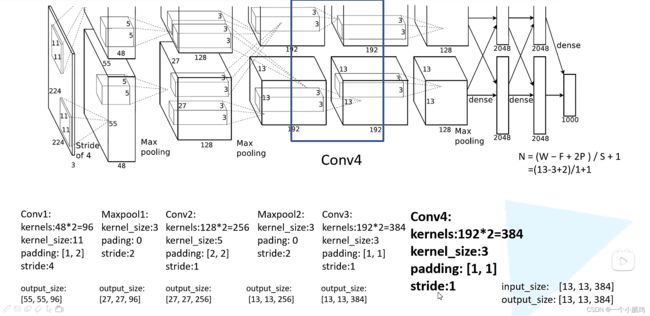
输入:input_size = [13, 13, 384]
卷积层:
kernels = 192* 2 = 384 组卷积核
kernel_size = 3
padding = [1, 1]
stride = 1
输出:output_size = [13, 13, 384]
经 Conv4 卷积后的输出层尺寸为:
O u t p u t = ( W − F + 2 P ) / S + 1 = [ 13 − 3 + ( 1 + 1 ) ] /1 + 1 = 13
Conv5

输入:input_size = [13, 13, 384]
卷积层:
kernels = 128* 2 = 256 组卷积核
kernel_size = 3
padding = [1, 1]
stride = 1
输出:output_size = [13, 13, 256]
经 Conv5 卷积后的输出层尺寸为:
O u t p u t = ( W − F + 2 P ) / S + 1 = [ 13 − 3 + ( 1 + 1 ) ] / 1 + 1 = 13
Maxpool3

输入:input_size = [13, 13, 256]
池化层:(只改变尺寸,不改变深度channel)
kernel_size = 3
padding = 0
stride = 2
输出:output_size = [6, 6, 256]
经 Maxpool3 后的输出层尺寸为:
O u t p u t = ( W − F + 2 P ) / S + 1 = ( 13 − 3 ) / 2 + 1 = 6
FC1、FC2、FC3
Maxpool3 → (66256) → FC1 → 2048 → FC2 → 2048 → FC3 → 1000
最终的1000可以根据数据集的类别数进行修改。
总结

分析可以发现,除 Conv1 外,AlexNet 的其余卷积层都是在改变特征矩阵的深度,而池化层则只改变(减小)其尺寸
花分类 数据集下载
花分类数据集下载链接
视频作者git
1 点击data_set
2 划分测试集和训练集
由于此数据集不像 CIFAR10 那样下载时就划分好了训练集和测试集,因此需要自己划分。
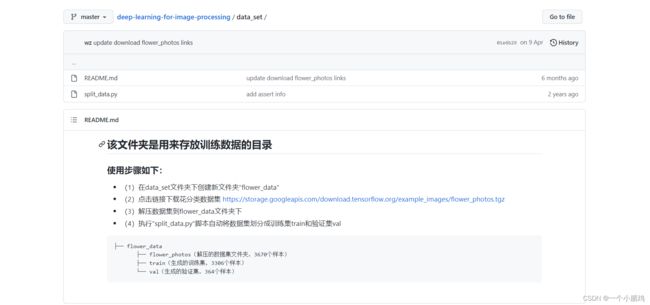
如下


split_data.py脚本会按照 9:1的比例划分 训练集和验证集
操作方式:
shift + 右键 打开 PowerShell ,执行 “split_data.py” 分类脚本自动将数据集划分成 训练集train 和 验证集val。

生成了训练集文件夹和验证集文件夹

完整的目录结构如下:
|-- flower_data
|-- flower_photos
|-- daisy
|-- dandelion
|-- roses
|-- sunflowers
|-- tulips
|-- LICENSE.txt
|-- train
|-- daisy
|-- dandelion
|-- roses
|-- sunflowers
|-- tulips
|-- val
|-- daisy
|-- dandelion
|-- roses
|-- sunflowers
|-- tulips
|-- flower_photos.tgz
|-- flower_link.txt
|-- README.md
|-- split_data.py
split_data.py的代码如下,在用到自己的数据集时,可以简单修改代码中的文件夹名称进行数据集的划分。
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
cwd = os.getcwd()
data_root = os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_root, "flower_photos")
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存训练集的文件夹
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()
os.makedirs(name, mode=0o777, exist_ok=False)
作用
用来创建多层目录(单层请用os.mkdir)
参数说明
name:你想创建的目录名
mode:要为目录设置的权限数字模式,默认的模式为 0o777 (八进制)。
exist_ok:是否在目录存在时触发异常。如果exist_ok为False(默认值),则在目标目录已存在的情况下触发FileExistsError异常;如果exist_ok为True,则在目标目录已存在的情况下不会触发FileExistsError异常。