使用Hugging Face Tensorflow做文本分类
我使用的版本是:
Python version: 3.7.9
pip install tensorFlow==2.5.0 -i https://mirrors.aliyun.com/pypi/simple
pip install transformers==4.6.1 -i https://mirrors.aliyun.com/pypi/simple
预训练模型(从Hugging Face下载):
distilbert-base-uncased
注:uncased不区分大小写,cased区分大小写
- 下载预训练模型


- 开始实战
import numpy as np
import tensorflow as tf
import pandas as pd
from tqdm import tqdm
from transformers import DistilBertTokenizer, TFDistilBertModel
## 读取数据
df_path = "./data/train_data/new_train_data.csv"
df = pd.read_csv(df_path, sep=",", low_memory=False)
df.fillna("unk", inplace=True)
## 加载分词器和模型
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
distil_bert_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
## 分词器
def tokenize(sentence_list, tokenizer):
input_ids = list()
attention_mask = list()
for sentence in tqdm(sentence_list):
inputs = tokenizer(sentence, padding="max_length", max_length=50, truncation=True)
input_ids.append(inputs["input_ids"])
attention_mask.append(inputs["attention_mask"])
return np.asarray(input_ids, dtype="int32"), np.asarray(attention_mask, dtype="int32")
## textcnn模型训练
def textcnn_train(input_ids, attention_mask, y_train, size_list, unit_list, batch_size, epochs, learning_rate):
input_token = tf.keras.layers.Input(shape=(50,), name="input_token", dtype="int32")
masked_token = tf.keras.layers.Input(shape=(50,), name="masked_token", dtype="int32")
distil_bert_outputs = distil_bert_model(input_ids=input_token, attention_mask=masked_token, output_hidden_states=False)
## (bz, 50, 768)
embedding = distil_bert_outputs[0]
## 并行卷积
pool_out = list()
for size_length in size_list:
conv1 = tf.keras.layers.Conv1D(filters=128, kernel_size=size_length, strides=1, padding='valid', activation='relu')(embedding)
pool1 = tf.keras.layers.GlobalMaxPool1D()(conv1)
pool_out.append(pool1)
## 池化拼接
h_pool = tf.concat(pool_out, axis=1)
## 平铺维度
dense = tf.keras.layers.Flatten()(h_pool)
## 全连接层
for unit in unit_list:
dense = tf.keras.layers.Dense(unit, activation='relu')(dense)
dense = tf.keras.layers.Dropout(rate=0.3)(dense)
## 输出层
output = tf.keras.layers.Dense(units=1, activation='sigmoid')(dense)
model = tf.keras.Model(inputs=[input_token, masked_token], outputs=output)
model.summary()
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.BinaryAccuracy(threshold=0.5)])
model.fit([input_ids, attention_mask],
y_train,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
return print('训练完成')
x_train = df["text"].values
input_ids, attention_mask = tokenize(x_train, tokenizer)
y_train = df["label"].values
size_list = [1, 2, 3]
unit_list = [512, 256, 128]
batch_size = 64
epochs = 2
learning_rate = 3e-5
textcnn_train(input_ids, attention_mask, y_train, size_list, unit_list, batch_size, epochs, learning_rate)
- 模型网络

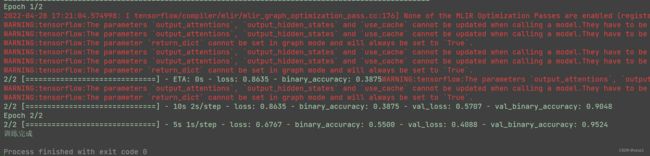
- 训练结果