无监督语义相似度哪家强?我们做了个比较全面的评测

©PaperWeekly 原创 · 作者|苏剑林
单位|追一科技
研究方向|NLP、神经网络
一月份的时候,笔者写了《你可能不需要 BERT-flow:一个线性变换媲美 BERT-flow》[1],指出无监督语义相似度的 SOTA 模型 BERT-flow 其实可以通过一个简单的线性变换(白化操作,BERT-whitening)达到。
随后,我们进一步完善了实验结果,写成了论文《Whitening Sentence Representations for Better Semantics and Faster Retrieval》。本文将对这篇论文的内容做一个基本的梳理,并在 5 个中文语义相似度任务上进行了补充评测,包含了 600 多个实验结果。

论文标题:
Whitening Sentence Representations for Better Semantics and Faster Retrieval
论文链接:
https://arxiv.org/abs/2103.15316
代码链接:
https://github.com/bojone/BERT-whitening

方法概要
BERT-whitening 的思路很简单,就是在得到每个句子的句向量 后,对这些矩阵进行一个白化(也就是 PCA),使得每个维度的均值为 0、协方差矩阵为单位阵,然后保留 k 个主成分,流程如下图:

当然,理论上来说,我们也可以将 BERT-whitening 看成是 BERT-flow [2] 的最简单实现,而之前的文章中已经指出,就是这样简单的实现足以媲美一般的 BERT-flow 模型,有时候甚至更好。同时,BERT-whitening 在变换的同时还对特征重要性进行了排序,因此我们可以对句向量进行降维来提高检索速度。实验结果显示,在多数任务中,降维不但不会带来效果上的下降,反而会带来效果上的提升。

英文任务
首先介绍 BERT-whitening 在英文任务上的测试结果,主要包含三个图表,基本上实现了与 BERT-flow 进行了严格对照。
2.1 纯无监督
首先,第一个表格介绍的是在完全无监督的情况下,直接使用预训练的 BERT 抽取句向量的结果。在 BERT-flow 的论文中,我们已经确实,如果不加任何后处理手段,那么基于 BERT 抽取句向量的最好 Pooling 方法是 BERT 的第一层与最后一层的所有 token 向量的平均,即 fisrt-larst-avg(BERT-flow 论文误认为是最后两层的平均,记为了 last2avg,实际上是第一层与最后一层)。所以后面的结果,都是以 fisrt-larst-avg 为基准来加 flow 或者 whitening。

▲ 英文任务上纯无监督语义匹配的评测结果
2.2 NLI监督
然后,第二个表格介绍的是基于 NLI 数据集微调后的 Sentence-BERT [3] 模型(SBERT)抽取句向量的结果,在此情况下同样是 fisrt-larst-avg 最好,所以 flow 和 whitening 的基准都是 fisrt-larst-avg 出来的句向量。NLI 数据集是自然语言推理数据集,跟语义相似度类似但不等价,它可以作为语义相似度任务的有监督预训练,但由于没有直接用到语义相似度数据,因此相对于语义相似度任务来说依然属于无监督的。

▲ 英文任务上基于BERT-NLI的语义匹配的评测结果
2.3 维度-效果
在这两个表格中,加粗的是最优结果;绿色箭头 意味着BERT-whitening的结果优于同样情况下的 BERT-flow 模型,而红色箭头 则相反,也就是说,绿色箭头越多意味着 BERT-whitening 的效果也好;whitening 后面接的数字 256、384 指的是降维后保留的维度。所以,从这两个表格可以看出,BERT-whitening 总体而言优于 BERT-flow,实现了大多数任务的 SOTA,并且多数情况下,降维还能进一步提升效果。
为了进一步确认降维所带来的效果,我们绘制了如下的保留维度与效果关系图:
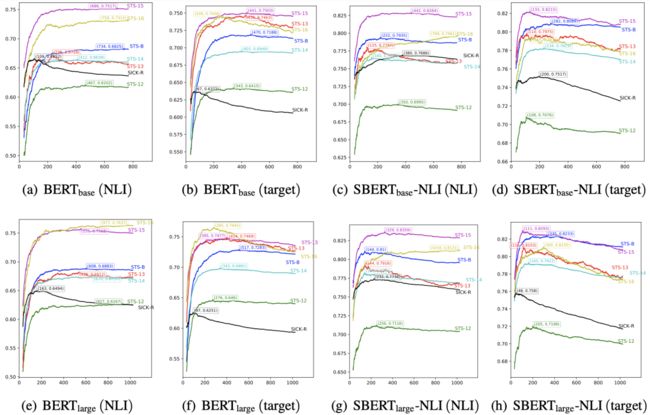
▲ 英文各个任务上的“维度-效果”图,图中还标记了最有效果对应的维度,可以看到对于每个任务而言,降维都有可能带来一定的提升。
上图演示了各个模型在各个任务上经过 whitening 之后,保留的维度与评测指标的变化曲线。可以看到,对于每个任务来说,最优效果都不是在全部维度取到,这意味着降维都可以带来一定的效果提升,并且可以看到,不少任务甚至可以降维到原来的 1/8 甚至更多而保持效果不减甚至增加,这充分显示了 BERT-whitening 的工程价值,因为降维意味着我们能大大加快检索速度。

中文任务
秉承着“没有在中文测试过的模型是没有灵魂的”的理念,笔者整理了一些中文语义相似度数据集,结合不同的中文预训练模型、Pooling 方式以及 whitening 与否进行了评测,结果汇总于此,供大家对比。
3.1 评测情况
本次评测涉及到 11 个模型、5 个数据集、4 种 Pooling 方式,每种组合比较“不 whitening”、“whitening”、“whitening且降维”3 种后处理方式的效果,所以共有将近:

个实验结果,算是比较全面了。说“将近”是因为某些 Pooling 方式在某些模型不可用,所以离 660 还差一点。由于 BERT-flow 计算成本明显大于 BERT-whitening,因此我们没有复现对比 BERT-flow 的效果,但是从英文任务上可以看出,BERT-whitening 和 BERT-flow 的效果通常是接近的,并且 BERT-whitening 通常还优于 BERT-flow,因为 whitening 的效果应该是有代表性的了。
评测指标跟前述英文任务一样,都是用 spearman 相关系数,这是一个类似 AUC 的排序指标,只依赖于预测分数的顺序,并且不依赖于阈值,所以用来评测效果是比较适合的。
之所以没有用大家更熟悉的准确率(accuracy)指标,一是因为准确率依赖于具体的阈值,二是因为 STS-B 数据集的标签是 1~5 的数字,并不是 0/1 标签,要算准确率也无从算起,因此统一用 spearman 相关系数了。如果读者非要从准确率角度理解,那么大概可以认为“accuracy ≈ 0.5 + spearman / 2”吧。
其中 11 个模型如下:
BERT(Google 开源的中文 BERT base 版):
https://github.com/google-research/bert
RoBERTa(哈工大开源的 roberta_wwm_ext 的 base 版):
https://github.com/ymcui/Chinese-BERT-wwm
NEZHA(华为开源的相对位置编码的 BERT base 版 (wwm)):
https://github.com/huawei-noah/Pretrained-Language-Model
WoBERT(以词为单位的 BERT,这里用的是 Plus 版):
https://github.com/ZhuiyiTechnology/WoBERT
RoFormer(加入了新型位置编码的 BERT):
https://github.com/ZhuiyiTechnology/roformer
BERTlarge(腾讯 UER 开源的 BERT large 版本):
https://github.com/dbiir/UER-py
RoBERTalarge(哈工大开源的 roberta_wwm_ext 的 large 版):
https://github.com/ymcui/Chinese-BERT-wwm
NEZHA-large(华为开源的相对位置编码的 BERT large 版 (wwm)):
https://github.com/huawei-noah/Pretrained-Language-Model
SimBERT(经过相似句训练的 BERT base 版):
https://github.com/ZhuiyiTechnology/simbert
SimBERTsmall(经过相似句训练的 BERT small 版):
https://github.com/ZhuiyiTechnology/simbert
SimBERTtiny(经过相似句训练的 BERT tiny 版):
https://github.com/ZhuiyiTechnology/simbert
5 个任务如下:
ATEC:ATEC 语义相似度学习赛数据集,金融领域客服场景,原比赛链接已经失效,当前数据来自:
https://github.com/IceFlameWorm/NLP_Datasets/tree/master/ATEC
BQ:哈工大 BQ Corpus 数据集,银行金融领域的问题匹配,详情可看:
http://icrc.hitsz.edu.cn/info/1037/1162.htm
LCQMC:哈工大 LCQMC 数据集,覆盖多个领域的问题匹配,详情可看:
http://icrc.hitsz.edu.cn/Article/show/171.html
PAWSX:谷歌发布的数据集,数据集里包含了多语种的释义对和非释义对,即识别一对句子是否具有相同的释义(含义),特点是具有高度重叠词汇,对无监督方法来说算是比较难的任务,这里只保留了中文部分:
https://arxiv.org/abs/1908.11828
STS-B:计算两句话之间的相关性,原数据集为英文版,通过翻译加部分人工修正的方法生成中文版,来源:
https://github.com/pluto-junzeng/CNSD
4 种 Pooling 方式如下:
P1:把 encoder 的最后一层的 [CLS] 向量拿出来;
P2:把 Pooler(BERT 用来做 NSP 任务)对应的向量拿出来,跟 P1 的区别是多了个线性变换;
P3:把 encoder 的最后一层的所有向量取平均;
P4:把 encoder 的第一层与最后一层的所有向量取平均。
3.2 结果汇总
所有的实验结果汇总在如下三个表格中。其中表格中的每个元素是 a / b / c 的形式,代表该任务在该模型下“不加 whitening”的得分为 a、“加 whitening”的得分为 b、“加 whitening 并适当降维”的得分为 c;如果 ,那么 b 显示为绿色,否则显示为红色;如果 ,那么 c 显示为绿色,否则显示为红色;所谓“适当降维”,对于 base 版本的模型是降到 256 维,对于 large 版本的模型是降到 384 维,对于 tiny 和 small 版则降到 128 维。
第一个表格是 11 个模型中的 6 个 base 版模型的对比,其中 WoBERT 和 RoFormer 没有 NSP 任务,所以没有 P2 的权重,测不了 P2:

第二个表格则是 3 个 large 版模型的对比:

第三个表格则是不同大小的 SimBERT 模型之间的对比:

3.3 实验结论
跟英文任务的表格类似,绿色意味着 whitening 操作提升了句向量质量,红色则意味着 whitening 降低了句向量质量,绿色越多则意味着 whitening 方法越有效。从上述几个表格中,我们可以得出一些结论:
1. 中文任务的测试结果比英文任务复杂得多,更加不规律,比如在英文任务中,P4 这种 Pooling 方式基本上都比其他方式好,而 large 模型基本上比 base 好,但这些情况在中文任务重都不明显;
2. 除了 SimBERT 外,整体而言还是绿色比红色多,所以 whitening 对句向量的改善基本上还是有正面作用的,特别地,在 a / b / c 中,c 的绿色明显比 b 的绿色要多,这说明降维还能进一步提升效果,也就是说 whitening 是真正的提速又提效的算法;
3. 在 BQ 任务中,whitening 方法几乎都带来了下降,这跟英文任务中的 SICK-R 任务类似,这说明“天下没有免费的午餐”,总有一些任务会使得“各向同性”假设失效,这时候不管是 BERT-whitening 还是 BERT-flow 都不能带来提升;
4. SimBERT 是所有除 PAWSX 外的任务的 SOTA,当然 SimBERT 算是经过语义相似度任务有监督训练过的了(但理论上训练数据与测试任务没有交集),所以跟其他模型比肯定不是特别公平的,但不管怎样,SimBERT 已经开源,大家都可以用,所以可以作为一个 baseline 对待;
5. SimBERT 加 whitening,要不会带来性能下降,要不就是有提升也不明显,这说明如果通过有监督方法训练出来的句向量,就没有必要进一步做 whitening 了,基本上不会带来提升;
6. PAWSX 确实很难,语义相似度任务还任重道远。

本文小结
本文介绍了我们在中英文任务上对无监督语义相似度方法的比较全面评测。在英文任务方面,主要复述了我们的 BERT-whitening 方法的论文中的结果,里边包含了跟 BERT-flow一一对齐的比较;在中文方面,我们收集了 5 个任务,在 11 个预训练模型、4 种 Pooling 方式、3 种后处理方式共 600 多种组合进行了评测,以提供一个可以方便大家对比的结果。
一句话总结评测结果,那就是:BERT-whitening 方法确实达到了当前无监督语义的 SOTA,而 SimBERT 则是中文语义相似度的一个比较高的开源 baseline。
参考文献
[1] https://kexue.fm/archives/8069
[2] https://arxiv.org/abs/2011.05864
[3] https://arxiv.org/abs/1908.10084
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
