Few-shot Object Detection via Feature Reweighting 论文笔记
前言
小样本目标检测解决的问题是,在训练一个检测器时,每个目标类别只有一小部分被标记的样本作为训练数据。本文提出了一个以元学习为基础的框架,如下图所示。这个框架的设计思想是充分探索从一些基础目标中学到的知识,从而通过少量样本从新颖类别中检测目标。作者发现在一些具有丰富样本的基础类别上训练以CNN为基础的检测模型时,可以在这个模型的顶层学到特定于某些目标属性的中间特征,这些特征可以隐式组成不同目标的高级表示。因此,本文提出的框架的作用就是学习如何调整这些中间特征并相应地检测新颖的目标。
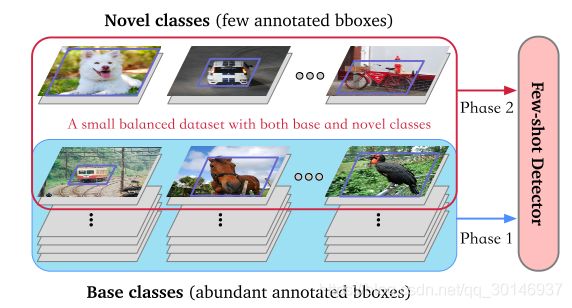
该框架包括一个提供基础特征的检测模型,和一个轻量级的元模型,这个元模型的作用是通过参考一些样本来学习使基础特征能够适应其它新颖的目标。为了适应速度更快,只要求这个元模型学习预测基本特征的权重系数,并调整其对最终检测的贡献。元模型的输入是 N N N个类别的样本,然后预测 N N N个特征的权重,每个特征权重都通过端到端的训练来负责检测相应的类别。通过不同的特征权重,置信度和边界框坐标都能够得到充分的调整。最后置信度还要用一个softmax层来校正结果。如上图所示,整个小样本检测模型的训练分为两个阶段:
- 首先,在具有充足样本的基础类别上训练一个基础检测模型和一个元模型,学习基础类别的特征表示,这些特征就是中间特征;
- 然后,在少量样本的情况下,通过重新预测中间特征的权重来训练元模型,使其对新的目标类别具有更大的判断力和敏感度,从而使检测模型能够快速适应检测新的目标类别。
本文提出的小样本检测器不仅比baseline模型表现得更好,并且通用性也很强,通过重新预测特征的权重可以使该模型从一个数据集到另一个不同的数据集上。
Few-shot Detector
1. 数据集的选择
在训练时采用两种数据集,base类的数据集和novel类的数据集。base类中有充足的被标记的数据,保留了所有的边界框标签;novel类中只有少量被标记的样本。
2. 模型设计
本文的小样本检测模型基于YOLOv2框架,作者认为,一些类别之间会共享一些特征,比如要检测一只猫,那么用于检测狗的特征可能会比用于检测飞机的特征更有用,因为猫和狗之间可能会共享一些特征。这也就是本文的小目标检测的思路,就是说,通过增强在base类上学到的特征表示的可重用性,来更好的检测novel类的目标。因此,当检测某个novel类时,给base 类提取的特征都分配一个权重,这样模型就会把更多的注意力放在与该novel类相关的特征上。
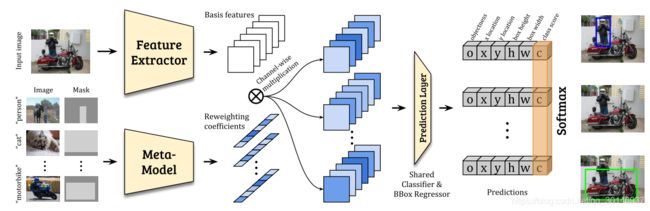
如上图所示,本文设计了一个元模型来生成这些权重系数。将元模型定义为 M M M,base类中的图像和图像中目标的边界框标签分别被记为 I i I_i Ii和 M i M_i Mi,其中 i i i是类别, i = 1 , 2 , . . . , N i=1,2,...,N i=1,2,...,N, N N N是类别的数量,用这些数据作为一个参考。元模型 M M M从每个类别中拿一个被标记的样本 ( I i , M i ) (I_i,M_i) (Ii,Mi)作为输入,然后预测 N N N组权重系数 w i w_i wi,每个 w i w_i wi负责对特征进行调整来预测相应的novel类 i i i, w i w_i wi被计算为: w i = M ( I i , M i ) w_i=M(I_i,M_i) wi=M(Ii,Mi)。使用YOLOv2的backbone(DarkNet-19)作为特征提取器 D D D,提取出的基础特征记为 F F F,输入图像记为 I i I_i Ii,则有: F = D ( I ) F=D(I) F=D(I), F F F中特征图的数量与 w i w_i wi中权重的数量相同。那么对于每个novel类 i i i,它的特定于类别的特征 F i F_i Fi通过下式获得:
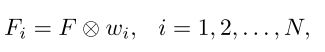
其中 ⨂ \bigotimes ⨂表示channel-wise的乘法。
在得到 F i F_i Fi之后,在 F i F_i Fi上应用一个预测层,对每个预定义的anchor,回归它的objectness分数 o o o(是/不是目标),边界框偏移值 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)和分类分数 c c c:
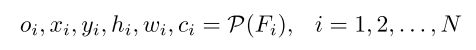
其中 c i c_i ci是对应的目标属于类别 i i i的概率。
3. 元模型的输入
元模型的输入应该是object of interest,比如在一个图像中,有位于前景的车啊猫啊狗啊之类的,这些目标就是object of interest,也就是真正应该输入到元模型中的目标,但是也有不太重要的背景信息。为了让元模型知道真正应该关注的目标类别,除了RGB三通道外,又额外引入一个mask通道 M i M_i Mi,它有两个值,在object of interest的位置上它是1,其它位置上它都是0,如下图所示,比如在“person”那张图上,只有“person”所在的位置的mask才是1,也就是浅灰色区域,其它位置的mask都是0,也就是深灰色区域。

如果有多个目标出现在图像上,只选择其中一个,比如上图“person”中有人和马,但只选择了人作为目标类别。这个mask通道让元模型知道它应该使用图像中的哪部分,而哪部分应该被视为是背景。
训练细节
1. 损失函数
为了训练元模型,需要谨慎选择损失函数,尤其是在样本数量很少的情况下预测novel类。考虑到现在是按类别进行预测的,也就是说我给你一个属于novel类的目标,你要根据base类预测出该目标属于的novel类是什么,因此看起来使用二值交叉熵损失函数似乎很自然,如果目标属于目标类别,则回归1,否则回归0。但是,作者发现该损失函数会让模型输出冗余的检测结果(比如将火车检测为火车、公共汽车和汽车),这是因为对于特定区域,在 N N N个类别中只有一个是positive,而二值损失致力于产生平衡的positive/negative预测结果。也就是说,对于某个目标,它只属于 N N N个类别中的某一个类,比如火车它就是火车,但二值损失只能判断某个目标是否属于目标类,只有1/0的输出,如果某个目标对于多个类别的二值损失都是1,并不能知道究竟哪个类别与该目标的相似度更高,只有一个笼统的结果。
为了解决这个问题,为每个分类分数附加了一个softmax层以进行校正,从而抑制其它不正确的类别。因此,真正的类别分数为:
![]()
为了更好的训练和预测,在这些校正过的类别分数上应用二值交叉熵损失函数:
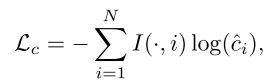
其中 I ( ⋅ , i ) I(·,i) I(⋅,i)是一个指示函数,说明当前的anchor box是否属于类别 i i i。在引入softmax之后,对于某个anchor来说,它的分类分数的总和等于1,这其中可能性更高的类别的分数占大部分,从而抑制了可能性很低的类别的预测结果。
对于边界框回归和objectness回归,采用的是和YOLOv2中相似的损失函数,但是为了平衡正负样本,不计算某些负样本的objectness分数的损失。
2. 训练过程
整个训练过程分为两个阶段:
- base training:给定大量base类的带标记的数据,首先在这些数据上进行训练,以学习base类的特征表示,注意这个阶段中元模型和检测器是联合训练的,这是为了使它们以期望的方式进行协调:在检测novel类时,元模型需要预测相应的base类的特征的权重。在每次迭代过程中,元模型将 N N N个图像作为输入, N N N是base类的数量,然后产生 N N N组权重系数,每个用来检测一个novel类的目标。
- few-shot fine-tuning:在这一阶段中,在base类和novel类上来训练模型。因为只有 k k k个标记可以用于novel类,为了使类别之间达到平衡,base类中也只包括 k k k个标记的边界框。训练过程和第一阶段的一样,只是第二阶段需要更少的迭代就能使模型收敛。
在两个训练阶段中,权重系数是取决于元模型的输入的,而元模型的输入在每次迭代中都是从可用的数据中随机采样的。在few-shot fine-tuning之后,能够获得一个不再依赖任何元模型的模型,也就是说,元模型将 k k k个带标记的样本作为输入,每个样本都会预测一个权重,将这些权重的平均值作为目标类别的权重,在设置好权重后,元模型就可以被分离掉了。因此在inference时,原始检测器增加的开销是可以忽略的。
结论
本文提出的元模型是最重要的部分,它为base类的特征预测不同的权重,这些权重在调整这些base特征后来检测只有少量样本的novel类,也就是调整不同的base特征对检测novel类所做的贡献。根据我的理解,novel类好像大多都与base类有一定的相似度??