【论文笔记】ICML2016 & Cornell | (IPS-MF) Recommendations as treatments: Debiasing learning and evaluation

目录
- 1. 研究目标
- 2. 背景
- 3. 逆倾向评分(IPS, Inverse-Propensity-Scoring)
-
- 3.1 IPS评价指标
- 3.2 Task1:评分预测准确性的评价
- 3.3 Task2:推荐质量的评价
- 3.4 基于倾向评分的性能评估
-
- 3.4.1 IPS Estimator
- 3.4.2 SNIPS Estimator
- 3.5 实验验证
- 4. IPS+推荐系统
- 5. 倾向性评分的估计
-
- 5.1 朴素贝叶斯
- 5.2 逻辑回归
- 6. 实验
-
- 采样偏差对评测指标的影响
- 采样偏差对模型训练的影响
- 倾向性评分估计准确度的影响
- 真实数据集上的表现
本文是Cornell University在ICML 2016的一篇工作
论文地址:[1602.05352] Recommendations as Treatments: Debiasing Learning and Evaluation (arxiv.org)
本文是较为经典的一篇提出利用逆倾向分数(Inverse Propensity Score, IPS)处理选择偏差的文章。倾向分数可以看作是每个数据被观察到的概率。
从因果推断的角度看待推荐问题,认为在推荐系统中给用户曝光某个商品类似于在医学中给病人施加某种治疗方式。这两个任务的共同点是,只知道少数病人(用户)对少数治疗方式(物品)的反应,而大多数的病人-治疗(用户-物品)对的结果是观察不到的。
本文提出的方法可以在数据有偏的情况下实现无偏的性能估计,并提供了一个矩阵分解方法。
因果推断
因果推断的核心思想在于反事实推理counterfactual reasoning,即在我们观测到X和Y的情况下,推理如果当时没有做X,Y'是什么。
因果推断的目的是要判断因果性,即计算因果效应(有无X的情况下Y值的变化量)。在进行反事实推理后,可得出因果效应e = |Y - Y'|,进而判断因果性。
实际上,对于一个对象,我们永远只能观察到Y和Y'的其中一个,因果推断所做的就是从已有数据中估计因果效应,所以我认为因果推断的本质是,对因果效应的估计。
1. 研究目标
去除选择偏差(selection-bias)对模型性能评测(evaluation)和模型训练(training)带来的不利影响。
2. 背景
推荐系统中的选择偏差(selection bias)可能有两个来源:
- 当用户可以自由选择要评分的商品时,不会给所有的商品打分。用户倾向于对自己感兴趣的物品打分,造成了数据非随机缺失(Missing Not At Random, MNAR)问题。
- 推荐系统在给出推荐列表时,也会倾向于给用户推荐符合用户兴趣的产品。
观察到的评分并不是所有评分的代表性样本,于是产生了选择偏差。
3. 逆倾向评分(IPS, Inverse-Propensity-Scoring)
IPS的是设计一个loss函数来提高模型的精度,纠正偏差,在整个训练的过程改变的只是loss函数,训练的模型可以是MF、Network等。
3.1 IPS评价指标

- Y Y Y表示真实的评分矩阵, P P P表示用户对电影评分的概率, O O O反映有多少用户参与评分
- Y ^ 1 \hat{Y}_1 Y^1和 Y ^ 2 \hat{Y}_2 Y^2表示评分的预测, Y ^ 3 \hat{Y}_3 Y^3表示是否发生了交互
3.2 Task1:评分预测准确性的评价
假设理想情况下,能获得所有无偏差的预测值 Y ^ \hat{Y} Y^,即历史交互数据为MCAR(Missing Completely At Random,完全随机缺失),评价指标是:
R ( Y ^ ) = 1 U ⋅ I ∑ u = 1 U ∑ i = 1 I δ u , i ( Y , Y ^ ) R(\hat{Y})=\frac{1}{U \cdot I} \sum_{u=1}^{U} \sum_{i=1}^{I} \delta_{u, i}(Y, \hat{Y}) R(Y^)=U⋅I1u=1∑Ui=1∑Iδu,i(Y,Y^)
在selection bias的场景下,评价指标定义为:
R ^ naive ( Y ^ ) = 1 ∣ { ( u , i ) : O u , i = 1 } ∣ ∑ ( u , i ) : O u , i = 1 δ u , i ( Y , Y ^ ) (1) \hat{R}_{\text {naive }}(\hat{Y})=\frac{1}{\left|\left\{(u, i): O_{u, i}=1\right\}\right|} \sum_{(u, i): O_{u, i}=1} \delta_{u, i}(Y, \hat{Y}) \tag{1} R^naive (Y^)=∣{(u,i):Ou,i=1}∣1(u,i):Ou,i=1∑δu,i(Y,Y^)(1)
其中, Y ^ \hat{Y} Y^表示预测的评分, Y Y Y表示真实评分, O u , i = 1 O_{u, i}=1 Ou,i=1表示 u u u对 i i i有评分, ∣ { ( u , i ) : O u , i = 1 } ∣ {\left|\left\{(u, i): O_{u, i}=1\right\}\right|} ∣{(u,i):Ou,i=1}∣表示所有被评分的item数量, δ u , i ( Y , Y ^ ) \delta_{u, i}(Y, \hat{Y}) δu,i(Y,Y^)可以是以下几种计算方法:
M A E : δ u , i ( Y , Y ^ ) = ∣ Y u , i − Y ^ u , i ∣ M S E : δ u , i ( Y , Y ^ ) = ( Y u , i − Y ^ u , i ) 2 A c c u r a c y : δ u , i ( Y , Y ^ ) = 1 { Y ^ u , i = Y u , i } MAE: \quad \delta_{u, i}(Y, \hat{Y})=\left|Y_{u, i}-\hat{Y}_{u, i}\right| \\ MSE: \quad \delta_{u, i}(Y, \hat{Y})=\left(Y_{u, i}-\hat{Y}_{u, i}\right)^{2} \\ Accuracy: \quad \delta_{u, i}(Y, \hat{Y})=\mathbf{1}\left\{\hat{Y}_{u, i}=Y_{u, i}\right\} MAE:δu,i(Y,Y^)=∣ ∣Yu,i−Y^u,i∣ ∣MSE:δu,i(Y,Y^)=(Yu,i−Y^u,i)2Accuracy:δu,i(Y,Y^)=1{Y^u,i=Yu,i}假设有20个用户对Figure 1给出了评分,评分的数量如下:
| Horror | Romance | Drama |
|---|---|---|
| 2 | 1 | 7 |
| 1 | 2 | 7 |
带入评价指标(MAE计算):
R ^ naive ( Y 1 ^ ) = ( 2 ∗ 7 + 2 ∗ 7 ) / 20 = 28 / 20 R ^ naive ( Y 2 ^ ) = ( 4 ∗ 1 + 4 ∗ 1 ) / 20 = 8 / 20 \hat{R}_{\text {naive }}(\hat{Y_1})=(2*7+2*7)/20 = 28/20 \\ \hat{R}_{\text {naive }}(\hat{Y_2})=(4*1+4*1)/20=8/20 R^naive (Y1^)=(2∗7+2∗7)/20=28/20R^naive (Y2^)=(4∗1+4∗1)/20=8/20从评价指标上看,由于 Y ^ 2 \hat{Y}_2 Y^2中预测错误的那些交互很少被观测到,因此, Y ^ 2 \hat{Y}_2 Y^2会优于 Y ^ 1 \hat{Y}_1 Y^1。
但实际上从人的主观角度看, Y ^ 1 \hat{Y}_1 Y^1明显是优于 Y ^ 2 \hat{Y}_2 Y^2的。
结论
实际上,历史记录往往是MNAR(Missing Not At Random,非随机缺失)的,那么整体评级预测损失就是有偏的
E O [ R ^ naive ( Y ^ ) ] ≠ R ( Y ^ ) (2) \mathbb{E}_{O}\left[\hat{R}_{\text {naive }}(\hat{Y})\right] \neq R(\hat{Y}) \tag{2} EO[R^naive (Y^)]=R(Y^)(2)
证明
E O [ R ^ naive ( Y ^ ) ] = 1 ∑ u = 1 N ∑ i = 1 M p ( o u , i = 1 ) ∑ u = 1 N ∑ i = 1 M p ( o u , i = 1 ) δ u , i ( Y , Y ^ ) ≠ 1 N ⋅ M ∑ u = 1 N ∑ i = 1 M δ u , i ( Y , Y ^ ) = R ( Y ^ ) \begin{aligned} \mathbb{E}_{O}\left[\hat{R}_{\text {naive }}(\hat{Y})\right] &=\frac{1}{\sum_{\mathrm{u}=1}^{\mathrm{N}} \sum_{\mathrm{i}=1}^{\mathrm{M}} \mathrm{p}\left(\mathrm{o}_{\mathrm{u}, \mathrm{i}}=1\right)} \sum_{\mathrm{u}=1}^{\mathrm{N}} \sum_{\mathrm{i}=1}^{\mathrm{M}} \mathrm{p}\left(\mathrm{o}_{\mathrm{u}, \mathrm{i}}=1\right) \delta_{\mathrm{u}, \mathrm{i}}(\mathrm{Y}, \hat{\mathrm{Y}}) \\ & \neq \frac{1}{\mathrm{~N} \cdot \mathrm{M}} \sum_{\mathrm{u}=1}^{\mathrm{N}} \sum_{\mathrm{i}=1}^{\mathrm{M}} \delta_{\mathrm{u}, \mathrm{i}}(\mathrm{Y}, \hat{\mathrm{Y}}) =R(\hat{Y}) \end{aligned} EO[R^naive (Y^)]=∑u=1N∑i=1Mp(ou,i=1)1u=1∑Ni=1∑Mp(ou,i=1)δu,i(Y,Y^)= N⋅M1u=1∑Ni=1∑Mδu,i(Y,Y^)=R(Y^)其中, p ( o u , i = 1 ) \mathrm{p}(\mathrm{o}_{\mathrm{u}, \mathrm{i}}=1) p(ou,i=1)表示 u u u浏览 i i i的概率。
R ( Y ^ ) R(\hat{Y}) R(Y^)本质是一种算数平均, E O [ R ^ naive ( Y ^ ) ] \mathbb{E}_{O}\left[\hat{R}_{\text {naive }}(\hat{Y})\right] EO[R^naive (Y^)]表示的是被评分的 i i i的期望评分损失,是一种加权平均。加权平均是有偏的,它的偏差就来自于给不同自变量分配的权值,在推荐任务中,这个权值指的就是物品被观测(浏览)到的概率。
要减轻MNAR反馈中偏差的影响,后文提到的IPS方法。
3.3 Task2:推荐质量的评价
如果不简单地使用准确率评价,而是想直接、准确地评价推荐的质量,
评价推荐结果的质量,也就是在回答一个反事实问题:如果用户与推荐列表中的物品发生交互,而不是实际上的交互历史,用户的体验会得到多大程度的提升?
文章提到了常用的DCG@k和PREC@k,看这些指标在selection bias的情况下表现怎样
DCG: δ u , i ( Y , Y ^ ) = ( I / log ( rank ( Y ^ u , i ) ) ) Y u , i PREC@ k : δ u , i ( Y , Y ^ ) = ( I / k ) Y u , i ⋅ 1 { rank ( Y ^ u , i ) ≤ k } \begin{aligned} \text { DCG: } \delta_{u, i}(Y, \hat{Y}) &=\left(I / \log \left(\operatorname{rank}\left(\hat{Y}_{u, i}\right)\right)\right) Y_{u, i} \\ \text { PREC@ } \mathrm{k}: \delta_{u, i}(Y, \hat{Y}) &=(I / k) Y_{u, i} \cdot 1\left\{\operatorname{rank}\left(\hat{Y}_{u, i}\right) \leq k\right\} \end{aligned} DCG: δu,i(Y,Y^) PREC@ k:δu,i(Y,Y^)=(I/log(rank(Y^u,i)))Yu,i=(I/k)Yu,i⋅1{rank(Y^u,i)≤k}由于选择偏差,与上节相似,最终的评价指标也是有偏的。
3.4 基于倾向评分的性能评估
Propensity-Scored Performance Estimators,基于倾向评分的性能评估
解决selection bias的关键在于理解观测数据的生成机制(Assignment Mechanism),包含系统生成(Experimental Setting)和用户选择(Observational Setting)两种因素。
3.4.1 IPS Estimator
使用逆倾向分数对观察数据加权,目的是消除权值(浏览概率)的影响,构建一个无偏估计器——IPS Estimator:
R ^ I P S ( Y ^ ∣ P ) = 1 U ⋅ I ∑ ( u , i ) : O u , i = 1 δ u , i ( Y , Y ^ ) P u , i (3) \hat{R}_{I P S}(\hat{Y} \mid P)=\frac{1}{U \cdot I} \sum_{(u, i): O_{u, i}=1} \frac{\delta_{u, i}(Y, \hat{Y})}{P_{u, i}} \tag{3} R^IPS(Y^∣P)=U⋅I1(u,i):Ou,i=1∑Pu,iδu,i(Y,Y^)(3) E O [ R ^ I P S ( Y ^ ∣ P ) ] = 1 U ⋅ I ∑ u ∑ i E O u , i [ δ u , i ( Y , Y ^ ) P u , i O u , i ] = 1 U ⋅ I ∑ u ∑ i δ u , i ( Y , Y ^ ) = R ( Y ^ ) . (4) \begin{aligned} \mathbb{E}_{O}\left[\hat{R}_{I P S}(\hat{Y} \mid P)\right] &=\frac{1}{U \cdot I} \sum_{u} \sum_{i} \mathbb{E}_{O_{u, i}}\left[\frac{\delta_{u, i}(Y, \hat{Y})}{P_{u, i}} O_{u, i}\right] \\ &=\frac{1}{U \cdot I} \sum_{u} \sum_{i} \delta_{u, i}(Y, \hat{Y})=R(\hat{Y}) . \end{aligned} \tag{4} EO[R^IPS(Y^∣P)]=U⋅I1u∑i∑EOu,i[Pu,iδu,i(Y,Y^)Ou,i]=U⋅I1u∑i∑δu,i(Y,Y^)=R(Y^).(4)不同于 R ^ naive ( Y ^ ) \hat{R}_{\text {naive }}(\hat{Y}) R^naive (Y^) ,IPS 估计器对任何概率分配机制都是无偏的。
R ^ I P S ( Y ^ ∣ P ) \hat{R}_{I P S}(\hat{Y} \mid P) R^IPS(Y^∣P)和 R ^ naive ( Y ^ ) \hat{R}_{\text {naive }}(\hat{Y}) R^naive (Y^)区别不仅仅是简单的消除权值, R ^ I P S ( Y ^ ∣ P ) \hat{R}_{I P S}(\hat{Y} \mid P) R^IPS(Y^∣P)针对的是整体,而 R ^ naive ( Y ^ ) \hat{R}_{\text {naive }}(\hat{Y}) R^naive (Y^)针对浏览过的项目。真正使用这个公式,必须知道全部项目 P ( O u , i = 1 ) P(O_{u,i}=1) P(Ou,i=1)的真实值。在实际的应用中,历史交互数据中只会记录部分评级数据,所以要利用某种拟合方法来推断(文章提出了朴素贝叶斯或逻辑回归)
详细证明Eq(4)其是一个无偏的估计:
E O [ R ^ I P S ( Y ^ ∣ P ) ] = 1 U ∗ I ∑ O P ( O ) ∑ u , i δ u , i ( Y , Y ^ ) P u , i O u , i = 1 U ∗ I ∑ u , i ∑ O P ( O ) δ u , i ( Y , Y ^ ) P u , i ) O u , i = 1 U ∗ I ∑ u , i [ ∑ O 11 ∑ O 12 … ∑ O u i … ∑ O U I P ( O 11 , O 12 , … , O u i , … , O U I ) ] δ u , i ( Y , Y ^ ) P u , i O u , i = 1 U ∗ I ∑ u , i P u , i δ u , i ( Y , Y ^ ) P u , i O u , i = 1 U ∗ I ∑ u ∑ i δ ( Y , Y ^ ) = R ( Y ^ ) \begin{aligned} E_{O}\left[\hat{R}_{I P S}(\hat{Y} \mid P)\right] &=\frac{1}{U * I} \sum_{O} P(O) \sum_{u, i} \frac{\delta_{u, i}(Y, \hat{Y})}{P_{u, i}} O_{u, i} \\ &\left.=\frac{1}{U * I} \sum_{u, i} \sum_{O} P(O) \frac{\delta_{u, i}(Y, \hat{Y})}{P_{u, i}}\right) O_{u, i} \\ &=\frac{1}{U * I} \sum_{u, i}\left[\sum_{O_{11}} \sum_{O_{12}} \ldots \sum_{O_{u i}} \ldots \sum_{O_{U I}} P\left(O_{11}, O_{12}, \ldots, O_{u i}, \ldots, O_{U I}\right)\right] \frac{\delta_{u, i}(Y, \hat{Y})}{P_{u, i}} O_{u, i} \\ &=\frac{1}{U * I} \sum_{u, i} P_{u, i} \frac{\delta_{u, i}(Y, \hat{Y})}{P_{u, i}} O_{u, i} \\ &=\frac{1}{U * I} \sum_{u} \sum_{i} \delta(Y, \hat{Y})=R(\hat{Y}) \end{aligned} EO[R^IPS(Y^∣P)]=U∗I1O∑P(O)u,i∑Pu,iδu,i(Y,Y^)Ou,i=U∗I1u,i∑O∑P(O)Pu,iδu,i(Y,Y^))Ou,i=U∗I1u,i∑[O11∑O12∑…Oui∑…OUI∑P(O11,O12,…,Oui,…,OUI)]Pu,iδu,i(Y,Y^)Ou,i=U∗I1u,i∑Pu,iPu,iδu,i(Y,Y^)Ou,i=U∗I1u∑i∑δ(Y,Y^)=R(Y^)
文章给出了IPS的误差界,IPS的缺点就是可变性太大(原文有详细证明)
3.4.2 SNIPS Estimator
为了减少可变性,通过使用控制变量。
通过IPS Estimator可以知道 E O [ ∑ ( u , i ) : O u , i = 1 1 P u , i ] = U ∗ I E_{O}\left[\sum_{(u, i): O_{u, i}=1} \frac{1}{P_{u, i}}\right]=U * I EO[∑(u,i):Ou,i=1Pu,i1]=U∗I,那么在IPS基础上可以得到SNIPS:
R ^ S N I P S ( Y ^ ∣ P ) = ∑ ( u , i ) : O u , i = 1 δ u , i ( Y , Y ^ ) P u , i ∑ ( u , i ) : O u , i = 1 1 P u , i \hat{R}_{S N I P S}(\hat{Y} \mid P)=\frac{\sum_{(u, i): O_{u, i}=1} \frac{\delta_{u, i}(Y, \hat{Y})}{P_{u, i}}}{\sum_{(u, i): O_{u, i}=1} \frac{1}{P_{u, i}}} R^SNIPS(Y^∣P)=∑(u,i):Ou,i=1Pu,i1∑(u,i):Ou,i=1Pu,iδu,i(Y,Y^)SNIPS估计量的方差(variance)通常比 IPS 估计量的方差小,但却有更小的偏差(bias)
3.5 实验验证
真实值 Y Y Y是已知的。只是为了证明该损失函数的优越性,所以预测值皆是模拟出来的,并不是由训练模型得到的。
作者设计了几种评分策略,每种策略都有不同的评分错误。基于真实数据集中的曝光情况,计算误差。

结论:IPS和SNIPS相对于Naive方法有更小的偏差,SNIPS能够降低MAE的IPS标准偏差,但不能降低DCG的IPS标准偏差。总的来说,IPS评价指标能有效抵消selection bias带来的评价误差。
4. IPS+推荐系统
将ERM应用在矩阵分解中,加入倾向性评分 P u , i P_{u,i} Pu,i,相当于加入权重,具体的定义方法见下节。最终模型训练的目标是:
argmin V , W , A [ ∑ O u , i = 1 δ u , i ( Y , V T W + A ) P u , i + λ ( ∥ V ∥ F 2 + ∥ W ∥ F 2 ) ] (5) \underset{V, W, A}{\operatorname{argmin}}\left[\sum_{O_{u, i}=1} \frac{\delta_{u, i}\left(Y, V^{T} W+A\right)}{P_{u, i}}+\lambda\left(\|V\|_{F}^{2}+\|W\|_{F}^{2}\right)\right] \tag{5} V,W,Aargmin⎣ ⎡Ou,i=1∑Pu,iδu,i(Y,VTW+A)+λ(∥V∥F2+∥W∥F2)⎦ ⎤(5)
5. 倾向性评分的估计
我们的目标估计 u s e r user user对 i t e m item item的倾向性概率 P u , i P_{u,i} Pu,i:
P u , i = P ( O u , i = 1 ∣ X , X h i d , Y ) (6) P_{u, i}=P\left(O_{u, i}=1 \mid X, X^{h i d}, Y\right) \tag{6} Pu,i=P(Ou,i=1∣X,Xhid,Y)(6)
倾向概率 P u , i P_{u,i} Pu,i受到可观测特征 X X X、不可观测特征 X h i d X^{hid} Xhid和评分 Y Y Y的影响。
5.1 朴素贝叶斯
P ( O u , i = 1 ∣ Y u , i = r ) = P ( Y = r ∣ O = 1 ) P ( O = 1 ) P ( Y = r ) (7) P\left(O_{u, i}=1 \mid Y_{u, i}=r\right) = \frac{P(Y=r \mid O=1) P(O=1)}{P(Y=r)} \tag{7} P(Ou,i=1∣Yu,i=r)=P(Y=r)P(Y=r∣O=1)P(O=1)(7)
其中, P ( Y = r ∣ O = 1 ) P(Y=r \mid O=1) P(Y=r∣O=1)和 P ( O = 1 ) P(O=1) P(O=1)是由已有的历史交互数据得到的, P ( Y = r ) P(Y=r) P(Y=r)是从一个MCAR数据集获取的。
这种方法必须要确保有部分可用的MCAR数据。并且它只能拟合出被评分item的浏览概率,不能直接把结果拿来做推荐的,但是只要把其余的评分补全即可,例如可以结合使用矩阵分解MF来预测其余项目的评分。
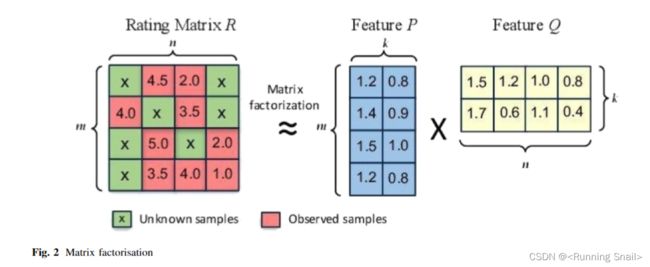
拟合 P u , i P_{u,i} Pu,i的无偏评级就是上图的红色格子,未拟合出权重的项目评级就是上图的绿色鸽子。
矩阵分解 Y ^ u , i = v u T w i + a u + b i + c \hat{Y}_{u, i}=v_{u}^{T} w_{i}+a_{u}+b_{i}+c Y^u,i=vuTwi+au+bi+c,其中 v u , w i v_u,w_i vu,wi分别是user和item的隐特征矩阵, a , b , c a,b,c a,b,c分别是user、item和全局偏置项,此时MF的损失函数为:
argmin V , W , A [ ∑ O u , i = 1 δ u , i ( Y , V T W + A ) P u , i + λ ( ∥ V ∥ F 2 + ∥ W ∥ F 2 ) ] \underset{V, W, A}{\operatorname{argmin}}\left[\sum_{O_{u, i}=1} \frac{\delta_{u, i}\left(Y, V^{T} W+A\right)}{P_{u, i}}+\lambda\left(\|V\|_{F}^{2}+\|W\|_{F}^{2}\right)\right] V,W,Aargmin⎣ ⎡Ou,i=1∑Pu,iδu,i(Y,VTW+A)+λ(∥V∥F2+∥W∥F2)⎦ ⎤其中, V , W V,W V,W分别是user和item的隐向量, A A A是偏置项
之前不能通过朴素贝叶斯直接拟合的倾向性评分,通过 Y ^ = V T W + A \hat{Y}=V^{T} W+A Y^=VTW+A就能计算得到了。
总体来说,通过朴素贝叶斯进行倾向估计是相对简单易实现的方法。
5.2 逻辑回归
目标是寻找模型参数 ϕ \phi ϕ独立于不可观测特征 X h i d X^{hid} Xhid和评分 Y Y Y,比如 P ( O u , i = 1 ∣ X , X h i d , Y ) = P ( O u , i ∣ X , ϕ ) P\left(O_{u, i}=1 \mid X, X^{h i d}, Y\right)=P\left(O_{u, i} \mid X, \phi\right) P(Ou,i=1∣X,Xhid,Y)=P(Ou,i∣X,ϕ)
将所有关于u-i的信息都作为特征,来学习一个线性模型:
P u , i = σ ( w T X u , i + β i + γ u ) (8) P_{u, i}=\sigma\left(w^{T} X_{u, i}+\beta_{i}+\gamma_{u}\right) \tag{8} Pu,i=σ(wTXu,i+βi+γu)(8)
其中, σ ( ⋅ ) \sigma(\cdot) σ(⋅)是Sigmoid函数, X u , i X_{u,i} Xu,i是user-item对的特征, ϕ = ( w , β , γ ) \phi=(w, \beta, \gamma) ϕ=(w,β,γ)表示参数集合, w w w是权重参数, β , γ \beta, \gamma β,γ分别是item和user的偏移量。
这种方法不需要筛选出一个MCAR数据集,就可以拟合所有项目的浏览概率。
6. 实验
训练集是有偏(MNAR)数据,使用k-折交叉验证来调参,使用无偏数据或者合成的全曝光数据作为测试集。
采样偏差对评测指标的影响
(上文提到的实验)
**构建全曝光的合成数据集:**在ML 100K数据集上,使用MF 填充所有空缺的评分,并对填充之后的评分分布进行调整,以降低高评分的比例。
采样偏差对模型训练的影响
对于不同程度的选择偏差(α越小,选择偏差越大),IPS-MF和SNIPS-MF的性能要明显优于naive-MF:

倾向性评分估计准确度的影响
使用不同比例的数据来估计倾向性评分,可以看出,在所有条件下,IPS和SNIPS都优于MF,验证了模型对倾向性评分的鲁棒性。

真实数据集上的表现
Yahoo! R3:使用5%的无偏数据来估计倾向性评分,95%的无偏数据作为测试集。
Coat:本文收集了一个新的无偏数据集Coat(很大的贡献),包含290个user和300个item,每个user自主选择24个商品给出评分,并对16个随机商品给出评分(1-5分)。
实验结果表明,IPS-MF在两个数据集上都优于的baseline。

参考文章:
- ICML2016-IPS 利用逆倾向评分降低推荐算法的偏差 - 知乎 (zhihu.com)
- 逆向倾向评分 (Inverse Propensity Scoring, IPS) 原理解析与MF算法的结合使用_白水baishui的博客
- 【论文笔记】Recommendations as Treatments: Debiasing Learning and Evaluation - 子豪君 - 博客园 (cnblogs.com)