【计算机视觉】论文笔记-FCOS: Fully Convolutional One-Stage Object Detection
文章目录
-
- 前言
- 前提知识
-
- 1.CNN与FCN:
- 2.FCOS:该算法是一种基于FCN的逐像素目标检测算法,
- 3.H×W×C
- 4.COCO数据集
- 5.ground truth box
- 6.FPN结构:特征金字塔网络
- 方法改进-FPN对FCOS的多层次预测
- FCOS会产生大量偏离目标中心的边界框
前言
此论文笔记为本人课堂小组展示,特此记录部分内容
前提知识
1.CNN与FCN:
CNN:卷积神经网络
FCN:全卷积网络
通常cnn网络在卷积之后会接上若干个全连接层,将卷积层产生的特征图(feature map)映射成为一个固定长度的特征向量。一般的CNN结构适用于图像级别的分类和回归任务,因为它们最后都期望得到输入图像的分类的概率,
FCN对图像进行像素级的分类,从而解决了语义级别的图像分割问题。与经典的CNN在卷积层使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷基层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后奇偶在上采样的特征图进行像素的分类。
全卷积网络(FCN)是从抽象的特征中恢复出每个像素所属的类别。即从图像级别的分类进一步延伸到像素级别的分类。
简单的说,FCN与CNN的区别在于FCN把CNN最后的全连接层换成卷积层,输出一张已经label好的图。
2.FCOS:该算法是一种基于FCN的逐像素目标检测算法,
实现了无锚点,无提议的解决方案,并且提出了中心度的思想
通过逐像素预测的方式重新定义目标检测
c(i)是边界框中的对象所属的类,c为类数,对于MS-COCO数据集为80
基于锚点的检测器将输入图像上的位置视为(多个)锚点框的中心,并以这些锚点框为参考来回归目标边界框;我们直接在该位置回归目标边界框。换句话说,我们的检测器直接将位置视为训练样本,而不是基于锚的检测器中的锚盒。
IOU:‘预测的边框’和‘真实的边框’的交集和并集的比值
因此,FCOS可以利用尽可能多的前景样本来训练回归器
3.H×W×C
对于一张彩色数字图片,我们通常会将它表成一个H×W×C的3维矩阵。其中,H表示图片的宽,W表示图片的高,C表示图片的通道数。H×W描述的就是图片的分辨率,也就是像素点的个数。对于每一个像素点,都会表示一个颜色,用一个C维的向量描述。
4.COCO数据集
COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。COCO数据集的80个类别—YoloV3算法采用的数据集
5.ground truth box
ground truth box可以理解为标准答案,真实值,正确的标签
6.FPN结构:特征金字塔网络
目标检测任务里面常常需要检测小目标,但是小目标比较小,可能在原图里面只有几十个像素点。
对于深度卷积网络,从一个特征层卷积到另一个特征层,无论步长是1还是2还是更多,卷积核都要遍布整个图片进行卷积,大的目标所占的像素点比小目多,所以大的目标被经过卷积核的次数远比小的目标多,所以在下一个特征层里,会更多的反应大目标的特点。
特别是在步长大于等于2的情况下,大目标的特点更容易得到保留,小目标的特征点容易被跳过。
总共利用下采样进行长宽的收缩。利用上采样进行长宽的扩张,在每次扩张之后,再与对应的下采样特征层进行合并堆叠,最后获得目标检测结果!
方法改进-FPN对FCOS的多层次预测
在前面所讲的可以知道,我们提出的FCOS可能会导致两个问题:会产生模糊样本和产生大量偏离目标中心的边界框。模糊样本:如果一个位置在多个ground truth box内,则它视为模糊样本。
为了处理ground-truth重合,无法准确判断像素所属类别,我们引入了FPN结构,可以将不同的目标框分散到不同的层中进行预测,这样就很大程度上减少了重叠的发生。
根据FPN,我们在不同层次的特征地图上进行不同尺度的目标检测。具体来说,我们使用五个层的特征映射{P3,P4,P5,P6,P7}。P3、P4和P5是由主干网的特征映射C3、C4和C5后接1*1的卷积得到的,P6和P7是通过分别在P5和P6上设置一个步长为2并增加卷积层得到的。最终,P3、P4、P5、P6和P7的步长为8、16、32、64和128。
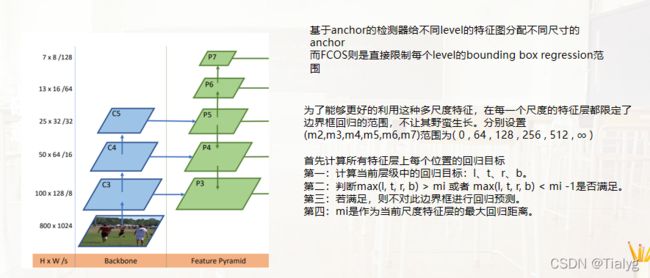
基于anchor的检测器给不同level的特征图分配不同尺寸的anchor,而FCOS则是直接限制每个level的bounding box regression(回归)范围。
本文为了能够更好的利用这种多尺度特征,在每一个尺度的特征层都限定了边界框回归的范围,不让其野蛮生长。分别设置(m2,m3,m4,m5,m6,m7)范围为( 0 , 64 , 128 , 256 , 512 , ∞ )
如果一个位置满足 第二个条件 那么它就会被设置为负样本,并且不再需要回归边框了。也就是说,第i层特征图F i 其回归的距离范围为( m i − 1 , m i )
由于具有不同尺寸的对象被分配到不同的特征级别,并且大多数重叠发生在具有相当不同尺寸的对象之间。如果一个位置,即使使用了多级预测,仍然被分配给多个ground truth框,我们只需选择面积最小的ground truth框作为目标。
实验表明,因此多尺度预测可以在很大程度上缓解目标框重叠情况下的预测性能。
FCOS会产生大量偏离目标中心的边界框
多尺度预测的问题后,仍存在另一个问题:实验表明FCOS会产生大量偏离目标中心的边界框
center-ness描绘了从该位置到该位置负责的对象中心的归一化距离。
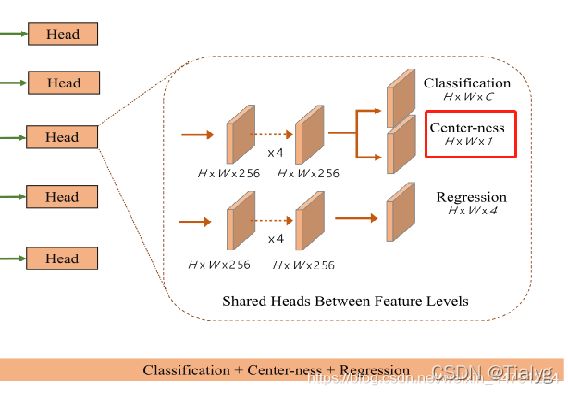
一个简单而有效的策略来抑制这些低质量的检测边界框,而不引入任何超参数。在最后的分类head中,添加了一个单层分支,与分类分支并行(如图所示),以预测某一位置点的“center-ness”。

这里使用根号来减缓center-ness的衰退。center-ness范围从0到1
Center-ness衡量当前像素偏离真实目标中心点的程度,值越小,偏离越大
热力图3-Center-ness。红色(1)、蓝色(0)和其他颜色分别表示1,0和它们之间的值。中心度由式(3)计算,当位置偏离物体中心时,中心度从1衰减到0。
在测试时,通过将预测的center-ness与相应的分类分数相乘来计算最终分数(用于对检测到的边界框进行排序)。因此,center-ness可以降低远离对象中心的边界框的分数。
这些低质量的预测边界盒很有可能被最终的非最大抑制(NMS)过程过滤掉,从而显著提高检测性能。
非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,可以理解为局部最大搜索
我们的目的就是要去除冗余的检测框,保留最好的一个。